
传统的语音识别系统,是由声学模型、词典、语言模型构成的,而其中的语音模型和语言模型是分别训练的,而不同的语言也有不同的语言模型,比如英语和中文。
最近崛起的端到端的语音识别系统,从语音特征(输入端)到文字串(输出端)中间就只有一个神经网络模型,成为
语音识别领域
新的研究热点。
硅谷密探独家专访了Baidu Silicon Valley AI Lab总监Adam Coates,探讨了语音和语音识别的新动向。

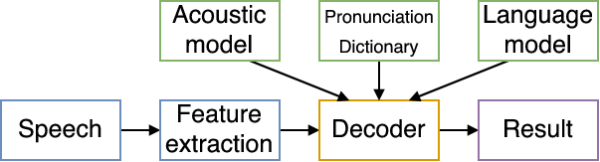
传统的语音识别系统
(来源:wiki)
传统的语音识别需要把语音转换成语音特征向量,然后把这组向量通过机器学习,分类到各种音节上(根据语言模型),然后通过音节,还原出最大概率的语音原本要表达的单词,一般包括以下模块:
特征提取模块 (Feature Extraction)
:该模块的主要任务是从输入信号中提取特征,供声学模型处理。一般也包括了一些信号处理技术,尽可能降低环境噪声、说话人等因素对特征造成的影响,把语音变成向量。
声学模型 (Acoustic Model):
用于识别语音向量
发音词典 (Pronnuciation Dictionary):
发音词典包含系统所能处理的词汇集及其发音。发音词典提供了声学模型与语言模型间的联系。
语言模型 (Language Model):
语言模型对系统所针对的语言进行建模。
解码器 (Decoder):
任务是对输入的信号,根据声学、语言模型及词典,寻找能够以最大概率输出该信号的词串。
传统的语音识别
中的语音模型和语言模型是分别训练的,缺点是不一定能够总体上提高识别率。
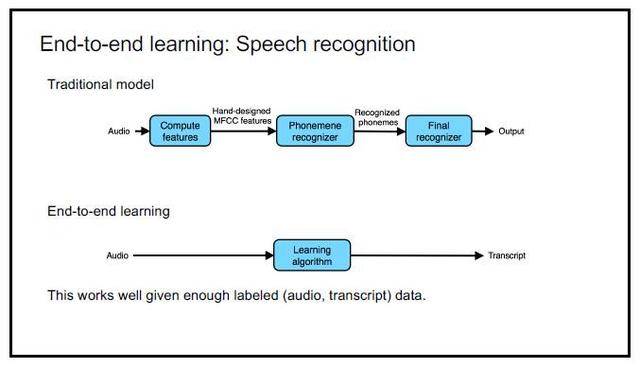
端到端的语音识别系统
(来源:吴恩达NIPS 2016演讲)
端到端学习的思路则非常简单:音频→学习算法→转录结果;
而现在,我们可以直接通过深度学习将语音直接对标到我们最终显示出来的文本。通过深度学习自己的特征学习功能来完成从特征提取到音节表达的整个过程。
在给定了足够的有标注的训练数据时(语音数据以及对应的文本数据),端到端的语音识别方法的效果会很好。
Deep Speech 2
Baidu Silicon Valley AI Lab研发了端到端的能够识别英文的语音识别系统Deep Speech,之后在此基础上研发了能识别中英文的Deep Speech 2,Deep Speech 2通过使用一个单一的学习算法就能准确识别英语和汉语。

Deep Speech 2这个大规模的深度学习系统需要丰富的标记训练数据。为训练英语模式,这个系统使用了11940小时含800万标注的语音片段,而普通话系统采用了9400小时含1100万话语标记的讲话语音。
Deep Speech 2这种端到终的深度学习,可以利用数据和计算的增加不断改善语音识别系统。由于该方法是高度通用的,它可以迅速地应用于新的语言。
Deep Speech 2能够识别方言
Deep Speech 2最早是用英语训练的,最早只能够识别英语,但由于Deep Speech 2是端到端的训练模式,Adam在硅谷密探的采访中表示,在这个系统建立之后,只需要用中文训练数据替代英文训练数据,在经过训练之后就有了强大的中文识别引擎,就能够很好的识别中文。
同样的道理,只要给Deep Speech 2足够多的方言训练数据,比如粤语,那么Deep Speech 2理论上也能够很好的识别粤语。
能解决中英混合问题
中英混合一度是一个很头疼的问题,在我们使用Siri的时候,必须要选好一个语言,如果设置成了中文就识别不了英文。
但在我们日常生活中,由于专业术语或者品牌名等原因,有时不得不中英混合。基于同样的原因,Deep Speech 2也能很好的解决中英混合这个问题,只要我们训练的数据里同样是中英夹杂。










