- 点击上方“中国统计网”订阅我吧!-

01 前言
Python链接数据库的方式有几种,但是原理都是一样的,总共可以分为两个步骤,第一步是与数据库建立链接,第二步执行sql查询语句,这篇将分别介绍如何与数据库链接以及如何进行sql语句查询。
02 与数据库进行链接
在与数据库进行链接时,主要用到两种方法,一种是pymysql.connect,另一种是create_engine。
pymysql是python自带的一个库,使用前需要使用pip install pymysql安装这个库,安装完以后使用该库中的connect方法可以直接与数据库进行链接。
# 方法一: 使用pymsql.connect方法import pymysql
# Connect to the databaseeng = pymysql.connect(host='localhost',user='user',password='passwd',db='db',charset='utf8')# user:用户名# password:密码# host:数据库地址/本机使用localhost# db:数据库名# charset:数据库编码
# 连接sample# charset='utf8'是解决中文乱码eng=pymysql.connect(host="118.190.xxx.xxx",user="zhangjian",password="ZhangJian",db="demo",charset='utf8')
这样就将python与数据库进行了链接,接下来执行sql查询语句就可以将数据库中的内容读取到python中。
create_engine是sqlarchemy包内的一个模块,而sqlarchemy是Python下的一款ORM框架,建立在数据库API之上,使用关系对象映射进行数据库操作,将对象转换成SQL,使用数据库API执行SQL并获取执行结果。
ORM是Object Relational Mapper ,是一种对象映射关系程序,比较难解释,大家有兴趣的自己去了解一下,这里只分享如何使用这个进行链接。
# 方法二: 使用create_engine方法from sqlarchemy import create_engine
create_engine("mysql+pymysql://:@/[?]")# mysql:数据库类型# pymysql:驱动器类型# username:用户名# password:密码# host:数据库地址/本机使用localhost# dbname:数据库名# options:数据库编码格式如:charset=utf8
# 连接sampleeng = create_engine("mysql+pymysql://zhangjian:[email protected]:3306/demo?charset=utf8")
03 执行sql语句
# 方法一:使用pd.read_sql() 主要参数如下所示pd.read_sql(sql, con, index_col = None, columns = None )
# 方法二:使用pd.read_sql_query 主要参数如下所示pd.read_sql(sql, con, index_col = None, columns = None )
# 方法三:使用pd.read_sql_table 主要参数如下所示pd.read_sql(table, con, index_col = None, columns = None )# 从以上方法可看出,read_sql()方法已经打包了read_sql_table() 与 read_sql_query()的所有功能,推荐直接使用read_sql()方法
pd.read_sql()方法读取数据文件
import pandas as pd from sqlalchemy import create_engineeng = create_engine("mysql+pymysql://zhangjian:ZhangJian*[email protected]:3306/demo?charset=gbk") data = pd.read_sql(sql = 'select * from orderitem limit 10',con=eng,index_col='SDate')data# 输入正确的数据库新信息后,read_sql方法返回的是我们熟悉的数据框结构,可以方便浏览数据,如需查看汇总信息,修改sql语句即可。
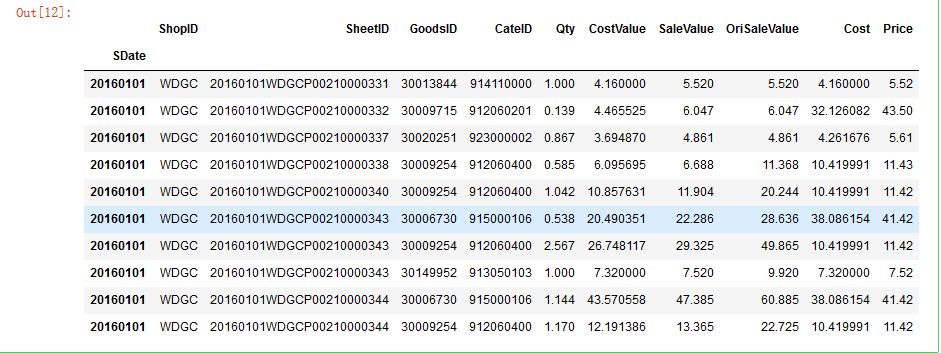
▲(点击可查看大图)
# read_sql()方法sql参数使用表名称from sqlalchemy import create_engineimport pandas as pdeng = create_engine("mysql+pymysql://zhangjian:ZhangJian*[email protected]:3306/demo?charset=gbk") data = pd.read_sql(sql = "category",con=eng)
# 此方法会读取指定表中的全部数据,如果表数据量比较大,会造成读取数据慢,慎用。
# 修改改数据库密码后重新连接数据库# 如用户名,密码,数据库名称包含% @等特殊字符串报错如下所示:报错关键信息1045eng = create_engine("mysql+pymysql://账号:密码@118.190.000.111:3306/demo?charset=gbk") data = pd.read_sql(sql = 'select * from orderitem limit 10',con=eng)dataOperationalError Traceback (most recent call last)
C:\ProgramData\Anaconda3\lib\site-packages\sqlalchemy\engine\base.py in _wrap_pool_connect(self, fn, connection) 2157 try:-> 2158 return fn() 2159 except dialect.dbapi.Error as e:

▲(点击可查看大图)
import pymysqleng = pymysql.connect("118.190.000.111","zhangjian","zhangjiang*2018","demo" )data = pd.read_sql(sql = "select * from orderitem limit 10" ,con=eng)data
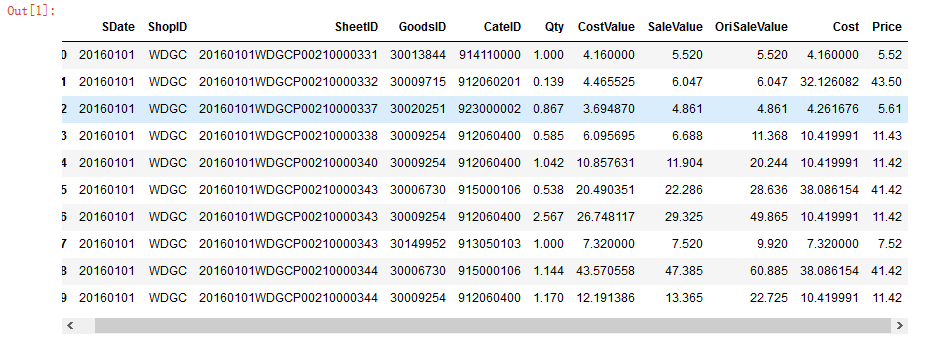
▲(点击可查看大图)
# pymsql.connect连接,读入指定表名称,会报错,关键信息1064eng=pymysql.connect(host="118.190.000.111",user="zhagnjian",password="zhangjian*2018",db="demo" ,charset='utf8')data = pd.read_sql(sql = "category",con=eng)data
▲(点击可查看大图)
使用connection.cursor()方法读取数据库文件import pymysqleng = pymysql.connect("118.190.000.111","zhangjian","ZhangJian*2018","demo" )cursor = eng.cursor()sql = """select * from orderitem limit 10;"""cursor.execute(sql)data = cursor.fetchall()eng.close()data

▲(点击可查看大图)
# 将元组转化为DataFramedf2 = pd.DataFrame(data = list(data) ,columns = ['SDate', 'ShopID', 'SheetID', 'GoodsID','CateID', 'Qty', 'CostValue','SaleValue', 'OriSaleValue', 'Cost', 'Price'] )df2
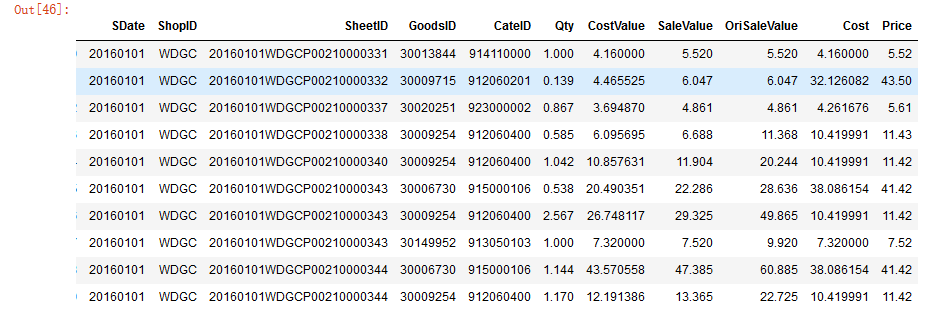
04 读入数据库文件方法总结
使用create_engine方法能够满足绝大部分数据库连接与操作命令;
数据库连接信息包含特殊字符串,需要使用mysql.connect()作为连接方法;
pd.read_sql()方法读入数据库文件,返回数据框结构,可以快速浏览数据汇总;
pd.read_sql()使用con参数使用pymsql.connect()方法,sql参数不能直接使用表名称,需要使用完整的sql语句;
使用 cursor() 方法创建游标的方法读取sql语句,返回的是包含列信息的元组,
综上所述,在pandas框架下使用create_engine 加read_sql()方法,读取数据库文件,代码简洁,易懂,返回的是据框;此方法可避免了数据库连接工具与python间的切换时间,有利于提高工作效率。
End.






