
数据挖掘入门与实战 公众号: datadw
目的和意义
很难有机会接触这么多的实际真实数据。
通过对于这些数据的分析,初步了解大数据的处理方式。
进一步掌握MongoDB的特性,熟练Excel的高级用法。
这里只是做分析,不提供源代码,毕竟是一个比赛。
这里只是做分析,不提供源代码,我也无意开发一个完整的程序。
题目分析
http://research.xiaojukeji.com/competition/detail.action?competitionId=DiTech2016
构建一个模型,根据天气,交通,区域里面的各种设施,以往历史数据,预测未来的某个时间点,某个区域里,打车需求的缺口。整个算法其实就是一个有监督的机器学习的过程。
数据整理
(5月20日版本)下载后的整个压缩数据包575M,其中包括的订单数据大约900万条。(其他Master表数据量很小,这里忽略不计)
使用MongoDB存储的话,大概使用2GB的空间,全部导入之后,工作用计算机十分卡顿。MongoCola管理软件失去响应。所以,这里的订单按照日期导入。(训练的时候,按照天来训练)
注意:官方的订单数据的 订单号 OrderID是主键重复的。这里以第一次出现的订单号的数据为准。
官方对于重复订单的解释:
Q: 在order info 中重复出现的数据应如何处理?
A: 数据重复是因为同一个用户可能在一个10分钟片同一个地区发单被多次应答,但是这样的情况并不多,影响并不大。为了简化问题,重复的订单不需要去重,直接计入到缺口的计算中。
关于订单的目标区域HashCode,这里发现一部分数据是无法找到的,可能是跨区域的。
(全部订单:498789 ,目的地可以找到:406138,跨区域:92651)
由于数据量非常庞大,所以这里建议将中间的计算结果也放入数据库中备用。
订单数据整理
订单数据整理,主要是整理出各个时段,各个地域的订单数据。
数据整理尽量使用LINQ进行处理,MONGODB查询是消耗时间的!!!,这里数据库只是用作数据的存储不做计算
private void btnImportDB_Click(object sender, EventArgs e)
{
string rootFolder = txtRootDir.Text;
//Order: Root + "\order_data"
foreach (var filename in Directory.GetFiles(rootFolder + "\\order_data"))
{
if (!filename.Contains("._"))
{
string strDate = filename.Substring(filename.LastIndexOf("_") + 1);
var colname = "Order_" + strDate;
Database.Clear(colname);
var orderlist = new ListOrder>();
var read = new StreamReader(filename);
while (!read.EndOfStream)
{
var o = Order.Gernerate(read.ReadLine());
orderlist.Add(o);
}
orderlist = orderlist.Distinct(x => x.order_id).ToList();
Database.InsertRecBatch(orderlist, colname);
var orderGaplist = new ListOrderGap>();
Database.Clear("OrderGap_" + strDate);
for (int time = 1; time 144 + 1; time++)
{
for (int area = 1; area 66 + 1; area++)
{
var m = new OrderGap() { DistrictId = area,TimeSlient = time};
m.Total = orderlist.Count((x) => { return x.DistrictID == area && x.TimeSlient == time; });
m.Gap = orderlist.Count((x) => { return x.DistrictID == area && x.TimeSlient == time && x.driver_id == "NULL" ; });
m.GapPercent = m.Total == 0 ? 0 : Math.Round(((double)m.Gap / m.Total) * 100, 2);
orderGaplist.Add(m);
}
}
Database.InsertRecBatch(orderGaplist, "OrderGap_" + strDate);
//暂时只分析一天数据
break;
}
}
}
利用Excel,可视化数据
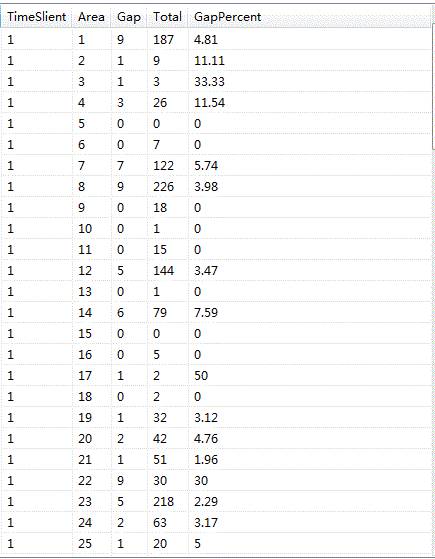
2016-01-01 分时图
以下是2016-01-01的数据分析。蓝色的是GAP缺口数,红色的是Total数。
一天24个小时整体需求分布可以看个大概了。
PS 区域1 :占整体的5.1%订单量,有一定的参考价值
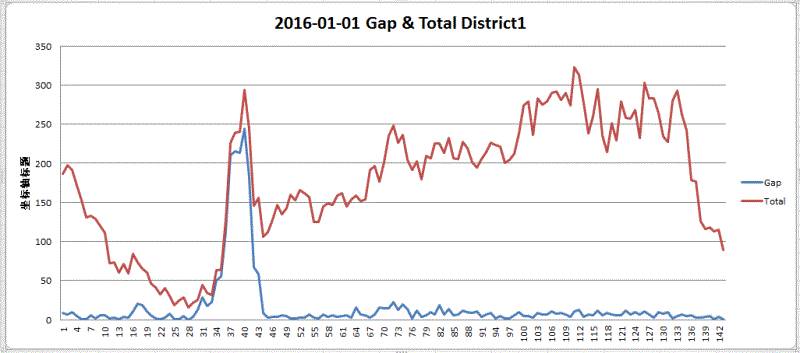
区域51 :占整体的22.5%订单量,有一定的参考价值
整体上看,所有区域的分时图 2016-01-01的数据图:
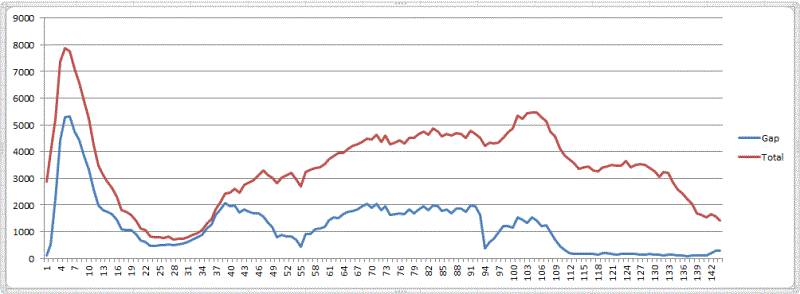
这里看到,整个24小时分布极不均衡。考虑到 01-01 是一个特殊的日子,大家为了跨年而在零点之后选择打车也是可以理解的。
2016-01-02 分时图
同样的51区域,2016-01-02的情况则比较正常,整体的高峰出现在夜间16:50 - 17:20(评价订单850) 左右。21:10,22:00也是两个小高峰(平均订单720)。
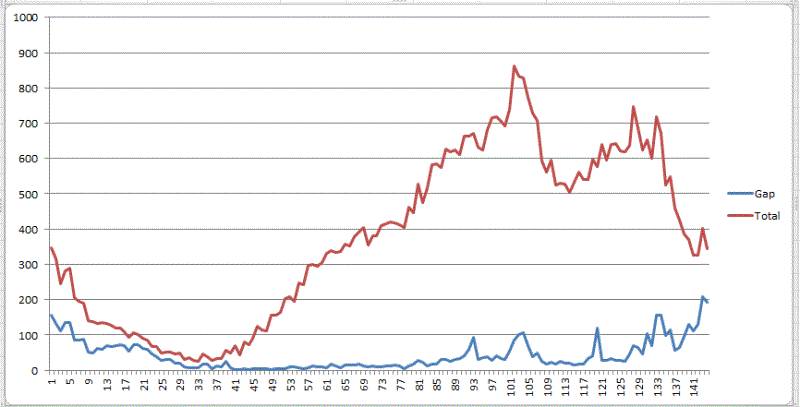
各项指标分析
起始区域差距
以下数据为2016-01-01的数据统计
整体有效订单数:498789(订单ID去重复)
66个区域的订单分布是极其不均衡的.
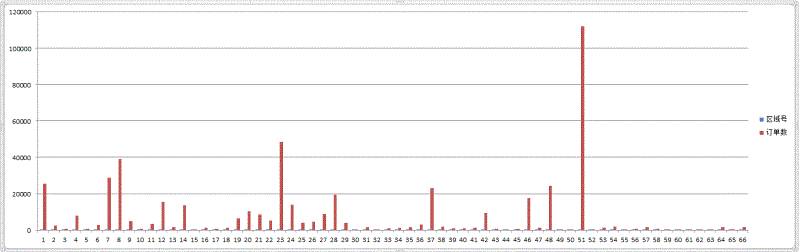
排名后33位的,总共只有整体的4.37%的订单
排名前5位的,总共只有整体的50.87%的订单
起始区域POI整体数目和订单数关系
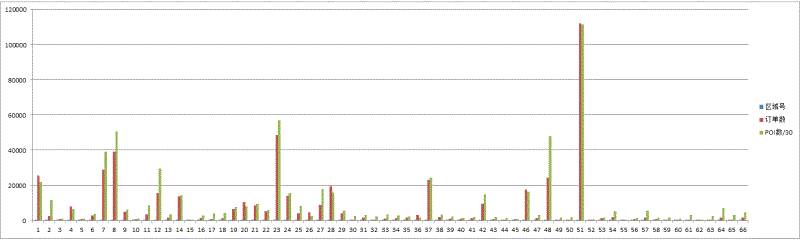
我们将POI总数/30 和订单数一起放到柱状图中发现,POI总数和订单数应该有一些联系。
一个区域POI数越多说明这个地区越是繁华,从这里打车的需求就越多。
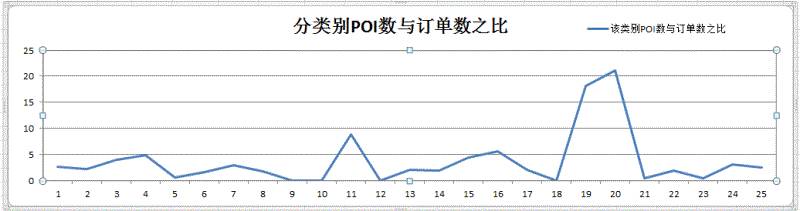
POI子项目和订单关系
滴滴打车的POI分为了25个分类,我们选取了 2016-01-01 对于POI的分类和订单之间的关系也作了研究。
按照实际来说,例如有100家KTV,则每家KTV为贡献一些订单。同理,如果是饭店,每家饭店也会贡献一些订单。
这里的图表示了各个POI分类的数量和总体订单的关系。
如果有0100家N类POI,整体订单是100,则比率是01。
如果有1000家N类POI,整体订单是100,则比率是10,
如果有0010家N类POI,整体订单是100,则比率是0.1。
这个比率越小表示该POI分类对于可能对于整体贡献越大。当然,如果该分类表示一些极为特殊的设施,例如市政府,则不在考虑之内。
所以这里需要过滤掉POI数量过小的情况。
(注意:这里为0的意思是没有该类别的POI。分子为0)
Q:为什么在POI信息表中有的类别没有用#区分?
A:不是所有设施级关系都是a#b:xx的格式,有的设施只有一级,而有的设施甚至有三级,#号只是表示分割层级的关系,如果是设施只有一级则为a:xx,而如果是2级则是a#b:xx,如果是3级则是a#b#c:xx,依次类推。
Q: 关于POI数据的分类一共分多少1级类目,多少2级类目,且是否有类目示意的对照表?
A: 这个问题的答案都在数据中,参赛者可以自行统计。类目对应信息其实不是很重要,重要的是分析其和目标的关联程度。
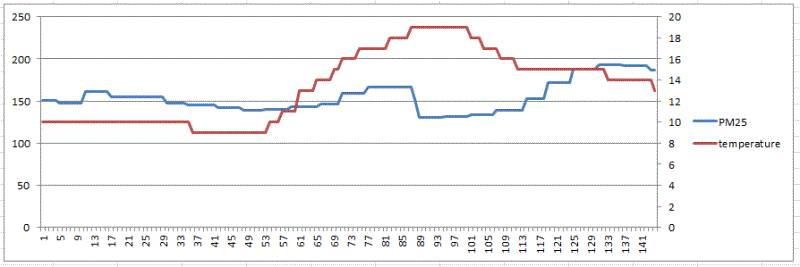
天气和订单的关系
天气数据库是里面的数据分为PM2.5的值。天气状态编码(编码和实际对应关系未知),以及温度情况。
按照道理来说,如果天气越差,则打车的需求就越旺盛。
下面我们来分析一下天气和订单的关系。
选择 2016-01-03作为分析对象。
天气数据每个时间片测试两次,为了方便观察,我们选择第一次测试结果作为考察对象。
当天全时段的PM2.5和温度分时图
天气类型编号和天气描述,请参见 滴滴算法大赛算法解决过程 - 机器学习
当天的全区域的订单情况分时图
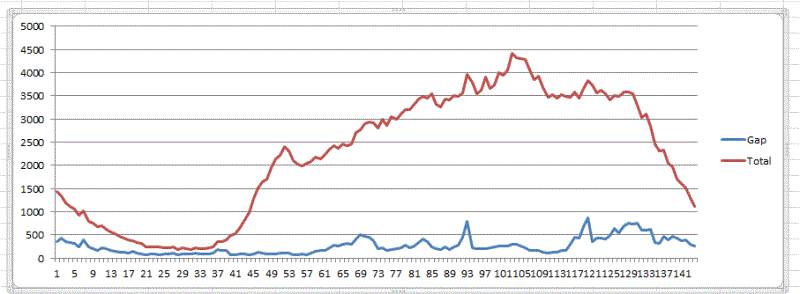
从一天的时间看,在不明确天气类型的时候,PM2.5和温度对于整体的影响很难看到直接关联的证据。
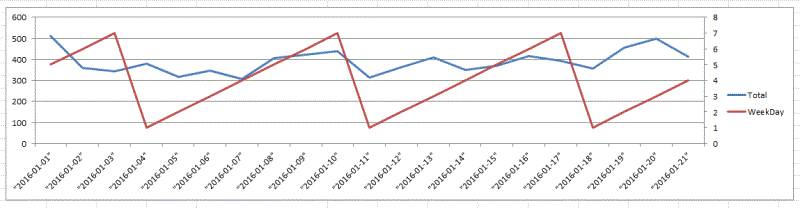
关于WeekDay
我们考察最繁华的51区域,周一到周日对于订单量的关系。
这里观察到并没有什么规律可循
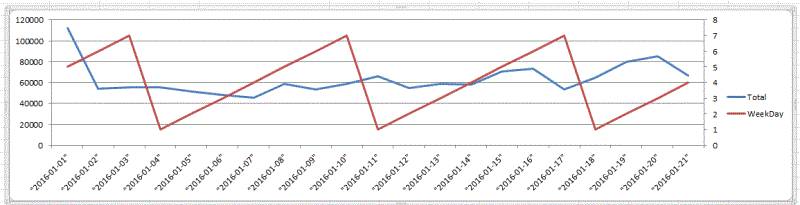
第05区域也是这样的。
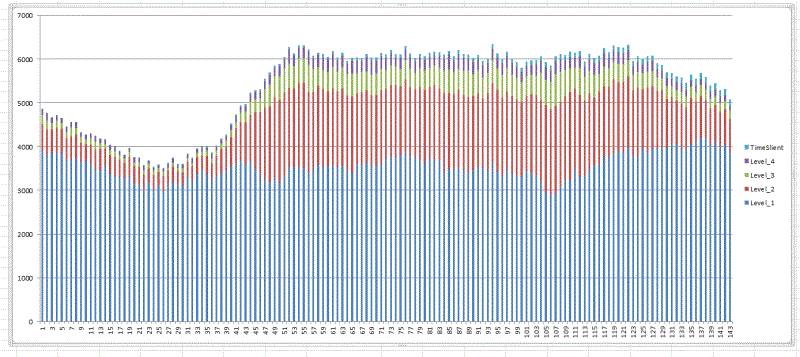
交通和订单的关系
这里的交通数据是每个区域里面,不同拥挤状况的道路条数。
2016-01-07 #51 区域分时拥堵状态图 (0:10 -23:50 143个数据)
大部分情况下,Level1的道路条数占据了绝大多数。(LV4最拥堵)
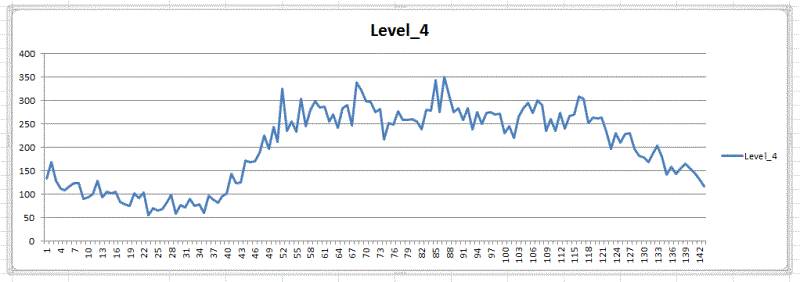
看一下Level4 #51区域的情况
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注










