23年6月来自北大、上海AI实验室和UCSB的综述论文“A Survey on In-context Learning“。
随着大语言模型(LLM)能力的提高,上下文学习(ICL)已成为自然语言处理(NLP)的一种新范式,其中LLM仅基于添加了几个例子的上下文进行预测。
探索ICL来评估和推断LLM的能力已经成为一种新的趋势。
本文旨在调查和总结ICL的进展和挑战。
首先是ICL的定义,并阐明相关研究的关联。
然后,对高级技术进行了组织和讨论,包括训练策略、演示设计策略以及相关分析。
最后讨论了ICL的挑战,并提供了潜在的方向。
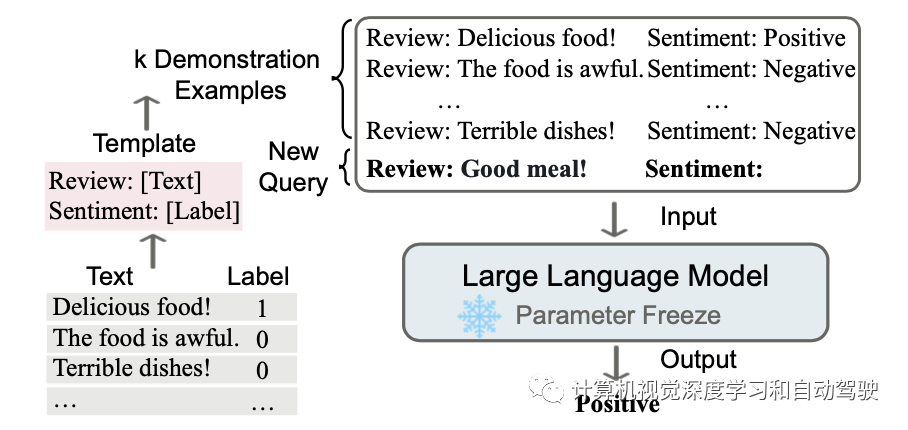
如图是上下文学习的说明。ICL需要一段演示上下文,其中包含一些用自然语言模板编写的示例。以演示和查询为输入,大语言模型负责进行预测。
 如图是该综述的分类架构:
训练和推理阶段是ICL的两个主要阶段;
在训练阶段,现有的ICL研究主要以预训练的LLM为骨干,并选择性地对模型进行预热,增强和推广ICL能力;
在推理阶段,演示设计和评分函数的选择对最终性能至关重要。
如图是该综述的分类架构:
训练和推理阶段是ICL的两个主要阶段;
在训练阶段,现有的ICL研究主要以预训练的LLM为骨干,并选择性地对模型进行预热,增强和推广ICL能力;
在推理阶段,演示设计和评分函数的选择对最终性能至关重要。
 尽管LLM已经显示出有希望的ICL能力,不过通过预训练和ICL推理之间的连续训练阶段,ICL能力可以进一步提高,简称之为模型预热。
模型预热是ICL的一个可选过程,在ICL推理之前调整LLM,包括修改LLM的参数或添加附加参数。
与微调不同,预热的目的不是为特定任务训练LLM,而是增强模型的整体ICL能力。
尽管LLM已经显示出有希望的ICL能力,不过通过预训练和ICL推理之间的连续训练阶段,ICL能力可以进一步提高,简称之为模型预热。
模型预热是ICL的一个可选过程,在ICL推理之前调整LLM,包括修改LLM的参数或添加附加参数。
与微调不同,预热的目的不是为特定任务训练LLM,而是增强模型的整体ICL能力。
几点总结:(1)监督训练和自监督训练都建议在 ICL 推理之前对 LLM 进行训练。其关键思想是通过引入接近上下文学习的目标来弥合预训练和下游 ICL 格式之间的差距。与涉及演示的
上下文微调
相比,没有几个例子作为演示的
指令微调
更简单,也更受欢迎。(2)在某种程度上,这些方法都通过更新模型参数来提高 ICL 能力,这意味着原始 LLM 的 ICL 能力具有很大的提升潜力。因此,虽然 ICL 并不严格要求模型预热,但在 ICL 推理之前添加一个预热阶段。(3)随着训练数据的不断扩大,预热带来的性能提升会遇到瓶颈。这种现象在监督上下文训练和自监督上下文训练中都出现,表明 LLM 只需要少量数据就可以在预热期间适应从上下文中学习。
ICL的性能在很大程度上依赖于演示,包括演示格式、演示示例的顺序等(Zhao2021;Lu 2022)。演示设计策略可分为两组:演示组织和演示格式。下表是代表性演示设计方法:
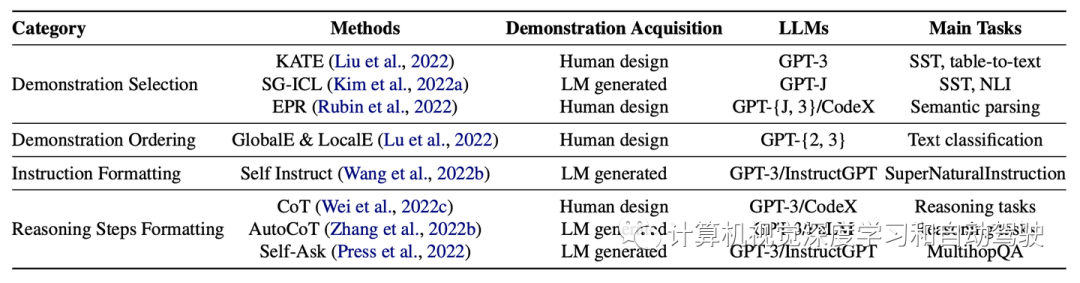
给定一组训练示例,演示组织将重点放在如何选择示例子集和所选示例的顺序上。
演示格式的一种常见方法是,用一个模板T直接连接示例(x1,y1),...,(xk,yk)。
然而,在一些需要复杂推理的任务中(例如,数学单词问题、常识推理),仅用k个演示不容易学习从xi到yi的映射。
尽管已经在提示中研究了模板工程(Liu 2021),但一些研究人员的目标是用指令I描述任务并在xi和yi之间添加中间推理步骤,这样为ICL设计更好的演示格式。
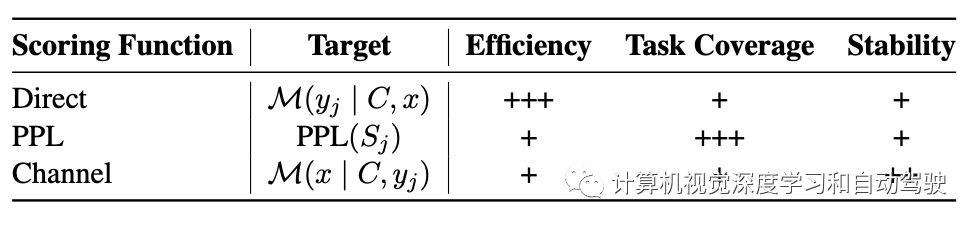
评分函数决定了如何将语言模型的预测转化为对特定答案可能性的估计。直接估计方法(Direct)采用了候选答案的条件概率,该概率可以用语言模型词汇表中的token表示(Brown 2020),选择概率较高的答案作为最终答案。然而,这种方法对模板设计提出了一些限制,例如,答案token应该放在输入序列的末尾。复杂度(Perplexity,PPL)是另一个常用的度量,它计算整个输入序列的句子复杂度,该序列由示例C、输入查询x和候选标签yj的标记组成。当PPL评估整个句子的可能性时,它消除了token位置的限制,但需要额外的计算时间。
与先前在给定输入上下文情况下估计标签概率的方法不同,Min(2022a)提出利用通道模型(Channel)反向计算条件概率,即,给定标签,做输入查询的似然估计。这种方式需要语言模型来生成输入中的每一个token,这可以提高在不平衡训练数据机制下的性能。下表总结了所有三个评分函数。由于ICL对演示很敏感,用空输入减去模型依赖性的先验,可以归一化得分,有助于提高稳定性和整体性能(Zhao2021)。
 另一个方向是,结合超出上下文长度约束的信息,校准分数。
Structured Prompting(Hao 2022b)提出用特殊的位置嵌入对演示示例单独编码,然后采用重尺度化的注意机制提供给测试示例。
kNN Prompting(Xu et al.,2023a)首先用分布式表征的训练数据对LLM查询,然后用存储的锚表征简单地引用封闭表征的最近邻居,预测测试实例。
另一个方向是,结合超出上下文长度约束的信息,校准分数。
Structured Prompting(Hao 2022b)提出用特殊的位置嵌入对演示示例单独编码,然后采用重尺度化的注意机制提供给测试示例。
kNN Prompting(Xu et al.,2023a)首先用分布式表征的训练数据对LLM查询,然后用存储的锚表征简单地引用封闭表征的最近邻居,预测测试实例。
总结一下要点:(1)在上表中总结了三种广泛使用的评分函数的特点。虽然直接采用候选答案的条件概率是有效的,但这种方法仍然对模板设计提出了一些限制。困惑度也是一个简单而广泛的评分函数。该方法具有普遍的应用,包括分类任务和生成任务。然而,这两种方法仍然对演示表面很敏感,而通道是一种补救措施,特别是在数据不平衡的情况下。(2)现有的评分函数都是直接从 LLM 的条件概率计算分数。关于通过评分策略校准偏差或减轻敏感性的研究有限。例如,一些研究添加了额外的校准参数来调整模型预测(Zhao,2021)。





