1
新智元报道
来源:ArXiv
作者:闻菲
2017 年 11 月 8 日,在北京国家会议中心举办的
AI WORLD 2017 世界人工智能大会
开放售票!
还记得去年一票难求的AI WORLD 2016盛况吗?今年,我们邀请了
冷扑大师”之父 Tuomas 亲临现场,且谷歌、微软、亚马逊、BAT、讯飞、京东和华为等企业重量级嘉宾均已确认出席。
AI WORLD 2017 世界人工智能大会“AI 奥斯卡”AI Top 10 年度人物、 AI Top10 巨星企业、AI Top10 新星企业、AI Top 10 创投机构、AI 创新产品五个奖项全部开放投票。
谁能问鼎?你来决定。
关于大会,请关注新智元微信公众号或访问活动行页面
:http://www.huodongxing.com/event/2405852054900?td=4231978320026了解更多!
【新智元导读】
或许你还记得南大LAMDA教授周志华和学生冯霁在今年早些时候发表的
“深度森林”论文
,他们认为基于决策树集成的方法同样可以构建深度学习模型,并提出深度森林gcForst,对神经网络以外的深度模型进行了探索。现在,在深度森林的基础上,他们又提出了基于决策树集成方法的自编码器(auto-encoder) eForest。实验结果表明,eForest在速度和精度等方面均优于基于DNN的自编码器。

自编码是一项重要的任务,通常由卷积神经网络(CNN)等深度神经网络(DNN)实现。本文中,我们提出了EncoderForest(简写为eForest),这是第一个基于树集成的自编码器。我们提出了一种方法,让森林能够利用树的决策路径所定义的等效类来进行后向重建,并在监督和无监督环境中展示了其使用情况。实验结果表明,与DNN自编码器相比,eForest能够以较快的训练速度获得更低的重建误差,同时模型本身具有可重用性和容损性。
如果上面这段话看上去似曾相识,比如关键词“基于树的”、“eForest”,还有“相比DNN,基于树的方法更加……”的表述,你没有弄错,南大LAMDA教授周志华和他的学生冯霁又出手了。
今年早些时候,他们两人的论文
《深度森林:探索深度神经网络以外的方法》
,在业界引发了不小的反响。在那篇论文中,周志华和冯霁提出了一种基于树的方法gcForest——“multi-Grained Cascade forest”,多粒度级联森林——通过一种全新的决策树集成方法,使用级联结构,让gcForest做表征学习。实验中,gcForest使用相同的参数设置,在不同的域中都获得了优异的性能,在大型和小型数据集上表现都很好。此外,由于是基于树的结构,gcForest相比神经网络也更容易分析。
在gcForest论文中,作者写道:“我们认为,要解决复杂的问题,学习模型也需要往深了去。然而,当前的深度模型全部都是神经网络。这篇论文展示了如何构建深度森林(deep forest),为在许多任务中使用深度神经网络以外的方法打开了一扇门。”
现在,他们在gcForest的基础上,继续探索DNN以外的方法,这次瞄准的是自编码器。

在最新论文《用决策树做自编码器》(AutoEncoder by Forest)中,周志华和冯霁提出了EncoderForest,也即“eForest”,让一个决策树集成在监督和无监督的环境中执行前向和后向编码运算,实验结果表明,eForest方法具有以下优点:
-
准确
:实验重建误差低于基于MLP或CNN的自编码器
-
高效
:在单个KNL(多核CPU)上的训练eForest的速度,比在Titan-X GPU上训练CNN自编码器速度更快
-
容损
:训练好的模型在部分受损的情况下仍然运行良好
-
可复用
:在一个数据集上训练好的模型能够直接应用于同领域另外一个数据集
下面是新智元对最新论文的编译介绍,要查看完整的论文,请参见文末地址。
这一次,我们先从结论看起,再回过头看eForest模型的提出和实验结果。在结论部分,作者写道,
在本文中,我们提出了首个基于树集成的自编码器模型EncoderForest(缩写eForest),我们设计了一种有效的方法,使森林能够利用由树的决策路径所定义的最大相容规则(MCR)来重构原始模式。实验证明,eForest在精度和速度方面表现良好,而且具有容损和模型可复用的能力。尤其是在文本数据上,仅使用10%的输入比特,模型仍然能够以很高的精度重建原始数据。
eForest的另一个优点在于,它可以直接用于符号属性或混合属性的数据,不会将符号属性转换为数字属性,在转换过程通常会丢失信息或引入额外偏差的情况下,这一点就显得尤为重要。
需要注意,监督eForest和无监督的eForest实际上是由多粒度级联森林gcForst构建的深度森林在每一级同时使用的两个成分。因此,这项工作也可能加深对gcForst的理解。构建深度eForest模型也是未来值得研究的有趣问题。
自编码器有两大基本功能:编码和解码。编码对于森林来说很容易,因为单是叶节点信息就可以被视为一种编码方式,而节点的子集甚至分支路径都可能为编码提供更多信息。
编码过程
首先,我们提出EncoderForest的编码过程。给定一个含有 T 颗树的训练好的树集成模型,前向编码过程接收输入数据后,将该数据发送到集成中的树的每个根节点,当数据遍历所有树的叶节点后,该过程将返回一个 T 维向量,其中每个元素 t 是树 t 中叶节点的整数索引。
Algorithm 1展示了一种更具体的前向编码算法。注意该编码过程与如何分割树节点的特定学习规则是彼此独立的。例如,可以在随机森林的监督环境中学习决策规则,也可以在无监督的环境(例如完全随机树)中学习。

解码过程
至于解码过程,则不那么明显。事实上,森林通常用于从每棵树根到叶子的前向预测,如何进行向后重建,也即从叶子获得的信息中推演原始样本的过程并不清晰。
在这里,我们提出了一种有效并且简单(很可能是最简单的)策略,用于森林的后向重建。
首先,每个叶节点实际上对应于来自根的一条路径,我们可以基于叶节点确定这个路径,例如下图中红色高亮的路径。
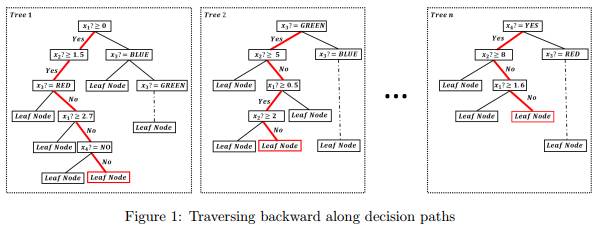
其次,每条路径对应一个符号规则,上图中高亮的路径可以对应以下规则集,其中 RULEi 对应森林中第 i 颗树的路径,符号“:”表示否定判断:
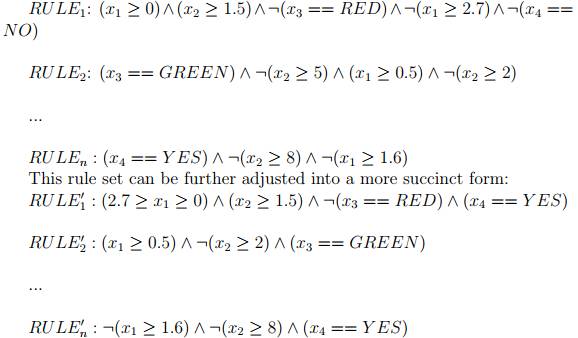
然后,我们可以推导出最大相容规则(MCR)。从上面的规则集中可以得到这样的MCR:
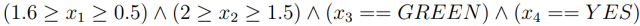
这个MCR的每个组成部分覆盖范围都不能扩大,否则就会与其他条件冲突。因此,原始样本不得超出MCR定义的输入区域。Algorithm 2对这一规则给出了更详细的描述。

获得了MCR后,就可以对原始样本进行重建。具体说,给定一个训练好的含有 T 棵树的森林,以及一个有
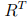 中前向编码
中前向编码
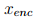 的特定数据,后向解码将首先通过
中的每个元素定位单个叶节点,然后根据对应的决策路径获得相应的 T 个决策规则。通过计算MCR,我们可以将
返回给输入区域中的
的特定数据,后向解码将首先通过
中的每个元素定位单个叶节点,然后根据对应的决策路径获得相应的 T 个决策规则。通过计算MCR,我们可以将
返回给输入区域中的
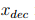 。Algorithm 3给出了具体的算法。
。Algorithm 3给出了具体的算法。

通过前向编码和后向编码运算,eForest就能实现自编码任务。
此外,eForest模型还可能给出一些关于决策树集成模型表征学习能力的理论洞察,有助于设计新的深度森林模型。
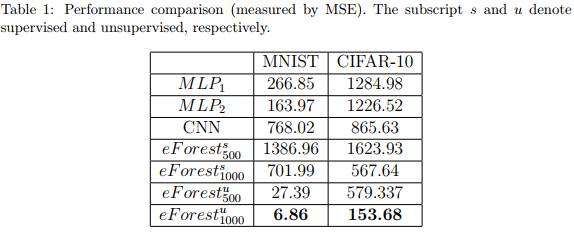
作者在监督和无监督条件下评估了eForest的性能。其中,下标500和1000分别表示含有500颗和1000颗树的森林,上标s和u分别表示监督和无监督。在这里eForest N 将输入实例重新表示为N维向量。
相比基于DNN的自编码器,eForest在图像重建、计算效率、模型可复用以及容损性实验中表现都更好,而且无监督eForest表现有时候比监督eForest更好。此外,eForest还能用于文本类型数据。
图像重建

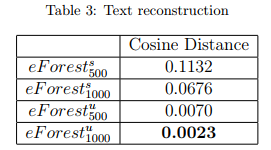
文本重建
由于基于CNN和MLP的自编码器无法用于文本类型数据,这里只比较了eForest的性能。也展示了eForest可以用于文本数据。
计算效率
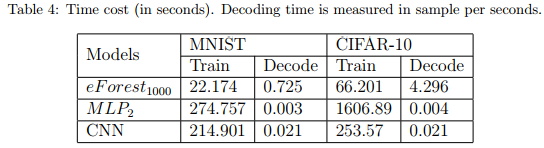
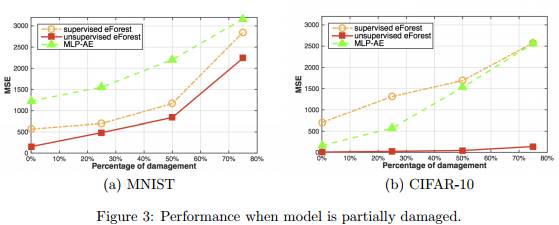
容损性
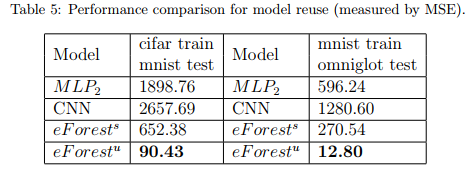
模型可复用

论文地址:https://arxiv.org/pdf/1709.09018.pdf
【号外】
新智元正在进行新一轮招聘,
飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~






