小说君三年前写了篇面试经验,前几天偶然打开,发现很多地方写的也是不忍直视。
比如,当时小说君的简历上写了一个计划中的、基于golang的「协程特性」、写RPC库的项目。golang老司机可能直接就能看出这个想法的问题——所以三年多过去了,小说君还没写下这个库的第一行代码。
抛开golang这门语言不谈,所谓「协程特性」,其实就是Coroutine。
Coroutine可以说是一个相当久远的概念,wiki这样说:
According to Donald Knuth, the term
coroutine
was coined by Melvin Conway in 1958, after he applied it to construction of an assembly program.The first published explanation of the coroutine appeared later, in 1963.
那这个几十年前就有的概念,又是为什么在三四年前开始火起来了呢?
具体原因小说君也不知道,只能在这里列举一下当时(13年中)的一些事实:
-
golang刚release 1.1。虽然社区都在喷golang的gc——2013年了居然不分代,但是goroutine模型确实让程序员,接触到了与传统编程(各种借助或不借助闭包的callback机制)不一样的异步模型。各种趋势在证明,除了线程池,我们还有更多非抢占式的并发编程可能性。
-
Unity3D借助C#的Generator机制实现的「Coroutine」,适用于不少游戏特定的业务情景。最常见的例子就是定时器,我们不再需要在主循环里检查或是注册callback,现在只要定义成IEnumerator,在中间插入Wait代码,跟写同步逻辑基本一样。
-
一些主流语言还没有原生的异步语义支持。除了C#很早就支持了async/await,但是像JS和python这种互联网中流砥柱都是过了一两年才逐渐开始支持。没有async/await,想用同步方式写异步逻辑就只能借助coroutine。
前段时间,小说君刚接触了Lua的coroutine机制,于是有了写这篇入门向的想法。
不过,Coroutine话题的热度已经远不如以前,所以小说君选择从不同的角度看这个问题。
首先,Coroutine是什么?
wiki定义:
Coroutines are computer program components that
generalize subroutines
for
non-preemptive multitasking
, by allowing
multiple entry points
for
suspending
and
resuming
execution at certain locations.
定义非常简单,小说君标记了几个重点:
下面我们逐条讨论。
泛化的subroutine
Subroutines are special cases of ... coroutines.
— Donald Knuth.
比较容易理解:
subroutine是只能受让caller的控制流,return的时候作为callee把控制流交出去。
而coroutine可以在任意时刻把控制流交给其他coroutine。
多entry point
首先,我们要建立一个「context」的概念。
与「environment」不同。每个执行流都有私有的「context」,而「environment」则有可能是由多个closure共享的。
跑个题,操作系统中的「context switch」,切换的就是「context」。
内核做context switch的时候需要还原哪些状态?
——所有能够还原现场的信息,如果不考虑切进程的话,那就至少要有PC,栈帧,寄存器等状态。
我们不论call一个subroutine还是resume一个coroutine,这两种「routine」在获得控制流的时候都有一个「context」。
对于subroutine来说,第一次调用和第N次调用的context是不会产生什么联系的。
对于coroutine来说,因为需要有不同的entry point,所以每次调用的context也都取决于上次调用。
非抢占式多线程
这个也比较容易理解了,协程跟线程不一样,控制流是显式让出的,而不是由调度器来抢占式调度的。
yield/resume
简单地说,就是我们既可以resume,把控制权交给被resume的协程,也可以在一个协程中yield,把控制权交出去。
除此之外,wiki上还对coroutine做了分类:
其中前两者的区别仅仅是语义上的。
对称式协程不论yield还是resume都可以把控制权交由任意其它coroutine;
非对称式协程的yield只能把控制权交给当前coroutine的caller(说resumer更合适——resume了当前coroutine)。
当然,显然两者的实现是等价的,而对称式协程理解起来也不如对称式协程直观,因此本文就不再讨论对称式协程。
至于半协程,其实就是受限制的协程实现。各种语言中常见的generator,甚至是有些async/await的实现,都属于半协程。
只要不能做到在某个协程的call hierarchy中随意跳转控制流,理论上都是半协程。
形而上的闲扯就到这里,下面我们结合一个具体的例子先感性认识下Coroutine。
还是老生常谈的rpc,这次换成lua描述:
function M:RequestTest(arg0,cb)
end
有这样一个lua函数定义,函数的实现不再多说,形参中arg0就是RPC调用的参数,cb表示回调。简单说下基本流程:
-
调用底层RPC模块的打包函数序列化掉参数和服务、方法ID,发给网络层。
-
把这次调用的handle存下来,cb也存下来。
-
当远端返回了对应本次RPC的response,就由逻辑线程取出handle,并回调cb。
用起来是这样的效果:
M:RequestTest("name", function (err0, r0)
print("callback1")
end)
正是因为语言层面支持closure,我们写异步逻辑很方便。
语言本身可以帮你capture到上下文,一些不需要double check的状态就不用应用层自己去拿了。
按正常文章的套路,接下来会讲callback hell,类似于这样:
M:RequestTest("name1", function (err1, r1)
print("callback1")
M:RequestTest("name2", function (err2, r2)
print("callback2")
M:RequestTest("name3", function (err3, r3)
print("callback3")
M:RequestTest("name4", function (err4, r4)
print("callback4")
end)
end)
end)
end)
如果每句print之后都有大段流程相关的逻辑,试想下接盘的维护者的绝望。
然后继续套路,我们借助Lua的coroutine机制,瞬间就可以改写成这样:
_.Fork(function ()
print
("begin")
local err1, r1 = M:RequestTest("name"):Yield()
print("resume1 ", err1, r1)
local err2, r2 = M:RequestTest("name"):Yield()
print("resume2 ", err2, r2)
local err3, r3 = M:RequestTest("name"):Yield()
print("resume3 ", err3, r3)
local err4, r4 = M:RequestTest("name"):Yield()
print("resume4 ", err4, r4)
end)
清爽了许多,可以说有一种银弹的感觉了。
当然,这个示例稍微对原生的API做了下包装,不过核心还是用Fork的参数构造一个coroutine:
主逻辑执行 => resume
异步操作 =>
yield => 主逻辑执行 => callback => resume
异步操作 =>
yield => 主逻辑执行 => callback => resume
...
一直到coroutine执行完毕为止。
以上就是协程的感性入门,接下来聊聊如何劝退。
首先简化下问题。
我们看一个最简单的coroutine形式,然后围绕着这个case讨论如何用各种方式实现出来。
_.Fork(function ()
local t = {}
print("begin")
local err0, r0 = M:RequestTest("name"):Yield()
print("resume ", err0, r0, t)
end)
Fork应该向应用层保证这样几点语义:
-
Fork仅需要调用一次。
-
调用时会一直同步执行到第一个yield为止,然后Fork返回,上层不会阻塞在Fork调用。
-
之后由底层做调度,保证resume回来的时候仍然由主线程继续执行yield后面的语句,直到遇到下个yield为止。
-
循环往复,直到作为Fork参数的coroutine执行完毕。
这个例子对真实环境的协程管理器做了相当程度的简化。
比如示例中只出现了一个协程,我们不需要再考虑多协程的调度机制、协程间通信机制。
只用考虑这样一个简单的rpc异步调用例子。
再次感慨,这种异步模型确实是相当优雅——写起来是同步函数,实际上在第四行和第五行之间是异步的。
简单分析下:
为了有更感性的认识,小说君画了个简单的流程图:
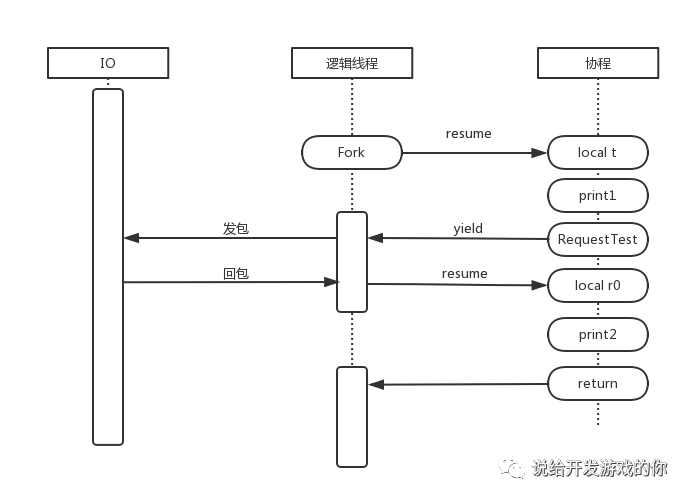
协程本身(就是Fork的参数)有自己的上下文,可以在任意时间点把控制流让出(示例中,只会让出给Caller),然后可以在任意时间点接受控制流(示例中,是由Caller把控制流交回给协程)。
下面看下具体的函数实现,Yield的逻辑很简单,就是包装了下coroutine的API:
function RPCTask:Yield()
return coroutine.yield(self)
end
yield self表达的意思是,yield的同时把self作为参数抛出去。
Fork利用的是现成的callback机制,再做些处理:
local function
Inner(co, ret, task)
if not ret or not task then
return
end
task.Callback = function (err, ...)
local ret, task0 = coroutine.resume(co, err, ...)
Inner(co, ret, task0)
end
end
function M.Fork(f)
local co = coroutine.create(f)
local ret, task = coroutine.resume(co)
Inner(co, ret, task)
end
串起来简单解释一下:
-
Fork先用f构造一个Lua的coroutine,然后resume。
-
Yield把每次异步操作的handle yield出去,再把控制流转回Fork。
-
这时,为了不阻塞Fork的caller,Fork需要直接返回掉,同时在异步操作的handle上挂一个callback,以供callback被调用时,继续resume,把控制流转回coroutine。
-
递归,直到coroutine无法再yield出值,表示coroutine结束。
Lua的coroutine语言机制非常强大,实现这个简单的示例没什么难度。
但是很多时候,我们手头的语言可能并没有这么强大的表达能力。
那在讨论如何在其他语言中实现协程之前,先考虑一个问题:
协程的核心特点是什么?
其实就两个:
跳转控制流的做法很多,在常规语言中,只要routine能return,以及外部能多次进入同一个routine,再借助一些内部状态判断每次进入时的执行点,就能模拟出控制流跳转。
但是还原执行状态的要求就高了,一定需要语言层面的支持。大致分为以下三类:
-
C/C++这种系统级语言,可以用setjmp/longjmp,ucontext。前者能还原PC、栈相关的一些指针,后者还能在前者基础上还原栈帧。
-
支持generator/async/await语义的静态语言,会在编译期把打了标记的流程中的栈变量lift到堆上(比如C#会维护在某个匿名类实例中)。那所谓还原执行状态,就是取到实例,拿出状态。
-
最后就是原生支持coroutine或continuation的语言,那自然会在runtime层面支持上下文还原机制了。
那接下来,我们就看看如果有这三类语言构件,我们分别应该怎么样实现前面示例中的rpc同步编程形式。
先看一些系统编程语言中能用的手段。
像汇编这种能直接操作栈帧和寄存器的就不说了,要实现肯定是能实现的,不过并没有什么意义。
由于小说君也挺久没用C了,所以这小节就以伪码为主,各位意会即可,代码别说能正确表现结果了,小说君甚至不能保证可以编译通过。
首先看setjmp/longjmp。
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int value);
C标准库API,属于一种non-local exit。大家应该很熟悉了。
jmp_buf是一个平台特定的结构,在setjmp的时候会把上下文保存下来。longjmp的时候还原上下文,直接在setjmp的下条指令返回。
setjmp的首次调用返回值是0,longjmp跳转时,setjmp的返回值是传给longjmp的value。
代码写起来差不多就是这种感觉:
void fork(func *f){
if (setjmp(main_env) == 0){
f();
}
else{
// ...
}
}
void routine(){
int t = 0;
printf("begin");
struct rpc_task *task = request_test("name");
int handle = yield(task);
// 根据handle拿到结果
printf("resume");
}
struct rpc_task *
request_test(const char *name){
struct rpc_task *task = __invoke(/*...*/);
return task;
}
void yield(struct rpc_task *task){
task->cb = request_test_cb;
if (setjmp(task_env) == 0){
longjmp(main_env, 1);
}
}
void request_test_cb(struct rpc_task *task, int errId, int ret){
task->errId = errId;
task->ret = ret;
longjmp(task->env, task->handle);
}
不过,setjmp/longjmp由于只有控制流跳转的能力——毕竟大部分使用情景还是用来实现try-catch-finally。
虽然可以还原PC和栈指针,但是无法还原栈帧,因此会出现很多问题。
比如longjmp的时候,setjmp的作用域已经退出,当时的栈帧已经销毁。这时就会出现未定义行为。
假设有这样一个调用链:
func0() -> func1() -> ... -> funcN()
只有在funci中setjmp,在func(i+k)中longjmp的情况下,程序的行为才是可预期的。
也是因为这个原因,我们上面的代码示例中,fork的实现有一个非常强的限制,那就是外层一定要有一个不会退出的caller,帮fork以及fork的所有call hierarchy维持栈帧。
维持栈帧两个方法:
但是两种方法都属于奇技淫巧,要么是限制大,要么是可移植性差,那我们不如借助一些平台特定的、更强大的库,比如ucontext,来实现需求。
ucontext和setjmp/longjmp非常像,有两个API是这样的:
void makecontext(ucontext_t *ucp, void *func(), int argc, ...);
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
ucontext_t是比jmp_buf更完整的上下文状态,维护了私有栈。
makecontext可以初始化一个入口为func的ucontext。
swapcontext的语义更直接了,可以原子地把当前的执行上下文保存在oucp中,并且切换到ucp的上下文。
所以,上面的例子可以改造成这样:
ucontext_t mainucontext_t taskvoid fork(func *f){
char stack[1024]
ucontext_t task
//指定栈空间
task.uc_stack.ss_sp = stack
task.uc_stack.ss_size = sizeof(stack)
task.uc_stack.ss_flags = 0
//设置后继上下文
task.uc_link = &main
//构造task的context
makecontext(&task,(void (*)(void))f,0)
//切换到task上下文,保存当前上下文到main
swapcontext(&main, &task)
//如果设置了后继上下文,f函数执行完后会返回此处
// ...
puts("fork")}
void routine(){
int t = 0
printf("begin")
struct rpc_task *task = request_test("name")
yield(task)
// 根据task拿到结果
printf("resume")}
struct rpc_task *
request_test(const char *name){
struct rpc_task *task = __invoke()
return task}
void yield(struct rpc_task *task){
task->cb = request_test_cb
swapcontext(task->ctx, &main)}
void request_test_cb(struct rpc_task *task, int errId, int ret){
task->errId = errId
task->ret = ret
swapcontext(&main, task->ctx)}
整体上跟用setjmp/longjmp很像,但是不需要自己处理栈帧的问题。
再次声明,这只是纯示例用的伪代码,不保证正确性。
github上用ucontext实现的生产级coroutine库有很多,核心原理都是借助swapcontext切换上下文,外部再做一些栈分配相关的优化,不会像示例代码这样直接fork的时候栈上分配一个固定大小的协程栈,有兴趣的同学可以搜索下研究研究。
接下来看generator。
Generator是一种相当常见的语言构件。
python里就是generator,C#里就是IEnumerator。
由于小说君对C#比较熟悉,这一节就以C#为例了。
C#如此定义Generator:
IEnumerator Routine(int n)
{
for(var i = 0; i < n; i++)
{
yield return i;
}
}
void Test()
{
foreach (var r in Routine(10))
{
Console.Writeline(r);
}
}
我们可以总结下Generator最典型的特征:
不过,如果有一个全局的dispatcher,我们还是能模拟出来标准协程的语义的。
比如unity中的协程。
常用姿势大概是这样:
IEnumerator Routine()
{
DoSomething()
yield return new WaitForSeconds(1f)
DoSomething()}
void Foo()
{
StartCoroutine(Routine())}
StartCoroutine的逻辑大概就是这样:
void StartCoroutine(IEnumerator routine)
{
if (!routine.MoveNext())
{
return;
}
var obj = routine.Current;
if (obj is WaitForSeconds)
{
}
}
在注释处,会利用现有的定时器机制,注册定时器,并在回调里再继续调用routine。
这样,Routine的逻辑就相当连贯了,先做一些事情,再异步等1秒,再继续做一些事情。
那我们再回过头看需求的效果。
由于C#中不支持匿名定义generator,所以只能这样写:
_.Fork(Routine())
IEnumerator Routine()
{
int t = 0
Console.Writeline("begin")
var task = M.RequestTest("name")
yield return task
Console.Writeline($"resume {task.Err} {task.R0} {t}")}
由于yield表达式并没有返回值,所以看着有点别扭。
然后是Fork的流程:
void Fork(IEnumerator routine)
{
if (!routine.MoveNext())
return;
var obj = routine.Current as RPCTask;
if (obj != null)
{
obj.Callback = r =>
{
Fork(routine);
};
}
}
也是伪代码,实现得比较粗糙。
基本思路跟上面演示的简单版StartCoroutine是一样的,借助底层RPC的callback机制,异步驱动routine。
接下来,我们看看generator是如何有还原现场的能力的。
如前所述,C# compiler会把这个generator中的栈上变量给lift,存在一个匿名类对象中。
看下compiler处理过后的代码,大概转成了这个样子:
class RoutineClass
{
private int t;
private RPCTask task;
private int state = 0;
public object MoveNext()
{
if (state == 0)
{
t = 0;
Console.WriteLine("begin");
task = RequestTest("name");
state ++;
return task;
}
else if (state == 1)
{
Console.WriteLine($"resume {task.Err} {task.R0} {t}");
return null;
}
throw new Exception();
}
}
编译器用了一些犯规的手段,为每个generator定义了匿名类,把栈上变量全部定义为该类的成员。
然后利用switch-case实现多次进入,entry-point不同的效果,
相当巧妙。
所以,我们才能在应用层利用这个特性,以及语言本身的GC机制,
一是实现了上下文的还原。变量lift。
二是模拟出了resume语义时的值传递。caller拿到task,同时把task和routine缓存下来,等到IO有返回,把值放到task中,然后回调routine。
最后我们看看表达能力更强的continuation。
continuation是一个函数,表示程序某一瞬间的状态。如果apply了这个函数,会在apply的同时,进入到continuation表示的程序状态。
以免有同学对接下来的内容一头雾水,小说君先举个简单的例子:
(display
(call-with-current-continuation
(lambda (kont)
(kont 5))))
简单地说,就是调用call-with-current-continuation(简称call/cc)时,会保存当前上下文。
然后把这个上下文作为一个参数(kont),传递给call/cc调用的routine。
在routine中,只要apply了这个kont,会做三件事情:
很显然,这跟协程的语义非常像,因此我们可以很容易地实现最开始的示例需求。
而且,我们能支持的feature还比之前用generator模拟的协程更多——借助continuation,既可以把值yield给caller,也可以在caller中resume值给routine。
还是从简单的开始,先看看一个异步rpc做的事情:
(define request-test
(lambda (name) 'tmp-task))
定义了request-test,仅仅是返回个task。
然后callback部分也做了简化,默认是设置callback的时候直接就当作是IO层有返回,直接设置了结果。
(define set-callback
(lambda (task cb) (cb
"result")))
然后我们预期可以这样写协程:
(define my-routine
(coroutine (yield)
(let ((tmp 1))
(display "begin")
(newline)
(let ((retval (yield (request-test "name"))))
(display "resume")
(display tmp)
(display retval)
(let ((retval2 (yield (request-test "name"))))
(display "resume2")
(display retval2))))))
其实就是最开始的lua例子的翻译版。
那看到这个期望的形式,其实我们对coroutine实际是个什么也就猜的八九不离十了。
如果把这个my-routine当作一个函数,那么调用开始的时候就需要借助call/cc做个bookmark(称作yield-to)。
然后执行my-routine,直到中间调用到yield,首先要再借助call/cc做一次bookmark(称作resume-to)。
yield出去之后,外部需要拿到resume-to对应的continuation,这样才能在需要resume的时候还原上下文,把控制流再交回coroutine。
与此同时,外部在resume的时候还要再借助call/cc做一次bookmark,因为之后coroutine再做yield,需要yield-to的现场已经不是最开始的yield-to。
这样一梳理,coroutine宏的定义就有了:
(define-syntax coroutine
(syntax-rules ()
(
(coroutine (yieldfunc) body)
(let (
(yield-to #f)
)
(lambda ()
(call-with-current-continuation
(lambda (tmp-yield-to)
(set! yield-to tmp-yield-to)
(let (
(yieldfunc
(lambda (x)
(call-with-current-continuation
(lambda (resume)
(yield-to (
cons (
lambda(resume
-val)
(call-with-current-continuation
(lambda (tmp-resume-yield-to)
(set! yield-to tmp-resume-yield-to)
(resume (cons #t resume-val))))))
x)))))))
body
(yield-to (cons #f
如前所述,yield-to现在是一个自由变量,coroutine在执行过程中会不断修改。
yieldfunc就是我们用宏模拟的yield关键字,实际上就是个函数。
小说君在这里实现的比较偷懒,简化了流程——外部resume coroutine,等coroutine yield的时候,可以拿到一个函数,用来做后续的resume。
我们在实现scheme版的fork之前,先看看这个coroutine怎么调用。
第一次的resume是这样:
(let ((ret (my-routine)))
(let (
(resume (car ret))
(task (cdr ret)))
(set-callback
task
(lambda (val)
(resume val)))))
callback里面直接resume,前面说过了,为了简化问题,会在set-callback的时候直接调用callback。
所以这里会直接通过调用resume再把控制流交给coroutine,同时传一个值进去。
那有了之前Lua版的Fork实现,用Scheme改写也很容易,核心是一个递归:
(define fork
(lambda (routine)
(letrec (
(inner (
lambda (resume task)
(if (procedure? resume)
(set-callback
task
(lambda (val)
(let ((resume-ret (resume val)))
(inner (car resume-ret) (cdr resume-ret)))))
'finished))))
(let ((ret (routine)))
(let (
(resume (car ret))
(task (cdr ret)))
(inner resume task))))))
最后写起来跟Lua版本的是一致的,这里就不再就地展开my-routine了:
(fork my-routine)
coroutine的话题就到这里,当然,coroutine并不是异步编程的全部,还有其他成熟的异步模型,以及并发模型。
比如actor,比如promise,比如CSP,比如Rx等等。各种模型都有各自的适应业务情景,比如文章中举的最简单的同步写RPC调用的例子,可能coroutine模型就是最适合的。
个人订阅号:gamedev101「说给开发游戏的你」,聊聊服务端,聊聊游戏开发。






