本文目录如下:
-
k近邻算法的基本概念,原理以及应用
-
k近邻算法中k的选取,距离的度量以及特征归一化的必要性
-
k近邻法的实现:kd树原理的讲解
-
kd树详细例子讲解
-
kd树的不足以及最差情况举例
-
k近邻方法的一些个人总结
k近邻算法是一种
基本分类和回归方法
。本篇文章只讨论分类问题的k近邻法。
k近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分类到这个类中。(这就类似于现实生活中少数服从多数的思想)根据这个说法,咱们来看下引自维基百科上的一幅图:
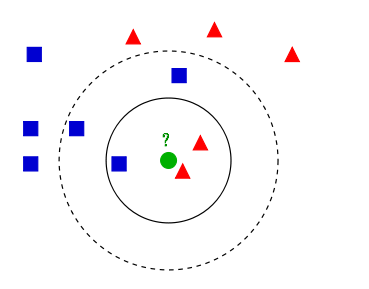
如上图所示,有
两类
不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是
待分类的数据
。
这也就是我们的目的,来了一个新的数据点,我要得到它的类别是什么?好的,下面我们根据k近邻的思想来给绿色圆点进行分类。
从上面例子我们可以看出,k近邻的算法思想非常的简单,也非常的容易理解,那么我们是不是就到此结束了,该算法的原理我们也已经懂了,也知道怎么给新来的点如何进行归类,只要找到离它最近的k个实例,哪个类别最多即可。
哈哈,没有这么简单啦,算法的核心思想确实是这样,但是要想一个算法在实际应用中work,需要注意的不少额~比如k怎么确定的,k为多少效果最好呢?所谓的最近邻又是如何来判断给定呢?
哈哈,不要急,下面会一一讲解!
k近邻的k值我们应该怎么选取呢?
如果我们选取较小的k值,那么就会意味着我们的整体模型会变得复杂,容易发生过拟合!恩~结论说完了,太抽象了吧你,不上图讲解号称通俗讲解的都是流氓~
好吧,那我就上图来讲解假设我们选取k=1这个极端情况,怎么就使得模型变得复杂,又容易过拟合了呢?
假设我们有训练数据和待分类点如下图:
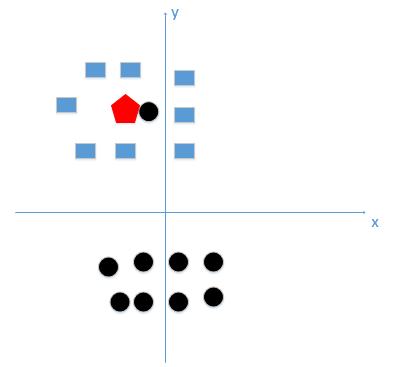
上图中有俩类,一个是黑色的圆点,一个是蓝色的长方形,现在我们的待分类点是红色的五边形。
好,根据我们的k近邻算法步骤来决定待分类点应该归为哪一类。我们由图中可以得到,很容易我们能够看出来五边形离黑色的圆点最近,k又等于1,那太好了,我们最终判定待分类点是黑色的圆点。
由这个处理过程我们很容易能够感觉出问题了,如果k太小了,比如等于1,那么模型就太复杂了,我们很容易学习到噪声,也就非常容易判定为噪声类别,而在上图,如果,k大一点,k等于8,把长方形都包括进来,我们很容易得到我们正确的分类应该是蓝色的长方形!如下图:
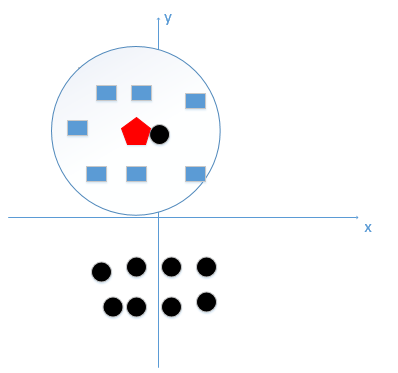
所谓的过拟合就是在训练集上准确率非常高,而在测试集上准确率低,经过上例,我们可以得到k太小会导致过拟合,很容易将一些噪声(如上图离五边形很近的黑色圆点)学习到模型中,而忽略了数据真实的分布!
如果我们选取较大的k值,就相当于用较大邻域中的训练数据进行预测,这时与输入实例较远的(不相似)训练实例也会对预测起作用,使预测发生错误,k值的增大意味着整体模型变得简单。
k值增大怎么就意味着模型变得简单了,不要急,我会解释的!哈哈。
我们想,如果k=N(N为训练样本的个数),那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型是不是非常简单,这相当于你压根就没有训练模型呀!直接拿训练数据统计了一下各个数据的类别,找最大的而已!这好像下图所示:
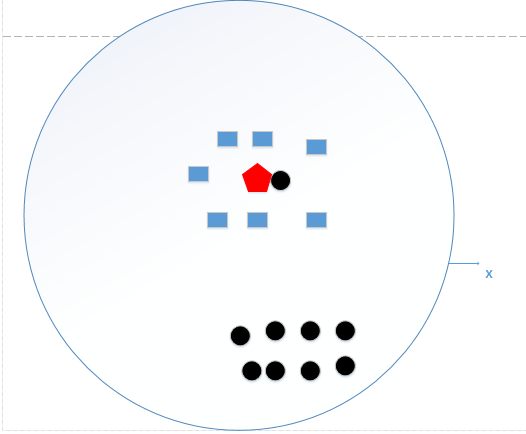
我们统计了黑色圆形是8个,长方形个数是7个,那么哈哈,如果k=N,我就得出结论了,红色五边形是属于黑色圆形的(明显是错误的好不,捂脸!)
这个时候,模型过于简单,完全忽略训练数据实例中的大量有用信息,是不可取的。
恩,k值既不能过大,也不能过小,在我举的这个例子中,我们k值的选择,在下图红色圆边界之间这个范围是最好的,如下图:
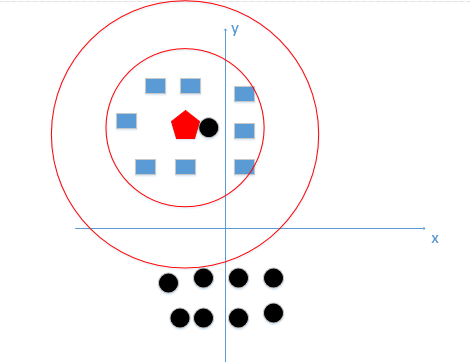
(注:这里只是为了更好让大家理解,真实例子中不可能只有俩维特征,但是原理是一样的1,我们就是想找到较好的k值大小)
那么我们一般怎么选取呢?李航博士书上讲到,我们一般选取一个较小的数值,通常采取 交叉验证法来选取最优的k值。(也就是说,选取k值很重要的关键是实验调参,类似于神经网络选取多少层这种,通过调整超参数来得到一个较好的结果)
原文链接:
http://mp.weixin.qq.com/s/mjkDl_6XUwF9L6GMpbY6Zg




