
独角兽VIP会员群招募
产业研究第一社群,每周行业专家及明星分析师线上路演,分享新兴行业的最新投资机会,不定期线下产业沙龙,北上广深等地闭门会。加入会员即可获得原价3999元各行业及个股深度报告。申请加入需加微信:itouzi6(二维码在文末),加入需备注:姓名+公司+职位
作者|农冰立 陈俊杰
来源|天风证券
编辑|独角兽智库
人工智能倒逼芯片底层的真正变革
人类精密制造领域(半导体制造是目前为止人类制造领域的最巅峰)遇到硅基极限的挑战,摩尔定律的放缓似乎预示着底层架构上的芯片性能的再提升已经出现瓶颈,而数据量的增长却呈现指数型的爆发,两者之间的不匹配势必会带来技术和产业上的变革升级。变革从底层架构开始。计算的体系处于碎片化引发架构变革。数据的扩张远大于处理器性能的扩张,依靠处理器性能在摩尔定律推动下的提升的单极世界已经崩溃,处理器性能提升的速度并不足以满足AI所需的应用程序的需求。大量数据消耗的数字运算能力比几年前所有数据中心加起来还要多。基于冯诺伊曼架构的拓扑结构已经持续了很多年并没有本质上的变化。而人工智能带来的,是在摩尔定律放缓维度下引发芯片底层架构重构的变革。有可能引发的是一次超越以往任何时代的科技革命。
基于摩尔定律的机器时代的架构——从Wintel到AA
冯诺伊曼架构带来了计算体系的建立并通过Intel实现了最大化;ARM通过共享IP的商业模式带来了更开放的生态体系,实现了软硬件的结合延伸了人类的触角观察Intel和ARM的黄金十年,站在现在时点往后看,我们提出以下观点:过去十年以下游的应用驱动设计公司的成长转换为由设计公司主导应用正在发生。从需求层面看企业成长空间。类似90年代的PC和10年的智能手机带来的亿级大空间增量市场将很容易推动企业的快速增长。设计企业能够在成长轨迹上实现跨越式突破的可能性来自于赛道的选择。但站在现在时点看,人工智能是确定性的方向,在所有已有领域的人工智能渗透,都将极大的改变人类的生活。处于最前沿的芯片公司的革新正在以此而发生,重新定义底层架构的芯片,从上游推动行业的变革。在并没有具体应用场景爆发之前已经给予芯片公司充分的高估值就是认可设计公司的价值
人工智能芯片——新架构的异军突起
观察人工智能系统的搭建,以目前的架构而言,主要是以各种加速器来实现深度学习算法。讨论各种加速器的形式和实现,并探讨加速器变革下引发的行业深层次转变。认为人工智能芯片将有可能在摩尔定律放缓维度下引发芯片底层架构重构的变革。
从2个维度测算人工智能芯片空间
从两个维度讨论人工智能芯片的市场空间测算。维度一从人工智能总市场规模空间反推芯片,维度二详细拆分云端/移动端所需人工智能加速器的BOM进而推断人工智能芯片市场空间。二个维度印证到2020年人工智能芯片将达到百亿美元市场。
重点标的:Intel,台积电,NVIDIA,全志科技,富瀚微,北京君正
风险提示:人工智能芯片发展不达预期
1.人工智能倒逼芯片底层的真正变革
研究人类的科技发展史,发现科技的进步速度呈现指数型加速态势。尤其在1950年以后进入芯片时代,摩尔定律推动下的每18个月“芯片晶体管同比例缩小一半”带来的性能提升以倍数计。每一次加速的过程推动,都引发了产业的深层次变革,带动从底层到系统的阶跃。我们本篇报告将着重从底层芯片角度出发,探讨人工智能芯片带来的深层次变革。
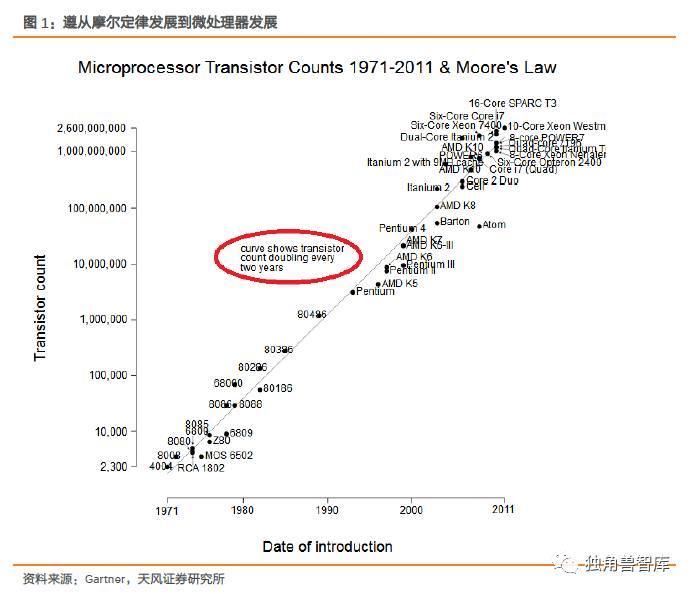
然而时至今日,人类精密制造领域(半导体制造是目前为止人类制造领域的最巅峰)遇到硅基极限的挑战,摩尔定律的放缓似乎预示着底层架构上的芯片性能的再提升已经出现瓶颈,而数据量的增长却呈现指数型的爆发,两者之间的不匹配势必会带来技术和产业上的变革升级。
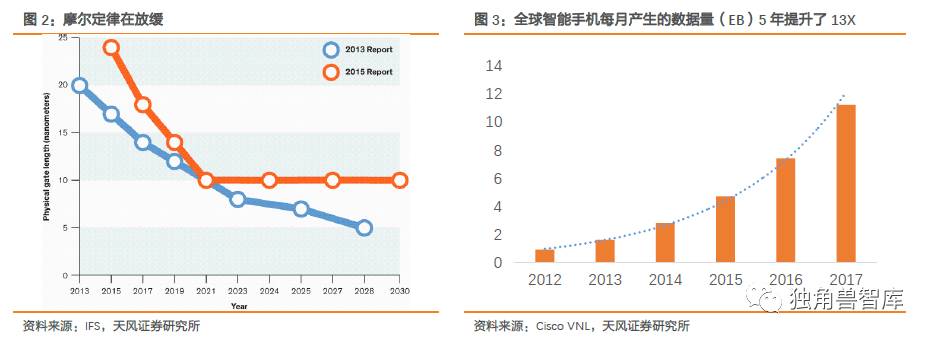
变革从底层架构开始
计算芯片的架构50多年来都没有发生过本质上的变化,请注意计算架构的决定是资源的组织形式。而传统的冯诺伊曼是采取控制流架构,采用的是线性的记忆体和布尔函数作为基线计算操作。处理器的架构基于流水线串行处理的机制建立,存储器和处理器分离,流水线的计算过程可以分解为取指令,执行,取数据,数据存储,依次循环。依靠整个串行的过程,逻辑清晰,但性能的提升通过两种方式,一是摩尔定律下推动下晶体管数量的增多实现性能倍增;二是通过并行多个芯片核来实现。无论何种方式,本质上都是线性的性能扩张。
人工智能芯片根据数据流的碎片化和分布式而采取神经网络计算范式,特征在于分布式的表示和激活模式。变量由叠加在共享物理资源上的向量表示,并且通过神经元的激活来进行计算。以神经元架构实现深度学习人工智能的临界点实现主要原因在于:数据量的激增和计算机能力/成本。
深度学习以神经元为架构。从单一的神经元,再到简单的神经网络,到一个用于语音识别的深层神经网络。层次间的复杂度呈几何倍数的递增。数据量的激增要求的就是芯片计算能力的提升。
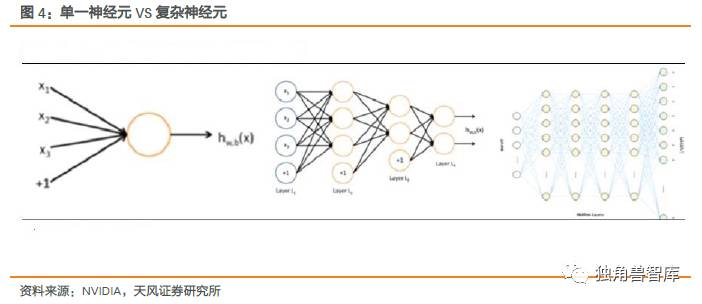
计算的体系处于碎片化引发架构变革。数据的扩张远大于处理器性能的扩张,依靠处理器性能在摩尔定律推动下的提升的单极世界已经崩溃,处理器性能提升的速度并不足以满足AI所需的应用程序的需求。大量数据消耗的数字运算能力比几年前所有数据中心加起来还要多。
我们在下一章将观察历史上两次重要的电子产业变革,试图证明无论是PC时代的“Wintel”还是智能手机时代的“ARM+Android”,都还无法摆脱机器本身的桎梏。换句话说,截止于现阶段的一切技术和应用,基于冯诺伊曼架构的拓扑结构已经持续了很多年并没有本质上的变化。而人工智能带来的,是在摩尔定律放缓维度下引发芯片底层架构重构的变革。有可能引发的是一次超越以往任何时代的科技革命。
2.基于摩尔定律的机器时代的架构——从Wintel到AA
本章我们重点讨论两次芯片架构变化引发的产业变革和应用爆发。Intel与Windows结合构建PC生态,本质上诞生了软硬件结合的机器时代。而在其基础上的延升,2010后苹果带来的智能手机引发的ARM与Android生态,将机器与人的结合拓展到了移动端。我们回顾历史上的芯片架构历史,认为冯诺伊曼架构带来了计算体系的建立并通过Intel实现了最大化;ARM通过共享IP的商业模式带来了更开放的生态体系,实现了软硬件的结合延伸了人类的触角。
观察Intel和ARM的黄金十年,站在现在时点往后看,我们提出以下观点:过去十年以下游的应用驱动设计公司的成长转换为由设计公司主导应用正在发生。从需求层面看企业成长空间。类似90年代的PC和10年的智能手机带来的亿级大空间增量市场将很容易推动企业的快速增长。设计企业能够在成长轨迹上实现跨越式突破的可能性来自于赛道的选择。但站在现在时点看,人工智能是确定性的方向,在所有已有领域的人工智能渗透,都将极大的改变人类的生活。处于最前沿的芯片公司的革新正在以此而发生,重新定义底层架构的芯片,从上游推动行业的变革。在并没有具体应用场景爆发之前已经给予芯片公司充分的高估值就是认可设计公司的价值。
2.1.Intel——PC时代的王者荣耀
本节重点阐述Intel公司在X86时代的芯片架构产品以及此架构下公司以及行业的变化。
2.1.1.Intel公司简介
Intel是一家成立于1968年的半导体制造公司,总部位于美国加州。随着个人电脑的普及和全球计算机工业的日益发展,公司逐渐发展成为全球最大的微处理器及相关零件的供应商。公司在2016年实现营业收入594亿美元,世界500强排名158。
公司分为PC客户端部门、数据中心部门、物联网、移动及通讯部门、软件及服务运营,其他还有笔记本部门、新设备部门及NVM解决方案部门。公司主要营业收入来自于PC客户部门,其次是数据中心部门。公司的主要产品X86处理器占主导地位,接近90%,包括苹果在2006年放弃PowerPC改用英特尔的x86processors。

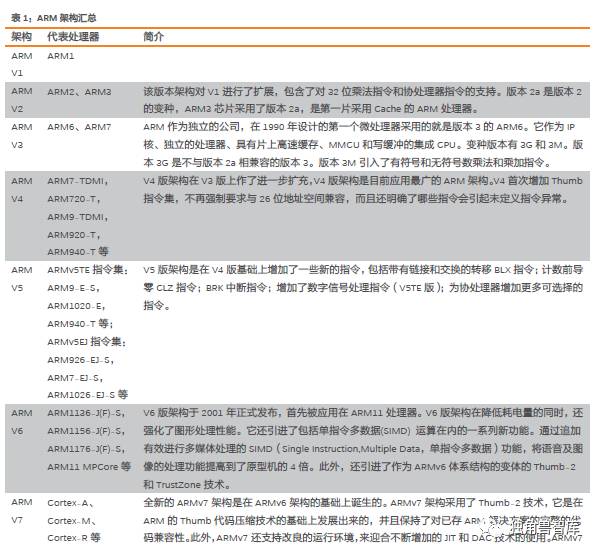
Intel是第一家推出x86架构处理器的公司。Intel从8086开始,286、386、486、586、P1、P2、P3、P4都用的同一种CPU架构,统称X86。大多数英特尔处理器都是基于x86指令集,被称为x86微处理器。指令集是微处理器可以遵循的基本命令集,它本质上是微处理器的芯片级“语言”。英特尔拥有x86架构的知识产权和给AMD和Via做处理器的许可权。
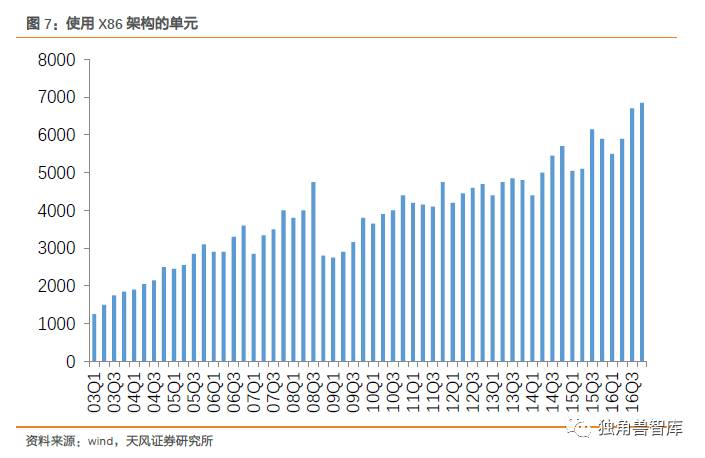
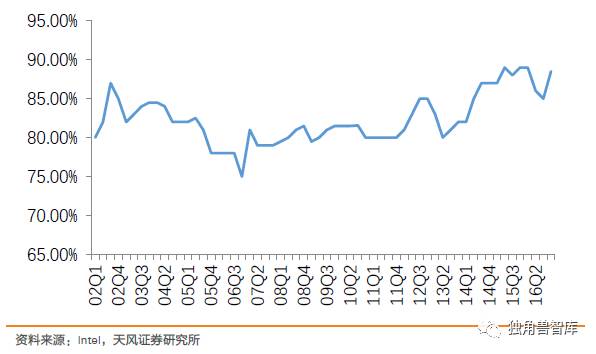
2.1.2.Intel带来的PC行业的市场规模变革和产业变化
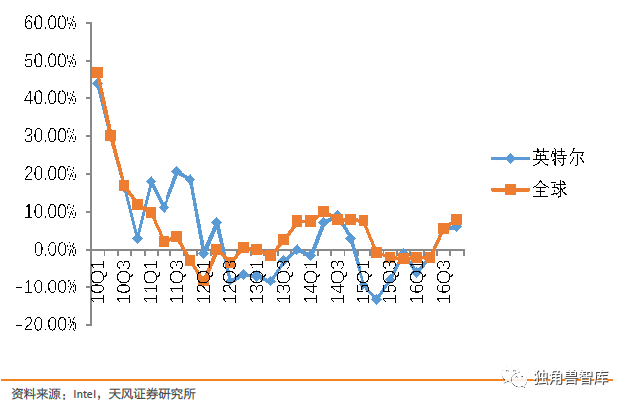
回顾Intel90年代至今发展历程,清晰看到90年代是Intel发展最快的阶段并在2000年前后达到了峰值。显而易见的原因是个人电脑的快速普及渗透。而遵从摩尔定律的每一代产品的推出,叠加个人电脑快速渗透的乘数效应,持续放大了企业的市值,类似于戴维斯双击,推动股价的一路上扬。
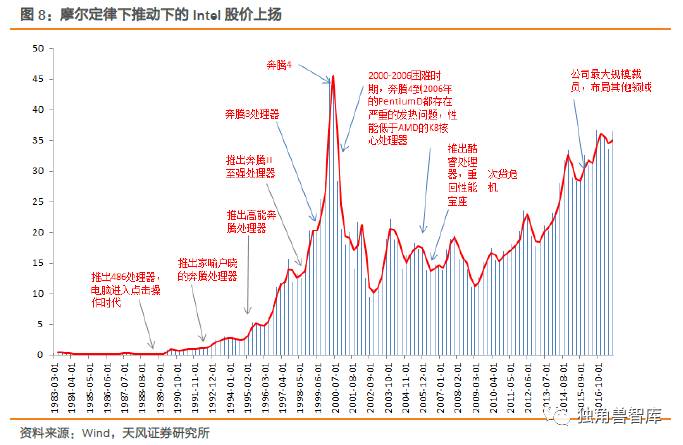
冯诺伊曼架构带来了计算体系的建立并通过Intel实现了最大化,但从本质上说,英特尔参与的是机器时代的兴起和计算芯片价值体现。但时至今日,在人口红利消散,PC渗透率达到稳定阶段,依托于PC时代的处理器芯片进入了稳定常态。英特尔在总产品收入提升的情况下,PC端提供的收入增长机会停滞。处理器依靠摩尔定律不断推经延续生命力,但在应用增长乏力的阶段缺乏爆发式的再增长。PC时代的处理器设计遵从了下游应用驱动上游芯片的实质。
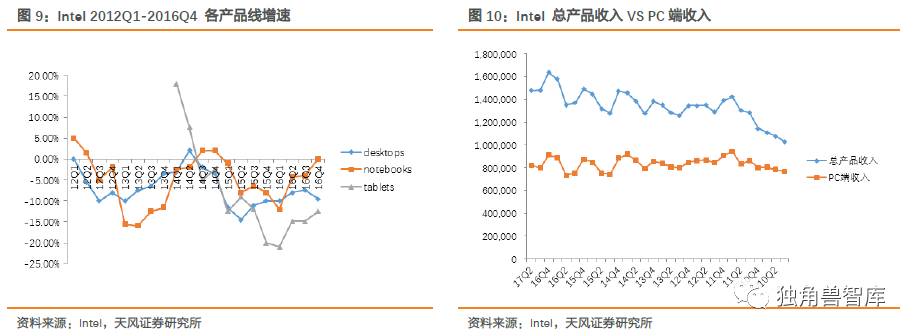
进入2010年后,英特尔的处理器增速同半导体行业基本协同一致,毫无疑问超越行业增速的增长已经需要新的应用拉动。摩尔定律支撑了10多年的快速增长再出现边际改善的增长需要重新审视。

2.2.ARM——开放生态下移动时代的新王加冕
本节重点阐述ARM在移动时代的芯片架构产品以及此架构下公司以及行业的变化。
2.2.1.ARM公司简介
ARM公司是全球领先的半导体知识产权(IP)提供商,专门从事基于RISC技术芯片设计开发,并因此在数字电子产品的开发中处于核心地位。公司的前身Acorn于1978年在伦敦正式成立。1990年ARM从Acorn分拆出来。得益于20世纪90年代手机的快速发展,基于ARM技术的芯片出货量飞速增长,并于2017年宣布正式达成1000亿芯片出货量的里程碑。2016年7月,日本软银以320亿美元收购了ARM。
ARM本身不直接从事芯片生产,只设计IP,包括指令集架构、微处理器、图形核心和互连架构,依靠转让设计许可由合作公司生产各具特色的芯片,目前它在世界范围有超过1100个的合作伙伴。
ARM的创新型商业模式为公司带来了丰厚的回报率:它既使得ARM技术获得更多的第三方工具、制造、软件的支持,又使整个系统成本降低,使产品更容易进入市场被消费者所接受,更具有竞争力。正因为ARM的IP多种多样以及支持基于ARM的解决方案的芯片和软件体系十分庞大,全球领先的原始设备制造商(OEM)都在广泛使用ARM技术,因此ARM得以在智能手机、平板上一枝独秀,全世界超过95%的智能手机都采用ARM架构。
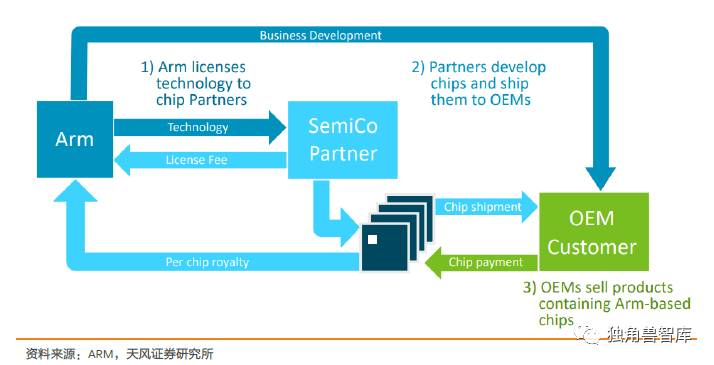
图12:ARM的商业模式
2.2.2.ARM架构——重新塑造移动智能时代
ARM沿用了冯诺伊曼架构,在性能和功耗上做到了更加平衡。在底层架构没有发生根本性变革的情况下,在架构的横向延伸上寻找到了技术的转换,从而实现了智能手机时代移动端的产品阶跃。
处理器架构在根源上看ARM延续了X86的底层架构。正如我们在之前讨论架构时指出,处理器一般分为取指令,译码,发射,执行,写回五个步骤。而我们说的访存,指的是访问数据,不是指令抓取。访问数据的指令在前三步没有什么特殊,在第四步,它会被发送到存取单元,等待完成。与X86不同的是在指令集方面,ARM架构过去称作进阶精简指令机器(AdvancedRISCMachine),更早时期被称作AcornRISCMachine,是32位精简指令集(RISC)处理器架构,被广泛地使用在嵌入式系统设计中。在应用场景上有所不同。
ARM指令集架构的主要特点:一是体积小、低功耗、低成本、高性能,因此ARM处理器非常适用于移动通讯领域;二是大量使用寄存器且大多数数据操作都在寄存器中完成,指令执行速度更快;三是寻址方式灵活简单,执行效率高;四是指令长度固定,可通过多流水线方式提高处理效率。
图13:ARM架构的发展

2.2.3.生态的建立和商业模式的转变——ARM重塑了行业
ARM的商业模式值得真正的关注。ARM通过授权和版税来赚取收入。使用ARM的授权,跟据流片的次数,可以付一次流片的费用,也可以买三年内无限次流片,更可以永久买断。芯片量产后,根据产量,会按百分比收一点版税。Intel通过售卖自己的芯片来赢得终端客户和市场,而ARM则是通过授权让全世界的芯片制造商使用自家的产品来推广。ARM的商业模式之所以在智能手机时代能够推广,是因为移动端的生态更为开放,自上而下的生态建立,不仅是芯片开发者,也包括软件开发者,都被构建在生态的范围内。
智能移动设备上包含多件ARM的处理器/技术,每当智能手机上新增一个功能时,就为新的ARM知识产权带来了新的机会。2016年,ARM在移动应用处理器(包括智能手机、平板电脑和笔记本电脑)上,根据量的测算,其市场份额高达90%,同时ARM估计移动应用处理器规模将从2016年的200亿美元增长到2025年的300亿美元。
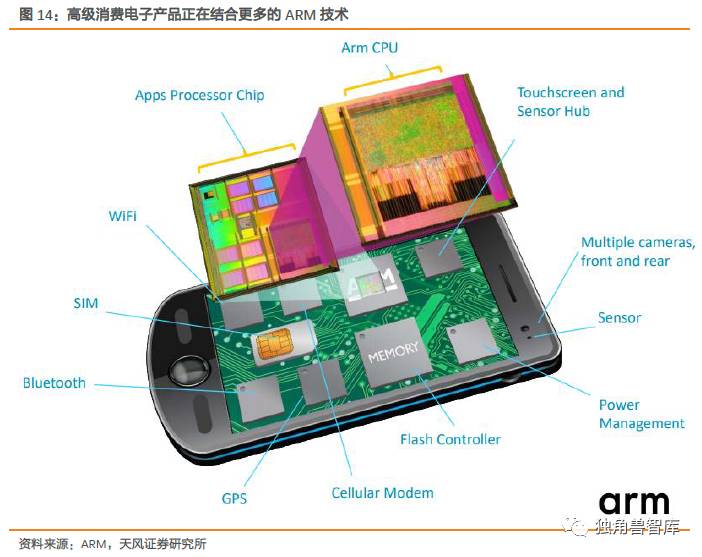
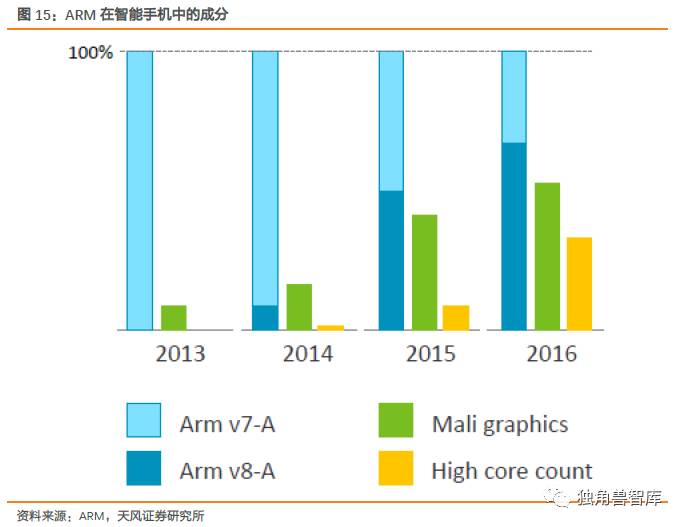
2016年,ARM各项技术在智能手机领域都有良好的渗透率:ARMv7-A技术早已完全渗入,ARMv8-A技术渗透率达到70%,Maligraphics达到50%,高核数技术(highcorecount)则为35%.
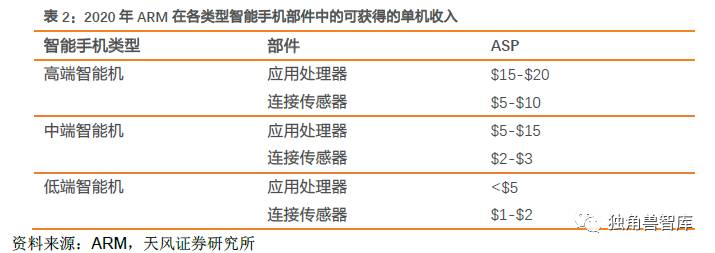
根据ARM的预测,到2025年为止,智能手机设备的CAGR为3%左右,而ARM在这一板块的专利收入将会以大于5%的CAGR上涨。
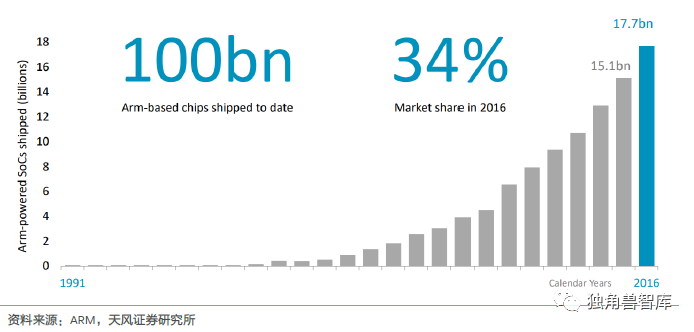
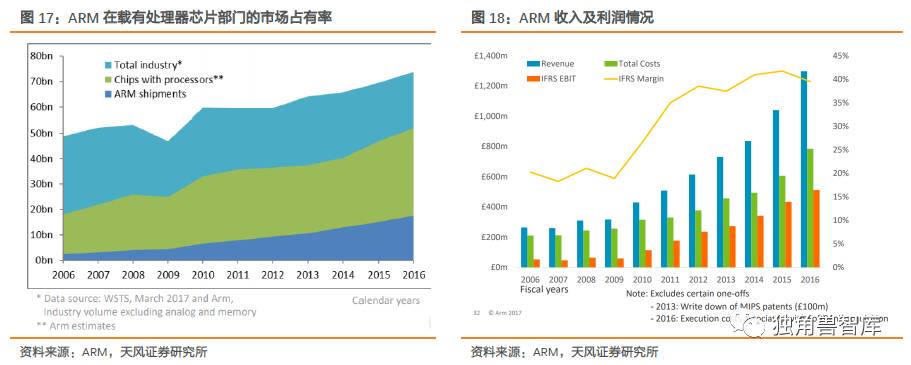
ARM的累计出货量已经超过1000亿支,2016年全年发出的基于ARM技术芯片达到177亿,发货量在过去5年时间中CAGR将近15%。ARM的增长完美契合了智能手机的快速增长10年。
图16:基于ARM芯片的出货量
3.人工智能芯片——新架构的异军突起
观察人工智能系统的搭建,以目前的架构而言,主要是以各种加速器来实现深度学习算法。本章讨论各种加速器的形式和实现,并探讨加速器变革下引发的行业深层次转变,并从2个维度给出详细的测算人工智能芯片的潜在空间。
首先我们必须描述人工智能对芯片的诉求,深度学习的目标是模仿人类神经网络感知外部世界的方法。深度学习算法的实现是人工智能芯片需要完成的任务。在算法没有发生质变的前提下,追根溯源,所有的加速器芯片都是为了实现算法而设计。
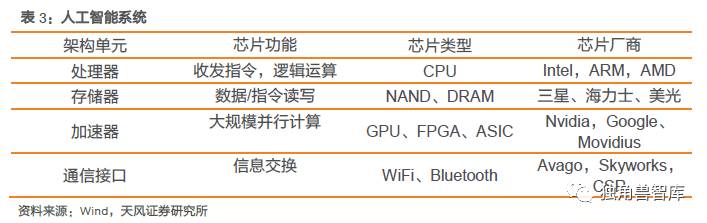
我们整理了人工智能芯片相关的类型和产业链公司,传统的芯片厂商/生态的建立者/新进入者。传统的芯片制造厂商:Intel,Nvidia和AMD。他们的优势在于在已有架构上对人工智能的延伸,对于硬件的理解会优于竞争对手,但也会困顿于架构的囹圄;2上层生态的构建者进入芯片设计,比如苹果和Google,优势在于根据生态灵活开发定制各类ASIC,专用性强;新进入者,某些全新的架构比如神经网络芯片的寒武纪,因为是全新的市场开拓,具有后发先至的可能。新进入者的机会,因为是个全新的架构机会,将有机会诞生独角兽。

3.1.GPU——旧瓶装新酒
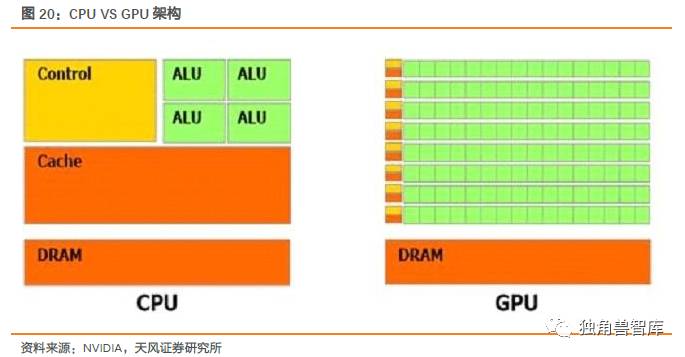
GPU使用SIMD(单指令多数据流)来让多个执行单元以同样的步伐来处理不同的数据,原本用于处理图像数据,但其离散化和分布式的特征,以及用矩阵运算替代布尔运算适合处理深度学习所需要的非线性离散数据。作为加速器的使用,可以实现深度学习算法。但注意的是,GPU架构依然基于冯诺伊曼。
我们以GPU和CPU的对比来说明GPU所具有的架构特点。GPU由并行计算单元和控制单元以及存储单元构成GPU拥有大量的核(多达几千个核)和大量的高速内存,擅长做类似图像处理的并行计算,以矩阵的分布式形式来实现计算。同CPU不同的是,GPU的计算单元明显增多,特别适合大规模并行计算。
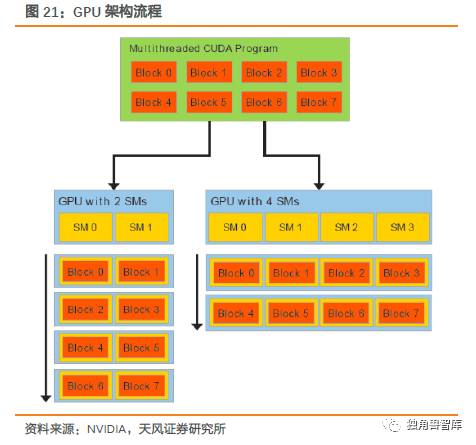
注意GPU并行计算架构,其中的流处理器组(SMs)类似一个CPU核,多个流处理器组可实现数据的同时运算。因此,GPU主要适用于在数据层呈现很高的并行特性(data-parallelism)的应用。
CPU和GPU本身架构方式和运算目的不同导致了CPU和GPU之间的不同,主要不同点列举如下

深度学习是利用复杂的多级「深度」神经网络来打造一些系统,这些系统能够从海量的未标记训练数据中进行特征检测。因为GPU可以平行处理大量琐碎信息。深度学习所依赖的是神经系统网络——与人类大脑神经高度相似的网络——而这种网络出现的目的,就是要在高速的状态下分析海量的数据。GPU擅长的是海量数据的快速处理。
GPU的特征决定了其特别适合做训练。机器学习的广泛应用:海量训练数据的出现以及GPU计算所提供的强大而高效的并行计算。人们利用GPU来训练这些深度神经网络,所使用的训练集大得多,所耗费的时间大幅缩短,占用的数据中心基础设施也少得多。GPU还被用于运行这些机器学习训练模型,以便在云端进行分类和预测,从而在耗费功率更低、占用基础设施更少的情况下能够支持远比从前更大的数据量和吞吐量。与单纯使用CPU的做法相比,GPU具有数以千计的计算核心、可实现10-100倍应用吞吐量,因此GPU已经成为数据科学家处理大数据的处理器。
3.1.1.GPU芯片王者——NVIDIA
NVIDIA是一家以设计GPU芯片为主业的半导体公司,其主要产品从应用领域划分,包括GPU(如游戏图形处理器GeForceGPU,深度学习处理器Tesla,图形处理器GRID等)和TegraProcessor(用于车载,包括DRIVEPX和SHIELD)等。GPU芯片构成公司最主要收入来源,2017年上半年,GPU贡献收入34.59亿美元,占公司总收入的83%;TegraProcessor贡献收入6.65亿美元,占比16%,其他部分贡献收入1%。
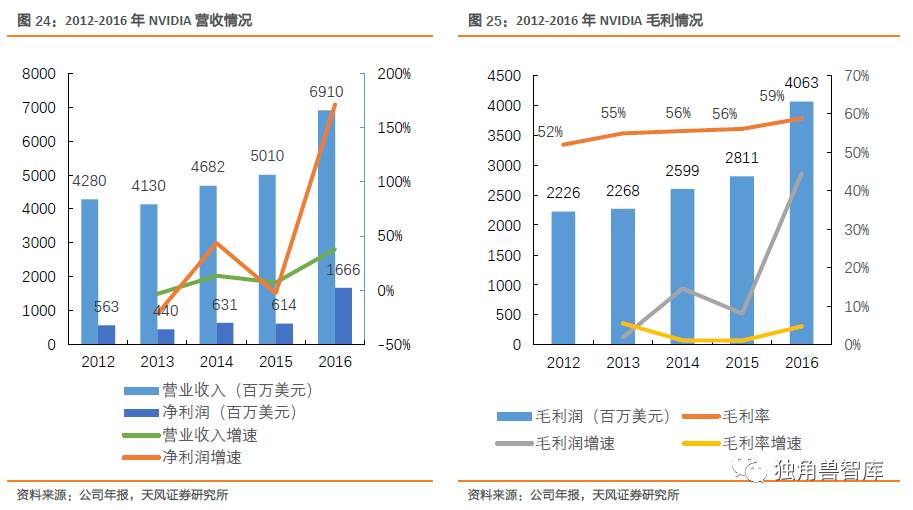
公司业绩稳定,营业收入除2013年略有下降外,2012-2016年均实现稳步增长,从42.80亿美元增至69.10亿美元,CAGR为10.05%;2016年公司实现净利16.66亿美元,相较于2012年的5.63亿美元,CAGR达24.23%。毛利润方面,公司毛利润从2012年的22.26亿美元增至2016年的40.63亿美元,实现稳步增长,毛利率维持在50%以上。
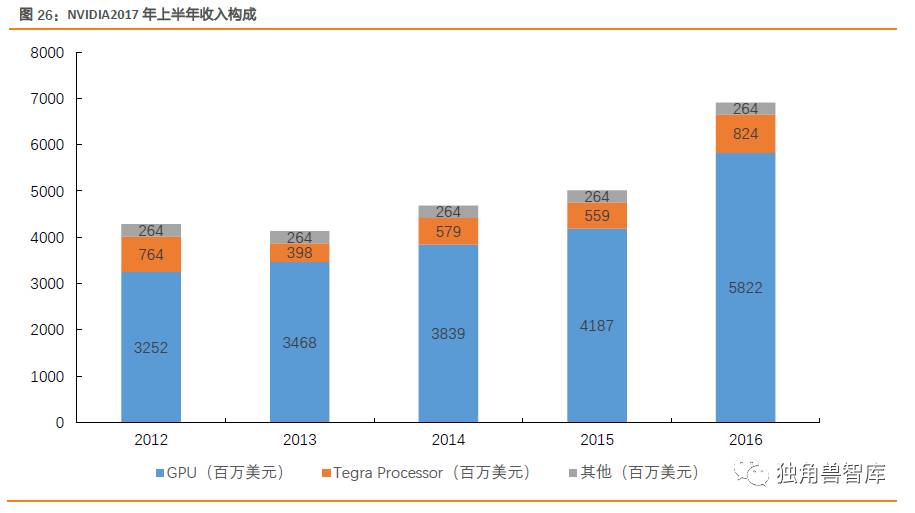
从收入构成来看,公司GPU芯片业务从2012年的32.52亿美元增至2016年的58.22亿美元,实现稳步增长,GPU业务在收入结构中占比稳定在76%以上。
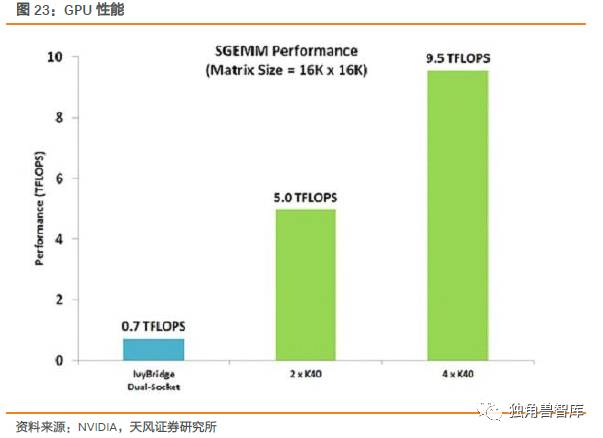
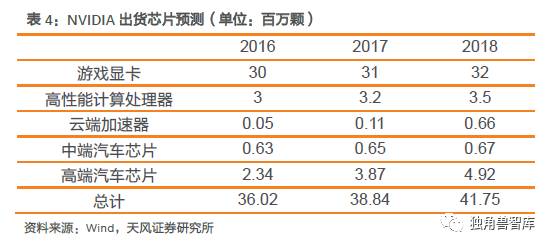
在高性能计算机、深度学习、人工智能等领域,NVIDIA的GPU芯片有十分关键的作用。NVIDIA的CUBA技术,大幅度提高了纯CPU构成的超级计算机的性能。人工智能和深度学习需要大量的浮点计算,在高性能计算领域,GPU需求在不断增强。目前NVIDIA的高性能显卡已经占有84%的市场份额。亚马逊的AWS,Facebook,Google等世界一级数据中心都需要用NVIDIA的Tesla芯片,随着云计算和人工智能的不断发展,我们认为NVIDIA的GPU芯片业务在未来将继续维持增长态势,我们分拆每个领域的出货量,预计将从2016年的3602万颗增至2018年的4175万颗。
3.2.FPGA——紧追GPU的步伐
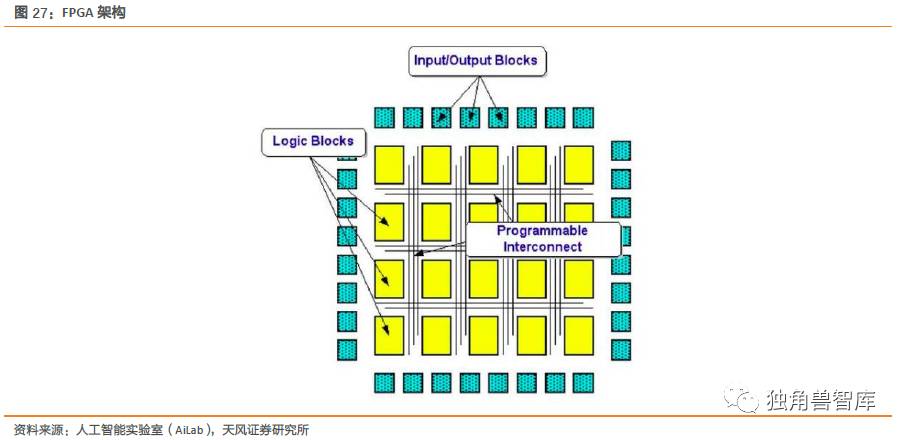
FPGA是用于解决专用集成电路的一种方案。专用集成电路是为特定用户或特定电子系统制作的集成电路。人工智能算法所需要的复杂并行电路的设计思路适合用FPGA实现。FPGA计算芯片布满“逻辑单元阵列”,内部包括可配置逻辑模块,输入输出模块和内部连线三个部分,相互之间既可实现组合逻辑功能又可实现时序逻辑功能的独立基本逻辑单元。注意FPGA与传统冯诺伊曼架构的最大不同之处在于内存的访问。FPGA在本质上是用硬件来实现软件的算法,因此在实现复杂算法方面有一些难度。

架构方面,FPGA拥有大量的可编程逻辑单元,可以根据客户定制来做针对性的算法设计。除此以外,在处理海量数据的时候,FPGA相比于CPU和GPU,独到的优势在于:FPGA更接近IO。换句话说,FPGA是硬件底层的架构。比如,数据采用GPU计算,它先要进入内存,并在CPU指令下拷入GPU内存,在那边执行结束后再拷到内存被CPU继续处理,这过程并没有时间优势;而使用FPGA的话,数据I/O接口进入FPGA,在里面解帧后进行数据处理或预处理,然后通过PCIE接口送入内存让CPU处理,一些很底层的工作已经被FPGA处理完毕了(FPGA扮演协处理器的角色),且积累到一定数量后以DMA形式传输到内存,以中断通知CPU来处理,这样效率就高得多。
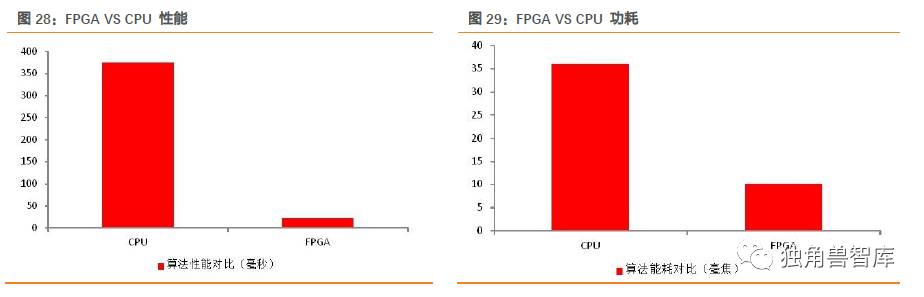
性能方面,虽然FPGA的频率一般比CPU低,但CPU是通用处理器,做某个特定运算(如信号处理,图像处理)可能需要很多个时钟周期,而FPGA可以通过编程重组电路,直接生成专用电路,加上电路并行性,可能做这个特定运算只需要一个时钟周期。比如一般CPU每次只能处理4到8个指令,在FPGA上使用数据并行的方法可以每次处理256个或者更多的指令,让FPGA可以处理比CPU多很多的数据量。举个例子,CPU主频3GHz,FPGA主频200MHz,若做某个特定运算CPU需要30个时钟周期,FPGA只需一个,则耗时情况:CPU:30/3GHz=10ns;FPGA:1/200MHz=5ns。可以看到,FPGA做这个特定运算速度比CPU块,能帮助加速。
FPGA相对于CPU与GPU有明显的能耗优势,主要有两个原因。首先,在FPGA中没有取指令与指令译码操作,在Intel的CPU里面,由于使用的是CISC架构,仅仅译码就占整个芯片能耗的50%;在GPU里面,取指令与译码也消耗了10%~20%的能耗。其次,FPGA的主频比CPU与GPU低很多,通常CPU与GPU都在1GHz到3GHz之间,而FPGA的主频一般在500MHz以下。如此大的频率差使得FPGA消耗的能耗远低于CPU与GPU。
Intel167亿美元收购Altera,IBM与Xilinx的合作,都昭示着FPGA领域的变革,未来也将很快看到FPGA与个人应用和数据中心应用的整合
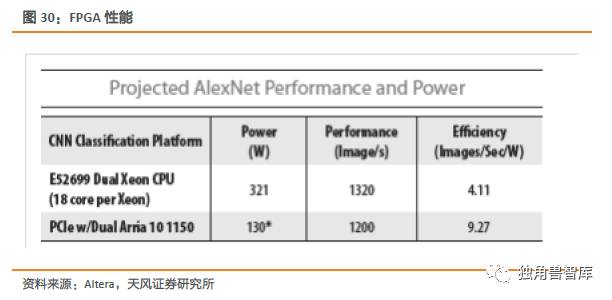
根据Altera内部文件显示,Altera很早就在研发使用FPGA针对深度学习算法的应用,并在2015年Intel的论坛上展示了产品的性能。结论是在功耗和性能上相对同等级的CPU,有较大的优势。CPU+FPGA在人工智能深度学习领域,将会是未来的一个重要发展方向
3.3.ASIC——定制化的专用人工智能芯片
ASIC(专用定制芯片)是为实现特定要求而定制的芯片,具有功耗低、可靠性高、性能高、体积小等优点,但不可编程,可扩展性不及FPGA,尤其适合适合高性能/低功耗的移动端。目前,VPU和TPU都是基于ASIC架构的设计。
我们梳理针对图像和语音这两方面的人工智能定制芯片,目前主要有专用于图像处理的VPU,以及针对语音识别的FAGA和TPU芯片。

3.3.1.VPU——你是我的眼
VPU是专门为图像处理和视觉处理设计的定制芯片。根据特定算法来实现定制化的芯片架构,实现特定的图像处理能力,提高效率,是VPU的基础理念。集成在摄像头中的VPU,直接对输入图像进行识别理解,消除了存储器的读写操作。相较主流的移动处理芯片(集成GPU的SoC),VPU的尺寸更小,视觉处理运算的效能更高。
以Movidiu公司产品Myriad2为例,VPU芯片包括接口电路(Interfaces)、硬件加速器(HardwareAccelerators),矢量处理器阵列(ArrayofVectorProcessors),精简指令集的CPU(RISCCPU)等部分。接口电路支持多路摄像头传感器等外部设备,硬件加速器可以迅速的提高运算处理速度,矢量处理器阵列专门针对机器视觉,精简指令集的CPU(RISCCPU)主要进行任务分配。


VPU能够处理各种不同的任务:利用立体摄像机的数据处理深度信息,还有来自声纳传感器的近距离、空间定位,以及用于识别和跟随人的先进光流;它也可以成为虚拟现实、现实增强技术的核心部分,让智能手机以及更便宜的头戴产品达成现如今较为昂贵的系统才能完成的目标。如HTCVive,这台设备需要比较诡异的头戴式护目镜,还需要两个激光盒子绘制整个空间,并追踪用户的运动。而装备VPU通过移动设备或者耳机就能做到这一点;此外,具备深度学习能力的VPU,能够在设备本地就能利用强悍的图像识别计算,设备能够看见和理解周围的世界,不需要检索云端就能做到,避免了延迟的问题。
目前,VPU的应用市场有机器人、物联网、智能穿戴设备、智能手机、无人驾驶、无人机等。

结合光学,在前端实现智能处理识别运算的芯片,正在移动端不断渗透提升。在苹果推出带3D感应功能的结构光方案之后,我们预计会深度推动市场在向具有人工智能功能的特定芯片端迈进。VPU实现了在移动设备端具备PC级别的图像处理能力。通常来说这类图像处理芯片能耗非常高,而且也需要电脑支持,但通过VPU,成功将高级的图像处理方案移植到移动设备中。在前端设备中引入带有AI功能的新架构芯片将带来移动端价值量的提升和潜在的变革。

3.3.1.TPU——Google的野心
TPU(TensorProcessingUnit)是谷歌的张量处理器,它是一款为机器学习而定制的芯片,经过了专门深度机器学习方面的训练,它有更高效能。
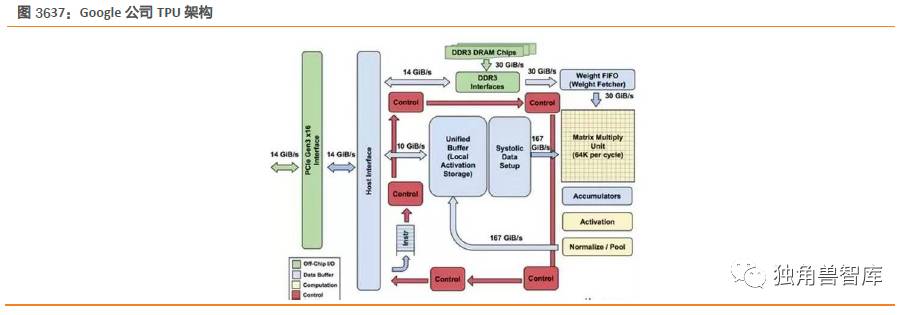
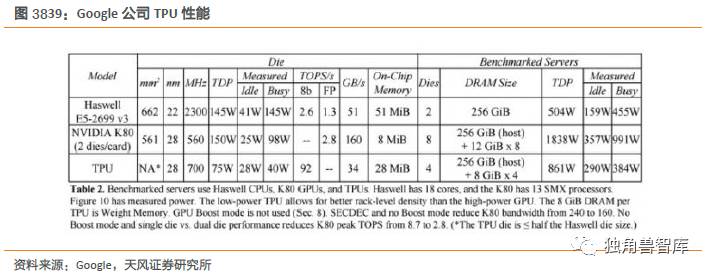
Google对GPU,IntelXeonE5v3CPU和TPU进行了性能对比。在Google的测试中,使用64位浮点数学运算器的18核心运行在2.3GHz的HaswellXeonE5-2699v3处理器能够处理每秒1.3TOPS的运算,并提供51GB/秒的内存带宽;Haswell芯片功耗为145瓦,其系统(拥有256GB内存)满载时消耗455瓦特。相比之下,TPU使用8位整数数学运算器,拥有256GB的主机内存以及32GB的内存,能够实现34GB/秒的内存带宽,处理速度高达92TOPS,这比Haswell提升了71倍,此外,TPU服务器的热功率只有384瓦。但TPU是专为Google深度学习语言TensorFlow开发的一种芯片,不具有可扩展性。
3.4.人工神经网络芯片
从底层架构的变革角度看,最前沿的革新以深度学习原理打造的人工神经网络芯片。人工神经网络是模仿生物神经网络的计算架构的总称,由若干人工神经元节点互连而成,神经元之间通过突触连接。每个神经元其实是一个激励函数,突触则是记录神经元间联系的强弱权值。
神经网络是多层的,一个神经元函数的输入由与其相连的上一个神经元的输出以及连接突触权重共同决定。所谓训练神经网络,就是通过不断自动调整神经元之间突触权重的过程,直到输出结果稳定正确。然后在输入新数据时,能够根据当前的突触权重计算出输出结果。以此来实现神经网络对已有知识的“学习”。神经网络中存储和处理是一体化的,中间计算结果化身为突触的权重。
冯诺伊曼架构的传统处理器处理神经网络任务时效率低下,是由其本身的架构限制决定的。冯诺伊曼架构存储和处理分离,基本运算为算术和逻辑操作,这两点决定了一个神经元的处理需要成百上千条指令才能完成。以AlphaGo为例,总共需要1202个CPU+176个CPU。

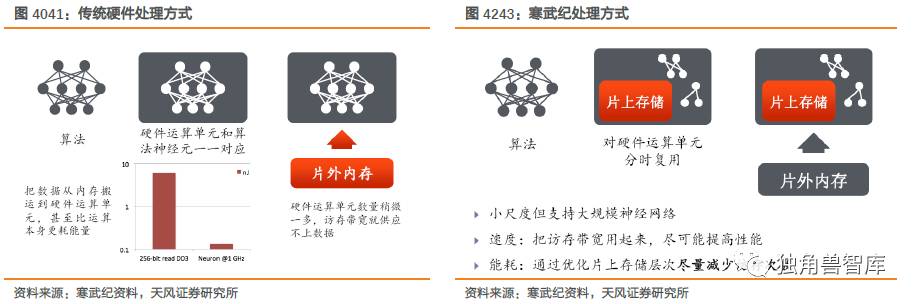
3.4.1.寒武纪——真正的不同
真正打造的类脑芯片,寒武纪试图将通过低功耗高性能的架构重塑,颠覆已有的冯诺伊曼架构,实现在移动端/云端的加速器实现。
从寒武纪披露的数据来看,其性能远超GPU和CPU。
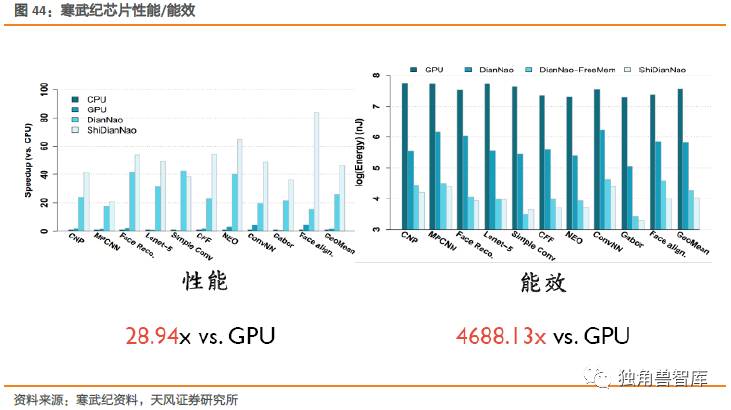
寒武纪试图将代表性智能算法的处理速度和性能功耗比提升一万倍,在移动端实时完成图像语音和文本的理解和识别,更为重要的是通过实时训练,还能不断进化提升能力,真正实现超越。
图45:终端和移动端

4.从2个维度测算人工智能芯片空间
我们在前二章重点讨论了Intel和ARM的历史发展,认为冯诺伊曼架构带来了计算体系的建立并通过Intel实现了最大化;ARM通过共享IP的商业模式带来了更开放的生态体系,实现了软硬件的结合延伸了人类的触角。同时我们认为人工智能芯片将有可能在摩尔定律放缓维度下引发芯片底层架构重构的变革。
本章我们重点讨论人工智能芯片的市场空间测算,我们从两个维度来进行估算,给出详细的拆解。
维度一:市场规模反推芯片空间
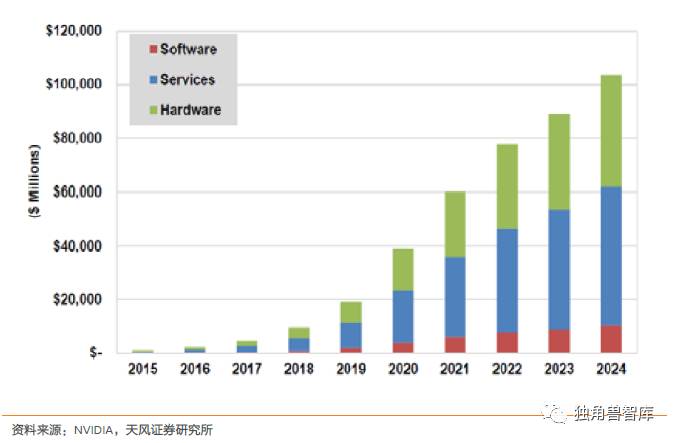
根据Nvidia官方给出的资料统计,到2020年,由软件、硬件、服务三者组成的人工智能市场将达到400亿美元,其中硬件占到1/3强,为160亿美元。而硬件的核心是芯片。我们估算硬件的BOM,芯片会占到60%,芯片空间将达到96亿美元。
图46:人工智能市场规模
维度二:详细拆分云端/移动端所需人工智能加速器的BOM
人工智能芯片从用途来看,分为云端加速器芯片和终端(包括智能手机、无人驾驶汽车、)智能芯片。我们基于这两个场景,给出结论,预测至2021年,人工智能芯片市场有望达到111亿美元,CAGR达20.99%。
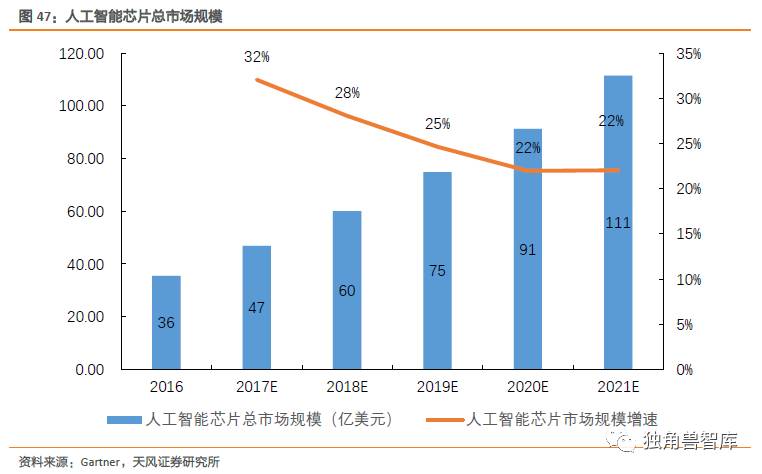
云端加速器详细拆解
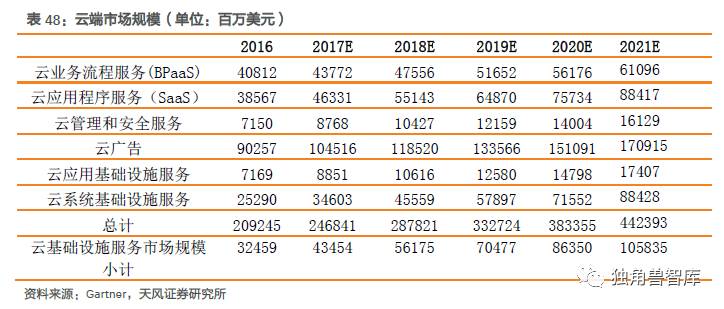
具体来看云端方面,根据Gartner的统计,到2020年,全球云计算市场规模将达到3834亿美元,其中,云基础设施服务市场规模达863.5亿美元。
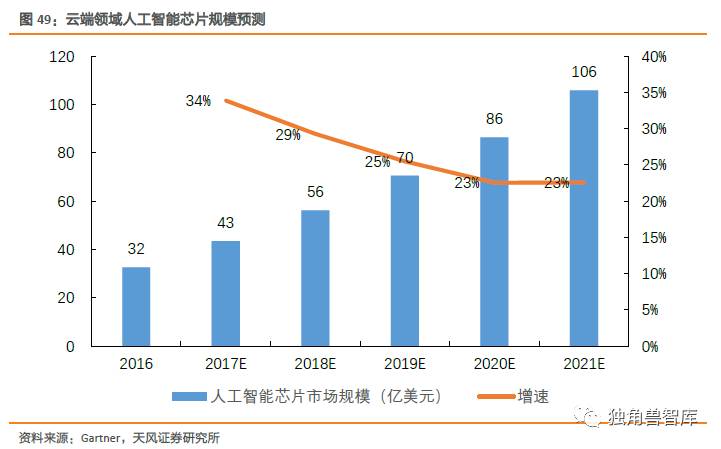
我们假设深度学习相关基础设施占云基础设施的20%,而其中人工智能芯片占深度学习相关硬件BOM的50%,据此,我们测算云端方面人工智能芯片市场规模将从2016年的32亿美元增至2021年的106亿美元,CAGR达21.77%。
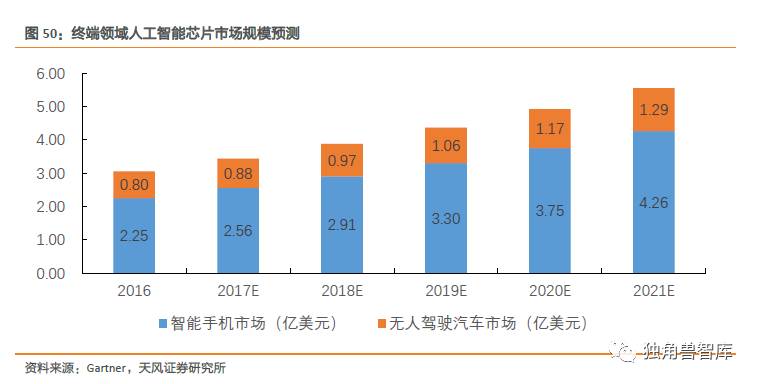
终端加速器市场详细拆解
终端方面,目前人工智能芯片主要应用领域是智能手机、无人驾驶汽车和无人机。我们假设:
1)智能手机全球出货量年均增速3.3%,主处理器平均价格15美元,带人工智能芯片模块占智能手机主处理器BOM的10%
2)带人工智能功能的智能手机渗透率从2018的10%提升到2020年的40%
3)无人驾驶汽车市场规模年均增速10%。因无人驾驶汽车以及其芯片市场均尚未成型,目前成本较高,我们假设芯片成本占总成本的20%,人工智能芯片占处理器成本的10%。据此预测终端领域人工智能芯片的市场规模。
据此我们预测,在终端领域,至2021年,全球人工智能芯片市场规模由2016年的3.05亿美元增至5.55亿美元,CAGR为10.49%。其中,智能手机市场中,人工智能芯片由2016年的2.25亿美元增至2021年的4.26亿美元,CAGR为11.24%;无人驾驶汽车市场中,人工智能芯片由2016年的0.80亿美元增至2021年的1.29亿美元,CAGR为8.27%。
5.重点标的
台积电:无论是何种架构的人工智能芯片,都是依赖于台积电最先进制程的代工工艺,在全球只有台积电能够提供HPC(高性能计算芯片)的工艺平台上,行业的卡位优势已然确立,确定性受益标的。
Intel:收购Altera,收购Movidius,CPU+FPGA方案,Intel在人工智能领域的布局长远,而通过我们的测算,服务器端将是人工智能芯片未来行业渗透和消耗的重点,而Intel在服务器端已经有深厚不可撼动的优势。
NVIDIA:目前人工智能芯片领域的领跑者,深度学习训练领域的唯一方案选择。有完整的生态布局,针对云端+汽车自动驾驶,百亿美元新增市场的竞争者。
寒武纪:寒武纪试图将代表性智能算法的处理速度和性能功耗比提升一万倍,在移动端实时完成图像语音和文本的理解和识别,更为重要的是通过实时训练,还能不断进化提升能力,真正实现超越。
富瀚微:国内上市公司智能视频监控领域的前端芯片方案解决商,在前端芯片集成一定的智能算法功能处理。
北京君正:积极进入视频监控领域的芯片方案解决商,曾经的MIPS方案芯片设计商,有芯片架构层基因,对标Movidius。
全志科技:SoC芯片方案解决商,未来能将AI算法模块嵌入SoC之中。










