基础准备
前面我们介绍了Logistic回归分析的基础原理和运用SPSS进行二元Logistic回归分析的具体过程,可以点击下面蓝字回顾:
今天我们介绍,当遇到Logistic回归分析中自变量的测量尺度不统一时,如何解决。前面介绍多重线性回归分析时,给大家阐述过测量尺度不统一的含义,例如研究不同学历对收入的影响,如果定义的学历水平1代表初中,2代表高中、3代表本科、4代表硕士、5代表博士,虽然高中和初中(2-1),硕士和本科(4-3)的数值差距都是1,但是这两个1对应的收入的差距可能是完全不同的,也就是说学历变量中的数值差距测量不出收入的数值差距,也就是测量尺度不统一。
遇到测量尺度不统一的分类自变量,如果想放入回归模型中分析,有两种方法处理:
第一种就是前面介绍的最优尺度变换(回顾:)。它的分析思路是通过某种方法,对分类变量进行变换,为每个类别给予一个适当的量化评分,该评分的高低能够反映不同类别之间的真实差距。例如,对企业绩效考核,“优”为2分,“良”为1分,“中”为0. 5分,这就说明等级从良(1分)变为优(2分)时,对因变量数值的影响大约是从中(0.5分)变为良(1分)的2倍。
第二种是采用哑变量拟合,然后根据分析结果考虑对结果进行简化。今天要介绍的就是Logistic回归分析中哑变量的设置及分析结果解读。继续沿用上一篇介绍二元Logistic回归分析时的例子来介绍今天的内容。
哑变量的含义
某医学研究机构研究孕妇分娩低体重婴儿的原因,根据经验,研究机构初步筛选以下变量纳入分析,并希望建立以产妇是否分娩低体重婴儿为因变量,下面这些因素为自变量的二元Logistic回归方程,作为今后判断哪些产妇需要重点关注的预测工具。
产妇生产前体重;
产妇年龄;
产妇是否吸烟;
产妇之前早产次数;
产妇是否患有高血压;
产妇民族;
这些纳入考虑自变量的数据种类齐全,有连续型变量(年龄、体重和早产次数)、二分类变量(是否高血压和吸烟)、无序多分类变量(民族)。如果不对这些自变量进行设置,直接纳入模型,SPSS软件默认所有自变量为连续性变量。例如,不同民族变量的赋值为1,2,3,这些数值仅是民族代码,并不意味着汉族、畲族、其它民族间存在大小关系,也就是说,这些数值纳入模型不能代表产妇娩出低体重儿概率的会按数值123的增加而线性成比例的增加。如果将分类变量的编码数值代入到模型中分析,实际上就是强行规定不同类别对因变量的影响强度是等比例的,这显然会导致更大的误差。
面对以上情况,必须将原始的分类变量转化为数个哑变量,每个哑变量只代表某两个类别或若干个类别间的差距,这样得到的回归结果才能有明确而合理的实际意义。对于取值有n个水平的分类自变量,其中1个水平作为参照水平,因此会产生n-1个哑变量。例如上面提到的民族自变量,可以产生两个哑变量,如果选取其它民族作为参照变量,那么第一个哑变量的回归系数代表汉族与其它民族的对比结果;第二个哑变量的回归系数代表畲族与其它民族的对比结果;两个回归系数的差值则代表汉族与畲族之间的差异。
范例分析
沿用上面的例子,某医学研究机构研究孕妇分娩低体重婴儿的原因,根据经验,研究机构初步筛选以下变量纳入分析,包括产妇生产前体重;产妇年龄;产妇是否吸烟;产妇之前早产次数;产妇是否患有高血压;产妇民族;部分数据如下:
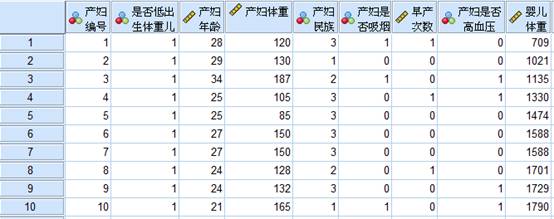
(例题数据文件已经上传到QQ群,群号请见文章底部温馨提示)
分析思路
因为本篇文章介绍给大家的是哑变量的设置以及结果解读,所以在接下来的分析中只将产妇民族纳入二元Logistic回归模型,包含其它变量的分析将会在介绍自变量筛选和模型解读修正的文章中介绍。
分析步骤
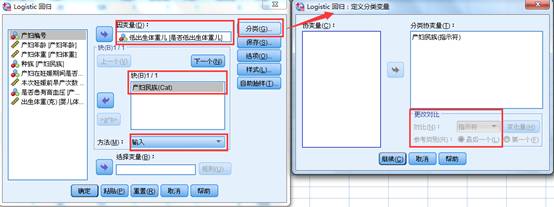
选择菜单【分析】-【回归】-【二元Logistic】,是否生产低体重婴儿选为因变量,将产妇民族选择自变量框。然后点击分类按钮,将产妇民族选入分类协变量。在下方的更改对比中,我们保持指示符。
结果解释
1、分类变量编码;
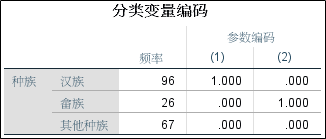
分类变量编码表格包含的内容是哑变量的成分组成。参数编码显示产生了两个哑变量,第一个哑变量代表汉族对分娩低体重婴儿的概率影响;第二个哑变量则代表畲族;其它种族的成分都是0,说其它种族在这里是参照水平。
2、哑变量在方程中的作用
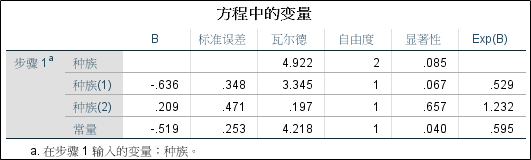
第一行的种族代表对民族这个分类变量的总体检验结果,显著性为0.085,大于0.05,说明民族这个分类变量对于分娩低体重婴儿的影响是不显著的,因此下一步可以不考虑这个自变量。同时,两个哑变量(1)和(2)也有显著性检验结果,注意,它们的B(回归系数)是相对与其它民族来说的。
如果总体检验是显著的,但是哑变量的检验结果是有的显著,有的不显著,那应该怎么办呢?原则上仍然应当在模型中纳入所有的哑变量,以保证哑变量所代表含义的正确性。否则,剔除部分哑变量将会导致参照水平的变化,从而哑变量的具体含义也会发生改变。
参照水平的设置
SPSS中哑变量的设置很简单,但是分类变量中参照水平的设置可以有很多不同的方式。如下图所示:对比可以有指示符、简单、差异、赫尔默特、重复、多项式、偏差等7种形式,它们的区别是什么呢?
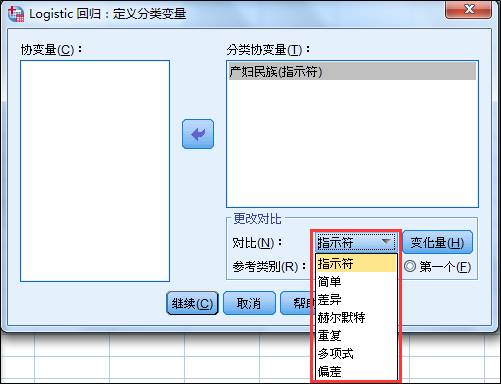
指示符:指定某一分类变量的参照水平。这时计算出来的哑变量参数是以该变量的最后一个或第一个水平作为参照水平(取决于下面的参考类别中选择的是最后一个还是第一个)。在本例中,参考类别为最后一个,所以以“其他种族”作为参照水平。
简单:计算得到的哑变量参数与指示符相同,区别在于两者的模型截距不同,指示符的截距就是参考水平对因变量的影响强度,而简单对比的截距则是三个水平的平均值。
差别:分类变量某个水平与其前面的所有水平的平均值进行比较。如2水平与1水平相比;3水平与1和2水平的平均值相比,以此类推。如果在某水平处系数变小且无统计学意义,说明在该水平处达到停滞状态。差别对比一般用于有序分类变量(如吸烟剂量,假设研究者将其作为无序多分类的自变量进行分析),对于无序分类变量则无实际意义。
赫尔默特:分类变量某水平与其后面各水平平均值进行比较。如果在某水平系数增大且有统计学意义,说明该分类变量自该水平起开始对因变量产生影响。同样适用于有序的分类变量。
重复:分类变量的各水平与其相邻的后面一个水平比较,以最后一个水平为参照水平。
多项式:仅用于数字型的分类变量。无效假设是假设各水平是等距离的(可以是线性的关系,也可以是立方、四次方的关系)。例如年龄每增加5岁,娩出低出生体重儿的危险增加幅度是一样的,但实际情况常常与此相反,如在20岁与30岁年龄段,年龄都增加5岁,所增加的娩出低出生体重儿的危险肯定是不一样的,具体情况需根据各人的研究课题。
离差:除了所规定的参照水平外,其余每个水平均与总体水平相比。此时每个水平的回归系数都是相对于总体水平而言的改变量。
所有例题的数据文件都会上传到QQ群中,需要对照练习的朋友可以前往下载,QQ群号见下方温馨提示。
温馨提示:











