Ripgrep 是命令行下一个基于行的搜索工具,
RipGrep 使用 Rust 开发,可以在多平台下运行,支持 Mac、Linux 和 Windows 等平台。
RipGrep 与 The Silver Searcher、Ack 和 GNU Grep 的功能类似。
RipGrep 官方号称比其它类似工具在搜索速度上快上 N 倍,VSCode 也从
1.11 版本开始默认将 RipGrep 做为其搜索工具,由此其功能强大可见一斑。
项目地址:https://github.com/BurntSushi/ripgrep
Ripgrep 支持的一些特性
-
自动递归搜索 (grep 需要 -R)。
-
自动忽略 .gitignore 中的文件以及二进制文件和隐藏文件。
-
可以搜索指定文件类型,如:
rg -tpy foo
则限定只搜索 Python 文件,
rg -Tjs foo
则排除掉 JS 文件。
-
支持大部分 Grep 的 特性,例如:显示搜索结果的上下文、支持多个模式搜索、高亮匹配的搜索结果以及支持 Unicode 等。
-
支持各种文本编码格式,如:UTF-8、UTF-16、latin-1、GBK、EUC-JP、Shift_JIS 等。
-
支持搜索常见格式的压缩文件,如:gzip、xz、lzma、bzip2、lz4 等。
-
自动高亮匹配的结果。
Ripgrep 官方性能基准测试结果
|
Tool
|
Command
|
Line count
|
Time
|
|
ripgrep (Unicode)
|
rg -n -w '[A-Z]+_SUSPEND'
|
450
|
0.106s
|
|
git grep
|
LC_ALL=C git grep -E -n -w '[A-Z]+_SUSPEND'
|
450
|
0.553s
|
|
The Silver Searcher
|
ag -w '[A-Z]+_SUSPEND'
|
450
|
0.589s
|
|
git grep (Unicode)
|
LC_ALL=en_US.UTF-8 git grep -E -n -w '[A-Z]+_SUSPEND'
|
450
|
2.266s
|
|
sift
|
sift --git -n -w '[A-Z]+_SUSPEND'
|
450
|
3.505s
|
|
ack
|
ack -w '[A-Z]+_SUSPEND'
|
1878
|
6.823s
|
|
The Platinum Searcher
|
pt -w -e '[A-Z]+_SUSPEND'
|
450
|
14.208s
|
|
Tool
|
Command
|
Line count
|
Time
|
|
ripgrep
|
rg -L -u -tc -n -w '[A-Z]+_SUSPEND'
|
404
|
0.079s
|
|
ucg
|
ucg --type=cc -w '[A-Z]+_SUSPEND'
|
390
|
0.163s
|
|
GNU grep
|
egrep -R -n --include='*.c' --include='*.h' -w '[A-Z]+_SUSPEND'
|
404
|
0.611s
|
|
Tool
|
Command
|
Line count
|
Time
|
|
ripgrep
|
rg -w 'Sherlock [A-Z]\w+'
|
5268
|
2.108s
|
|
GNU grep
|
LC_ALL=C egrep -w 'Sherlock [A-Z]\w+'
|
5268
|
7.014s
|
Ripgrep 效果图
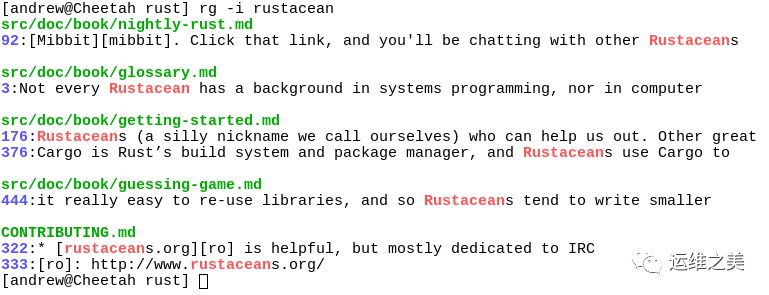
安装 Ripgrep
Ripgrep 具有良好跨平台特性,支持在 Linux、macOS、Windows 等多种平台下安装。官方也提供了各平台对应的二进制版本,下面我们以 Linux 平台为例使用二进制版本进行安装。
$ wget https://github.com/BurntSushi/ripgrep/releases/download/0.10.0/ripgrep-0.10.0-x86_64-unknown-linux-musl.tar.gz
$ tar xzvf ripgrep-0.10.0-x86_64-unknown-linux-musl.tar.gz
$ cp ripgrep-0.10.0-x86_64-unknown-linux-musl/rg /usr/local/bin/
如果你使用其它平台,方法与其类似。你可根据实际情况在官方下载页面下载对应版本进行安装。当然官方也提供了其它多种多样的安装方式,具体可参考官方安装文档。
Ripgrep 语法格式
USAGE:
rg [OPTIONS] PATTERN [PATH ...]
rg [OPTIONS] [-e PATTERN ...] [-f PATTERNFILE ...] [PATH ...]
rg [OPTIONS] --files [PATH ...]
rg [OPTIONS] --type-list command | rg [OPTIONS] PATTERN
ARGS: <PATTERN>
A regular expression used for searching. To match a pattern beginning with a
dash, use the -e/--regexp flag.
For example, to search for the literal '-foo', you can use this flag:
rg -e -foo
You can also use the special '--' delimiter to indicate that no more flags
will be provided. Namely, the following is equivalent to the above:
rg -- -foo <PATH>...
A file or directory to search. Directories are searched recursively. Paths specified on
the command line override glob and ignore rules.
这里我们把一些常用选项做下介绍。
|
选项
|
说明
|
备注
|
-A, --after-context
|
显示匹配内容后的
行。
|
会覆盖
--context
选项。
|
-B, --before-context
|
显示匹配内容前的
行。
|
会覆盖
--context
选项。
|
|
-b, --byte-offset
|
显示匹配内容在文件中的字节偏移。
|
和
-o
一起使用时只打印偏移。
|
|
-s, --case-sensitive
|
启用大小写敏感。
|
会覆盖
-i(--ignore case)
和
-S(--smart case)
选项。
|
--color
|
什么时候使用颜色,默认值为:auto。可选值有:never、auto、always、ansi。
|
如果
--vimgre
选项被使用,那么默认值是 never。
|
|
--column
|
显示匹配所在列数 (从 1 开始)。
|
如果不显示列号可用
--no-column
取消掉。
|
-C, --context
|
显示匹配内容的前面和后面的
行。
|
该选项会覆盖
-B
和
-A
选项。
|
--context-separator
|
在输出结果中分隔非连续的输出行 。
|
可以使用
\x7F
或
\t
,默认是
--
。
|
|
-c, --count
|
只显示匹配结果的总行数。
|
如果只有一个文件给 Ripgrep,那么只打印匹配结果的总行数。可以用
--with-filename
来强制打印文件名,该选项会覆盖
--count-matches
选项。
|
|
--count-matches
|
只显示匹配结果的总次数。
|
可以用
--with-filename
来强制在只有一个文件时也输出文件名。
|
|
--debug
|
显示调试信息。
|
|
--dfa-size-limit
|
指定正则表达式 DFA 的上限,默认为 10M。
|
该选项允许接受与
--max-filesize
相同大小的后缀标志。
|
-E, --encoding
|
指定文本编码格式, 默认是 auto。
|
更多编码格式参考:https://encoding.spec.whatwg.org/#concept-encoding-get
|
-f, --file
...
|
从文件中读入搜索模式, 一行一个模式。
|
结合
-e/--regexp
参数可多个文件一起组合使用,所有组合会被匹配。
|
|
--files
|
打印所有将被搜索的文件路径。
|
以
rg
--files [PATH...]
方式使用,不能增加搜索模式。
|
|
-l, --files-with-matches
|
只打印有匹配的文件名。
|
该选项会覆盖
--files-without-match
。
|
|
--files-without-match
|
只打印无匹配的文件名。
|
该选项会覆盖
--file-with-matches
。
|
|
-F, --fixed-strings
|
把搜索模式当成常规文字而非正则表达式。
|
该选项可以用
--no-fixed-strings
来禁止。
|
|
-L, --follow
|
该选项会递归搜索符号链接,默认是关闭的。
|
该选项可以用
--no-follow
选项来手动关闭。
|
-g, --glob
...
|
包含或排除用于搜索匹配给定的文件和目录,可以用 ! 来取反。
|
该选项可以多次使用,会匹配 .gitignore 中的规则。
|
|
-h, --help
|
打印帮助信息。
|
|
|
--heading
|
打印文件名到匹配内容的上方而不是在同一行。
|
该选项是默认启用的,可以用
--no-heading
来关闭。
|
|
--hidden
|
启用搜索隐藏文件和文件夹。
|
默认情况下是忽略搜索隐藏文件和文件夹的, 可用
--no-hidden
来关闭。
|
--iglob
...
|
作用同
--glob
, 但这个选项大小写不敏感。
|
|
|
-i, --ignore-case
|
指定搜索模式中的大小写不敏感。
|
该选项会被
-s/--case-sensitive
或
-S/--smart-case
覆盖。
|
--ignore-file
...
|
指定搜索时需忽略的路径,格式同
.gitignore
, 可同时指定多个。
|
如果存在多个
--ignore-file
标记时,后面优先级会更高。
|
|
-v, --invert-match
|
反向匹配,显示与给定模式不匹配的行。
|
|
|
-n, --line-number
|
显示匹配内容所在文件的行数,该选项默认是打开的。
|
|
|
-x, --line-regexp
|
只显示整行都匹配搜索模式的行。
|
该选项会覆盖
--word-regexp
。
|
-M, --max-columns
|
不打印长于
中指定节字大小的匹配行内容,只显示该行的匹配数。
|
|
-m, --max-count
|
限制一个文件中最多
行被匹配。
|
|
--max-depth
|
限制文件夹递归搜索深度。
|
如:
rg --max-depth 0 dir/
则表示不执行任何搜索。
|
--max-filesize
|
搜索时忽略大于
byte 的文件。
|
SUFFIX 的单位可以是:K、M、G,默认是:byte。
|
|
--mmap
|
尽量使用 Memory Maps 进行搜索,这样速度会更快。该选项是默认行为。
|
如果使用
--mmap
搜索文件时 Ripgrep 发生意外中止,可使用
--no-mmap
选项关闭它。
|
|
--no-config
|
不读取 configuration 文件, 并忽略 RIPGREP_CONFIG_PATH 变量。
|
|
|
--no-filename
|
不要打印匹配文件的文件名。
|
|
|
--no-heading
|
不在每个匹配行上方打印文件名,而是在匹配行的同一行上打印。
|
|
|
--no-ignore
|
不读取忽略文件,如:.gitignore、.ignore 等。
|
该选项可以用
--ignore
关闭。
|
|
--no-ignore-global
|
不读取全局的 ignore 文件,比如:
$HOME/.config/git/ignore
。
|
该选项可以用
--ignore-global
关闭。
|
|
--no-ignore-messages
|
取消解析 .ignroe、.gitignore 文件中相关错误信息。
|
该选项可通过
--ignore-messages
关闭。
|
|
--no-ignore-parent
|
不读取父文件夹里的 .gitignore、.ignore 文件。
|
该选项可通过
--ignore-parent
关闭。
|
|
--no-ignore-vcs
|
不读取版本控制器中的 .ignore 文件。
|
该选项可通过
--ignore-vcs
关闭。
|
|
-N, --no-line-number
|
不打印匹配行数。
|
|
|
--no-messages
|
不打印打开和读取文件时相关错误信息。
|
|
|
-0, --null
|
在打印的文件路径后加一个 NUL 字符。
|
这对于结合 Xargs 使用时是非常有用的。
|
|
-o, --only-matching
|
只打印匹配的内容,而不是整行。
|
|
|
--passthru
|
同时打印文件中匹配和不匹配的行。
|
|
--path-separator
|
路径分隔符,在 Linux 上默认是 /,Windows 上默认是 \ 。
|
|
--pre
|
用
处理文件后,并将结果传递给 Ripgrep。
|
该选项存在一定的性能损耗。
|
|
-p, --pretty
|
该选项是
--color always --heading --line-number
的别名。
|
|
|
-q, --quiet
|
该选项不会打印到标准输出, 如果匹配发现时就停止搜索。
|
当 RipGrep 用于 exit 代码时该选项非常有用。
|
--regex-size-limit
|
设置已编译正则表达式的上限,默认限制为10M。
|
|
-e, --regexp
...
|
使用正则来匹配搜索条件。
|
该选项可以多次使用,可打印匹配任何模式的行。
|
-r, --replace
|
用相应文件内容代替匹配内容打印出来。
|
|
|
-z, --search-zip
|
在 gz、bz2、xz、lzma、lz4 文件类型中搜索。
|
该选项可通过
--no-search-zip
关闭。
|
|
-S, --smart-case
|
如果全小写,则大小写不敏感,否则大小写敏感。
|
该选项可通过
-s/--case-sensitive
和
-i/--ignore-case
来关闭。
|
--sort
|
将输出结果按升序进行排序,可排序类型有:path、modified、accessed、created 。
|
|
--sortr
|
将输出结果按降序进行排序,可排序类型有:path、modified、accessed、created 。
|
|
|
--stats
|
打印出统计结果。
|
|
|
-a, --text
|
搜索二进制文件。
|
该选项可通过
--no-text
关闭。
|
-j, --threads
|
搜索时要使用的线程数。
|
|
-t, --type
...
|
只搜索指定的文件类型。
|
可以通过
--type-list
来列出支持的文件类型。
|
--type-add
...
|
添加一种文件类型。
|
|
--type-clear
...
|
清除默认的文件类型。
|
|
|
--type-list
|
列出所有内置文件类型。
|
|
-T, --type-not
...
|
不要搜索某种文件类型。
|
|
|
-u, --unrestricted
|
-u
搜索.gitignore 里的文件,
-uu
搜索隐藏文件,
-uuu
搜索二进制文件。
|
|
|
-V, --version
|
打印版本信息。
|
|
|
--vimgrep
|
每一次匹配都单独打印一行,如果一行有多次匹配会打印成多行。
|
|
|
-H, --with-filename
|
打印匹配的文件路径,该选项默认打开。
|
该选项可通过
--no-filename
关闭。
|
|
-w, --word-regexp
|
把搜索参数作为单独单词匹配。
|
该选项会覆盖
--line-regexp
选项。
|
更多命令行选项,可通过
rg --help
自行查看。
Ripgrep 使用实例
搜索指定文件中包含关键字的内容
$ rg 'github.com' README.md
1:<h1 align="center"><a title="New «NexT» 6.0.0 version [Reloaded]" href="https://github.com/theme-next/hexo-theme-next">NexT</a></h1>
6:[![mnt-image]](https://github.com/theme-next/hexo-theme-next)
21:More NexT examples [here](https://github.com/iissnan/hexo-theme-next/issues/119).
41: $ curl -s https://api.github.com/repos/iissnan/hexo-theme-next/releases/latest | grep tarball_url | cut -d '"' -f 4 | wget
-i - -O- | tar -zx -C themes/next --strip-components=1
51: $ curl -L https://api.github.com/repos/iissnan/hexo-theme-next/tarball/v5.1.2 | tar -zxv -C themes/next --strip-components=1
57: $ git clone --branch v5.1.2 https://github.com/iissnan/hexo-theme-next themes/next
67: $ curl -L https://api.github.com/repos/iissnan/hexo-theme-next/tarball | tar -zxv -C themes/next --strip-components=1
73: $ git clone https://github.com/iissnan/hexo-theme-next themes/next
110:For those who also encounter **Error: Cannot find module 'hexo-util'** [issue](https://github.com/iissnan/hexo-theme-next/issues/1490), please check your NPM version.
128:282:NexT uses [Tomorrow Theme](https://github.com/chriskempson/tomorrow-theme) with 5 themes for you to choose from.
288:Head over to [Tomorrow Theme](https://github.com/chriskempson/tomorrow-theme) for more details.
367:[download-latest-url]: https://github.com/iissnan/hexo-theme-next/archive/master.zip
368:[releases-latest-url]: https://github.com/iissnan/hexo-theme-next/releases/latest
369:[releases-url]: https://github.com/iissnan/hexo-theme-next/releases
370:[tags-url]: https://github.com/iissnan/hexo-theme-next/tags
371:[commits-url]: https://github.com/iissnan/hexo-theme-next/commits/master
搜索指定文件中包含以关键字开头的单词的内容
$ rg 'lang\w+' README.md
154:168:Default language is English.
171:language: en
172:173:174:175:176:177:178:179:180:181:
搜索指定文件中包含以关键字开头的内容
$ rg 'hexo\w*' README.md
1:<h1 align="center"><a title="New «NexT» 6.0.0 version [Reloaded]" href="https://github.com/theme-next/hexo-theme-next">NexT</a></h1>
3:<p align="center">NexT is a high quality elegant <a href="http://hexo.io">Hexo</a> theme. It is crafted from scratch, with love.</p>
6:[![mnt-image]](https://github.com/theme-next/hexo-theme-next)
9:[![hexo-image]][hexo-url]
21:More NexT examples [here](https://github.com/iissnan/hexo-theme-next/issues/119).
25:**1.** Change dir to **hexo root** directory. There must be `node_modules`, `source`, `themes` and other directories:
27: $ cd hexo
41: $ curl -s https://api.github.com/repos/iissnan/hexo-theme-next/releases/latest | grep tarball_url | cut -d '"' -f 4 | wget -i - -O- | tar -zx -C themes/next --strip-components=
1
51: $ curl -L https://api.github.com/repos/iissnan/hexo-theme-next/tarball/v5.1.2 | tar -zxv -C themes/next --strip-components=1
57: $ git clone --branch v5.1.2 https://github.com/iissnan/hexo-theme-next themes/next
搜索指定目录及子目中包含关键字的内容
$ rg 'github.com' ./
./src/scrollspy.js
6:* Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE)
./src/affix.js
6: * Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE)
./src/js.cookie.js
3: * https://github.com/js-cookie/js-cookie
搜索以关键字为独立单词的内容
$ rg -w 'github.com' ./
./bower.json
36: "url" : "http://github.com/julianshapiro/velocity.git"
./velocity.ui.js
58: var abortError = "Velocity UI Pack: You need to update Velocity (jquery.velocity.js) to a newer version. Visit http://github.com/julianshapiro/velocity.";
./velocity.js
442: /* IE detection. Gist: https://gist.github.com/julianshapiro/9098609 */
463: /* rAF shim. Gist: https://gist.github.com/julianshapiro/9497513 */
472: /* Technique by Erik Moller. MIT license: https://gist.github.com/paulirish/1579671 */
480: /* Array compacting. Copyright Lo-Dash. MIT License: https://github.com/lodash/lodash/blob/master/LICENSE.txt */
522: /* Copyright Martin Bohm. MIT License: https://gist.github.com/Tomalak/818a78a226a0738eaade */
搜索包含关键字内容的文件并且只打印文件名
$ rg -w 'github.com' ./ -l
./velocity.js
./bower.json
./velocity.ui.js
./velocity.ui.min.js
在指定文件类型格式为 JS 的文件中搜索包含关键字的内容
RipGrep 实现的方式存在多种多样,这里介绍比较常用的两种。
$ rg 'function writeOnCanvas' --type js
source/lib/Han/dist/han.js
1726:function writeOnCanvas( text, font ) {
$ rg 'function writeOnCanvas' -g '*.js'
source/lib/Han/dist/han.js
1726:function writeOnCanvas( text, font ) {
如果要同时搜索多个文件类型可以写成下面这样。
$ rg 'Hanzi' -g '*.{js,css}'
han.min.js
2:/*! Han.css: the CSS typography framework optimised for Hanzi */
han.js
3: * Han.css: the CSS typography framework optimised for Hanzi
48: // Address Hanzi and Western script mixed spacing
426: /* Hanzi and Western mixed spacing
han.css
4:/*! Han.css: the CSS typography framework optimised for Hanzi */
han.min.css
4:/*! Han.css: the CSS typography framework optimised for Hanzi */
在当前目下并且不包含文件类型格式为 CSS 的文件中搜索包含关键字的内容
$ rg 'revertVowel' --type-not css
source/lib/Han/dist/han.min.js(this["comb-liga-zhuyin"]=O.substZhuyinCombLiga
(this.context)),this},revertVowelCombLiga:function(){try{this["comb-liga-vowel"].revert("all")}catch(a){}return this},revertVowelICombLiga:function(){try{this["comb-liga-vowel-i"].revert("all")}catch(a){}return this},revertZhuyinCombLiga:function(){try{this["comb-liga-zhuyin"].revert("all")}catch(a){}return this},revertCombLigaWithPUA:function(){try{this["comb-liga-vowel"]
.revert("all"),this["comb-liga-vowel-i"].revert("all"),this["comb-liga-zhuyin"].revert("all")}catch(a){}return this},substInaccurateChar:function(){return this["inaccurate-char"]=O.substInaccurateChar(this.context),this},revertInaccurateChar:function(){try{this["inaccurate-char"].revert("all")}catch(a){}return this}}),a.addEventListener("DOMContentLoaded",function(){var a;K.classList.contains("han-init")?O.init():(a=J.querySelector(".han-init-context"))&&(O.init=O(a).render())}),("undefined"==typeof b||b===!1)&&(a.Han=O),O});
source/lib/Han/dist/han.js
2939: revertVowelCombLiga: function() {
2946: revertVowelICombLiga: function() {
你也可以用下面的更简洁的写法来达到同样的效果。
$ rg 'revertVowel' -Tcss
使用正则表达式进行关键字搜索
$ rg -e "noConf.*lict" ./
./js.cookie.js
21: api.noConflict = function () {
./scrollspy.js
166: $.fn.scrollspy.noConflict = function () {
./affix.js
139: $.fn.affix.noConflict = function () {
搜索匹配关键字的内容及显示其上下内容各两行
$ rg -e "noConf.*lict" -C2
js.cookie.js
19- var OldCookies = window.Cookies;
20- var api = window.Cookies = factory();
21: api.noConflict = function () {
22- window.Cookies = OldCookies;
23- return api;
scrollspy.js
164- // =====================
165-
166: $.fn.scrollspy.noConflict = function () {
167- $.fn.scrollspy = old
168- return this
affix.js
137- // =================
138-
139: $.fn.affix.noConflict =










