问题导读:
1 Kafka集群有什么优势?
2 集群中部署多少个节点合适?
3 集群针对系统如何调优?
Kafka集群
对于本地的开发工作或者概念性的验证工作,单个Kafka服务器就可以支撑了。但是以集群的方式部署Kafka将会有许多好处。最大的好处就是可以在多个服务器之间进行负载均衡。如果某个节点挂掉,则可以使用它的备份节点继续提供服务。本章节就重点关注下Kafka的集群。
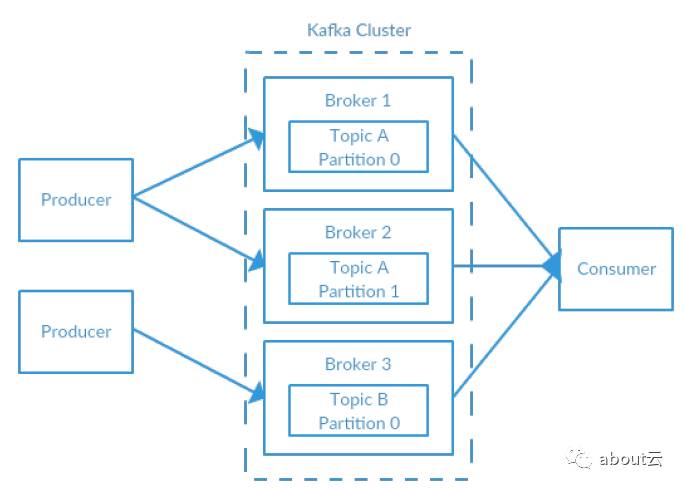
图2-2 简单的Kafka集群
多少个Broker?
Kafka集群节点的个数需要考虑几个因素。首先需要关注的是为了满足消息持久化的需求,单个节点所能提供的磁盘空间。如果集群需要10T的空间保存数据,每个节点只有2T,那么就需要5个broker。另外还需要考虑其他应用的存储需求,不可能100%都用来给broker做持久化。如果kafka要做备份,那么磁盘的使用还需要翻倍。这就意味着,为了满足10T的需求以及备份的需求,那么至少需要10个broker。
另一个需要考虑的是集群处理的请求量,这通常是通过网络带宽来衡量的,典型的场景是有多个消费者同时消费数据、或者在某时间持久化的消息到达高峰。如果单个broker可以使用80%的网络带宽,如果有两个消费者,那么带宽就不够了。如果集群还是用了备份,还需要考虑数据进入备份节点的带宽,这部分的带宽压力会随着备份节点的个数增加而增加。
另外,也需要考虑磁盘的吞吐量和内存。
Broker的配置
在集群中,broker需要关注两个配置。第一个是zookeeper.connect参数,它用于控制集群存储的原信息路径。第二个是broker.id,它决定这个broker叫什么。其他会有一些控制备份的参数,稍后会提到。
操作系统调优
大多数linux分布式框架都会针对操作系统调优设置一些开箱即用的配置,针对Kafka的broker调优可能有所不同。主要需要关注的是虚存和网络,当然,为了存储消息也需要关注磁盘。一般配置操作系统参数的文件是/etc/sysctl.conf,有一些操作系统可能不同。
虚存
一般linux虚存都会根据自身系统的负载来设置。这里需要关注的是有多少交换空间可以使用。对于大多数的应用来说,吞吐都是个问题,建议避免使用交换空间。将内存页交换到磁盘会影响kafka的性能。另外,Kafka也会大量的使用系统的页缓存,如果此时被交换到磁盘上,相当于缓存未命中了。
一种比较好的方式就是关闭交换空间。交换空间其实也不是必须的,只不过在系统发生故障时,提供一些安全保障。因此可以设置vm.swappiness小一点,比如1,这个值是设置系统使用交换空间的百分比。最好还是减小页面缓存的大小,而不是直接使用交换空间。
为什么不设置swappiness为0?
以前都是推荐swappniess设置为0,这样意味着在内存不足时也不会使用交换空间。然后再linux内核3.5-rc1版本,并且这个改变应用到了很多的系统版本,比如Red Hat Enterprise 内核版本为2.6.32-303,它意味着在任何情况下都不会使用交换空间。因此还是推荐设置值为1.
还可以调整内存如何处理脏页到磁盘。生产者持久化消息的效率依赖于Kafka依赖于磁盘IO性能。这也是为什么日志段文件需要放在一个比较快的磁盘上存储,比如SSD或者RAID。这样在刷新到磁盘的时候,脏页的数量可以减少一些。这个参数通过vm.dirty_background_ratio来决定,默认是10。这个参数是操作同内存的百分比,在很多情况下都是设置为5。这个配置不能设置为0,这会导致内核在不断的刷新页,降低设备在读写峰值是的操作能力。
可以通过vm.dirty_ratio来设置脏页刷新到磁盘的数量,默认是20(也是内存的百分比).这个值可以设置在60-80之间。这个设置也有不少的风险,如果刷新中断,那么可能出现一段时间IO暂停。如果设置vm.dirty_ratio,推荐使用Kafka的备份来减少风险。
如果选择这几个参数进行优化,最好还是在kafka环境下模拟观察一下脏页的数量。脏页的配置是在/proc/vmstat文件中:
[AppleScript]
纯文本查看
复制代码
?
|
1
2
3
4
|
nr_dirty
3875
nr_writeback
29
nr_writeback_temp
0
|
磁盘
硬件的选择或者RAID的配置会对Kafka的性能有很大的影响,很多不同的文件系统可供使用,对于本地文件系统来说,最常见的还是EXT4或者XFS。XFS是目前linux版本默认的文件系统,因为性能虽然比EXT4低一点,但是调优的参数选项更少一些。其中包括向磁盘刷新数据的频率,默认是5。而且EXT4引入了块的延迟分配,这也增加了数据的丢失和文件系统的损坏的可能性。XFS也有延迟分配的机制,但是会更安全一些。XFS再kafka负载的时候性能也更高一些。这在磁盘批量更新的时候,会有更好的吞吐量。
忽略文件系统的选择,建议设置挂载点设置noatime。文件元数据包含了三个时间戳:创建时间ctime、最后的更新时间mtime和最后的进入时间atime。默认atime是在每次读取文件的时候都会更新。这会引入大量的磁盘写操作,并且atime属性其实很少用到,除非是应用需要了解最后进入的时间。但是kafka并不使用它,因此建议直接关闭这个功能。设置挂载点noatime可以防止更新文件的atime属性,但是不会影响ctime和mtime。
网络
对于很多的应用,都需要针对linux的网络进行调优,尤其是对于需要进行高速的数据传输的应用。Kafka推荐的优化方式其实也适用于其他的应用。第一点就是调整socket默认的发送和接收缓冲区的大小。这会在数据传输时有很大的作用。每个socket发送和接收的默认大小是net.core.wmem_default和net.core.rmem_default,推荐设置为131072或者128k。发送和接收的最大值net.core.wmem_max和net.core.rmem_max可以设置为2087152或者2m。注意这个最大值并不是说每个socket都需要分配这么大,只是在超出的时候最大的限制。
另外,tcpsocket发送和接收的缓冲区大小需要独立的设置,net.ipv4.tcp_wmem和net.ipv4.tcp_rmem参数。参数设置3个以空格为分隔的值,分别表示最小值,默认值,最大值。最大值不能超过net.core.wmem_max和net.core.rmem_max。比如设置参数为 4096 65536 2048000,代表最小的缓冲区大小为4k,默认是64k,最大是2m。根据网络负载的情况,你可以调整缓冲区的最大值。
还有一些其他的网络调优的参数。比如:
开启TCP滑动窗口,
net.ipv4.tcp_window_scaling
设置为1,这样客户端传输数据的时候更高效,并且允许在broker端的缓冲区缓存。
增加
net.ipv4.tcp_max_syn_backlog
(默认是1024),从而允许更多的网络连接请求。
增加
net.core.netdev_max.backlog
(默认是1000)可以提高网络的并发量,特别是使用多于千兆的网络时,允许网络包排队等待处理。





