上回数据冰山发布的
《TI7伤害之王》
和
《TI7小组赛英雄数据报告》
收到冰友反馈:
我是过来人,道理我都懂。大家其实是希望我给
一个故事完整、过程清晰、内容详实的DOTA2数据分析例子
,这样学起来才会有顺藤摸瓜的感觉,比起摸着石头过河,能够少踩一些坑。
既然如此,我也只好收拾一下自己的懒癌,再满足大家一次。
本文叙述结构按照数据分析师的工作流程来:
-
提一个值得分析的问题(中路一塔到底有多重要?)
-
获取数据源(手把手演示如何使用python调用API获取需要的数据)
-
确定方法论(统计推断statistical inference),处理数据,得出结论
【注意:在数据分析师的实际工作过程中,顺序可能颠倒,也可能重复多次】
一、提一个好问题
会提问、提好问,是数据分析师最重要的技能之一。
大家平时听讲座,经常看到演讲者眼冒精光的对某个提问者说:“你这个问题提的非常好!很有水平!(加鸡腿)”。演讲者觉得问题好,是因为这个问题触及了事情的本质,回答好这个问题,就可以把事情说清楚。
和他问自答的演讲者相比,自问自答的数据分析师自由度更高,
更需要借一双慧眼,在纷繁复杂的数据和千头万绪的可能性之中,找到最接近真相的那些问题
。
本文提出的问题是:DOTA2这款免费游戏的中路一塔有多重要?
喜欢看比赛的朋友,对这个问题应该不陌生。主播解说比赛时经常讲:这个中路一塔绝对不能放!这个塔放了之后,视野黑一大片,活动范围减小,打钱空间被压缩...就不好打了!那么,主播们说的对吗?如何衡量中路一塔的重要性?
在DOTA2的世界里,所谓「重要」,只有两个字:能赢。比如刀塔中最重要的建筑毫无疑问是基地——因为基地一炸,比赛就结束了。
如果我们可以把「先拆掉敌方中路一塔」和「比赛胜负」联系起来,就可以得出答案
。按这个思路,对每场比赛,我们需要的数据是:
-
哪一方先拆掉敌方中路一塔
-
哪一方赢得了比赛
二、获取数据源
如何获取一场比赛的「拆塔信息」和「比赛胜负」?
上篇文章讲过,可以调用
OPENDOTA
提供的API来获取公开比赛数据。查阅API接口文档后,发现有一个名叫matches的api提供了一场比赛(match)的详细信息。我们需要的数据很可能在api返回的结果里。
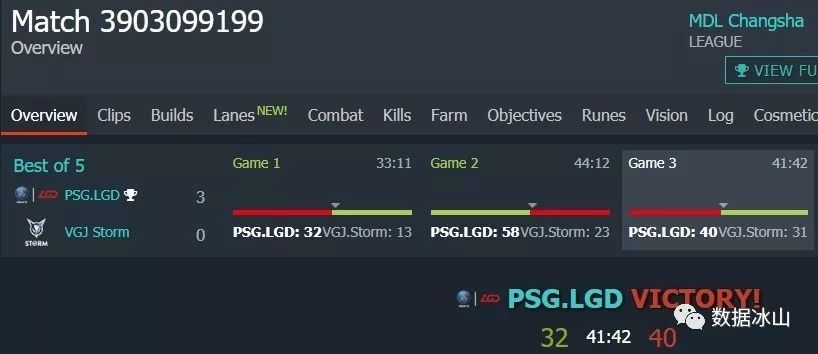
我们不妨找一场比赛调用这个API试一下(反正又不要钱),看看它到底提供了哪些数据。以刚刚结束的长沙MDL MAJOR最后一场比赛为例(LGD夺冠那场),它的比赛编号(也就是调用api要传入的参数:match_id)是3903099199。
同学们
不要紧张
,现在还不用写代码。
这种webapi是可以在浏览器中调用的。只需要按API的接口说明构建出网址
api.opendota.com/api/ma
,然后把链接复制到你常用的浏览器中,按回车就可以得到结果:

为什么数据这么多?平时打完一局DOTA2,赛后统计数据没这么多啊?
同学们
不要紧张
。Opendota提供的matches接口,不仅返回了「基础赛后统计数据」,还包含了许多「通过解析录像得到的游戏中数据」。以防御塔数据为例,基础的赛后统计数据只能告诉你
比赛结束时,双方队伍的防御塔存亡状态
(哪些拆掉了,哪些还在);而解析录像得到的游戏中数据,
可以告诉你每座塔是什么时候被谁拆掉的
。
如果你愿意,你甚至可以通过解析录像知道拆塔的过程中,每一个英雄每一下A出了多少伤害。也就是说,DOTA2这款游戏的数据源很开放(其他类DOTA游戏没法比),这也正是我在市面上已经有非常多数据分析入门教程的前提下,执意要写「DOTA2数据分析入门」教程的原因——因为对大家来讲,那些教材使用的数据源都不对口,学起来很容易半途而废(特别是基础不好的朋友)。
而DOTA2这款游戏内涵丰富,可以分析的维度很多,如果你本身是一名刀塔玩家,使用DOTA2数据源来学习数据分析,学习过程一定会很愉快
。
比如,当你看到上图中的「"radiant_win":false」时,你一定会知道radiant表示天辉,所以radiant_win就是天辉胜利,合起来就是:天辉胜利为假,那就是夜魇(Dire)获胜咯!(如果不放心,你可以找第三方数据产品验证一下)
是不是很简单?
接下来我们在API返回的结果中寻找第二个数据「拆塔信息」。经过一番折腾(比如搜索关键字"tower"或者"building"),我们可以发现数据出现了一些奇怪的东西:
-
npc_dota_goodguys_tower1_mid
-
npc_dota_badguys_tower1_mid
-
npc_dota_goodguys_tower2_bot
-
npc_dota_goodguys_tower3_top
tower1是什么鬼?一塔?mid\bot\top是中塔\下塔\上塔?那goodguys和badguys是不是天辉和夜魇???
是的,上面的猜测都是对的,V社就是这么任性(不好好用radiant,还要搞个goodguys...)。

所以,上图中的两条拆塔信息是:
-
名叫npc_dota_hero_gyrocopter(矮人直升机)的单位,于20分10秒,拆掉(反补)了天辉方的中路一塔。
-
名叫npc_dota_hero_gyrocopter(矮人直升机)的单位,于20分37秒,拆掉了夜魇方的中路一塔。
如果你不放心,仍然可以用第三方数据产品(DOTABUFF、OPENDOTA、刀魔数据等)来验证数据的准确性:
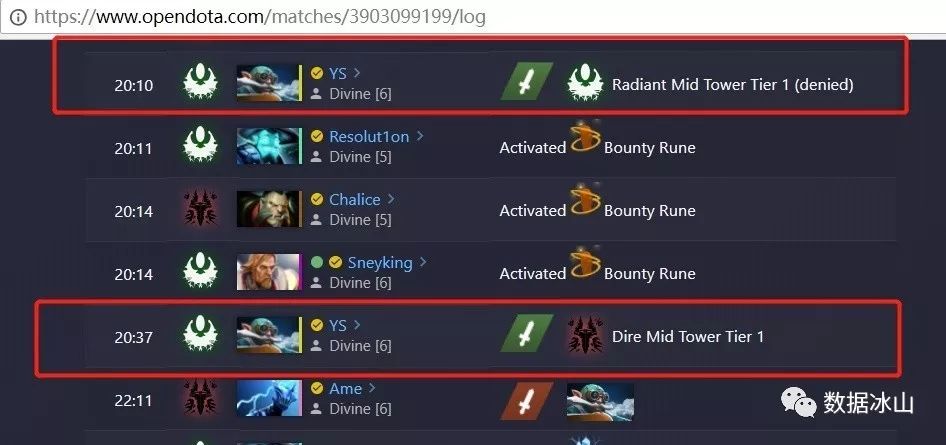
OK,到现在为止,我们终于获取了LGD对阵VGJ.S的第三局所有想要的信息:夜魇方先拆掉天辉方的中路一塔,夜魇获胜。
但是,使用浏览器调用接口,人工统计信息的操作会很麻烦(比如你想查询100场比赛的信息,估计眼睛都要看瞎)。
接下来我们必须开始写代码了
。关于代码有两点说明:
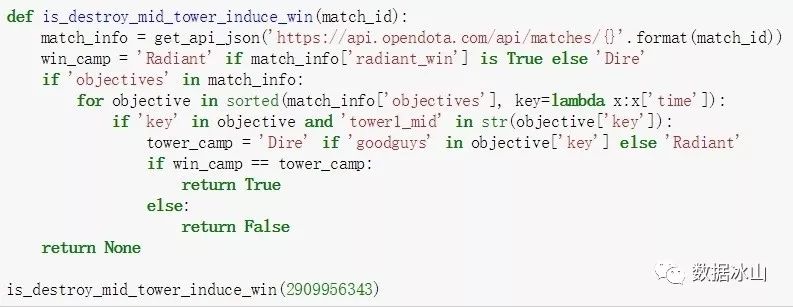
写代码的时候,我们可以再简化一下,把「拆塔和比赛胜负的联系」用一个bool类型表示。比如我们可以写一个名叫is_destroy_mid_tower_induce_win的函数,对每一场比赛(用match_id标识)返回:
-
True,表示先拆掉敌方中路一塔的队伍,取得了胜利
-
False,表示先拆掉地方中路一塔的队伍,遭受了失败
-
None,表示获取不到数据(录像损坏或者解析出错)
三、处理数据,得出结论
孤证不立,一场比赛的情况不足以反映规律,我们需要看更多比赛的数据。DOTA2进入7.0时代以来,一共打了13574场职业比赛(可用下图的SQL在
OpenDota - Dota 2 Statistics
上查询)。

难道我们要把1万3千多场比赛的信息都弄下来?这样做确实可以,但是太耗时间了——OpenDota提供的API限制访问速度是1分钟60次,也就是需要4个小时才能获取这些比赛的信息(而且代码没有处理网络异常,很有可能跑到一半就GG了,重来又是4小时...)
怎么办?
这个时候就需要一些统计学知识了
。我们先
随机抽取
200场比赛看看情况。

200场比赛的结果是这样的:
62.6%!意思是只要先拆掉敌方中一塔,就有6成以上的胜率?
不好说,因为这只是107场比赛的数据(总共有1万多场比赛),比如我们再重新抽107场比赛,结果很可能会不一样
。那么问题来了,这个62.6%的可信度有多高?
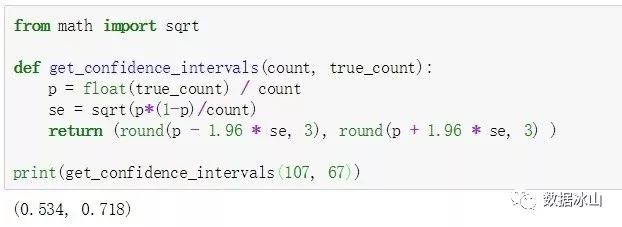
这需要用到「统计推断」的知识(推荐一本书《OpenIntro Statistics》)。我们采样的每场比赛之间相互独立,同时正负样本的数量都大于10(说明采样结果的分布没有严重偏曲)。根据「中心极限定理」,采样结果的分布近似服从正态分布。
先算出标准差为0.047,然后算出95%置信区间为[53.4%, 71.8%]。
也就是说,根据107场抽样比赛来看,我们有95%的把握:先拆掉敌方中路一塔的队伍,获胜概率在53.4%~71.8%之间
。