
来源:萝卜大杂烩
ID:luobodazahui
一直想做一个从爬虫到数据处理,到API部署,再到小程序展示的一条龙项目,最近抽了些时间,实现了一个关于知乎热榜的,今天就来分享一下!
由于代码还没有完全整理好,今天只给出一个大致的思路和部分代码,最终的详细代码可以关注后续的文章!
数据爬取
首先我们看下需要爬取的知乎热榜
https://www.zhihu.com/billboard
这个热榜可以返回50条热榜数据,而这些数据都是通过页面的一个 JavaScript 返回的
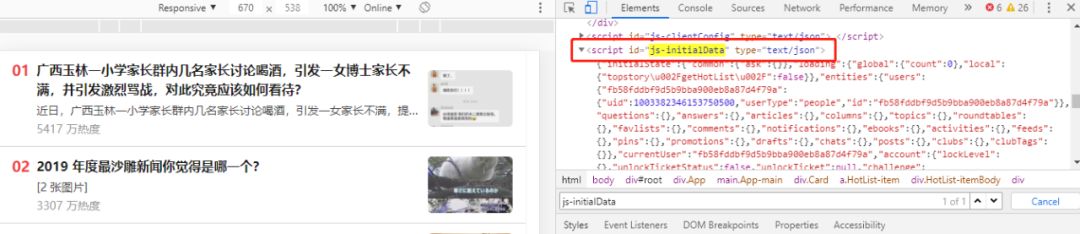
于是我们就可以通过解析这段 JS 代码来获取对应数据
url = 'https://www.zhihu.com/billboard'
headers = {"User-Agent": "", "Cookie": ""}
def get_hot_zhihu():
res = requests.get(url, headers=headers)
content = BeautifulSoup(res.text, "html.parser")
hot_data = content.find('script', id='js-initialData').string
hot_json = json.loads(hot_data)
hot_list = hot_json['initialState']['topstory']['hotList']
return hot_list
然后我们再点击一个热榜,查看下具体的热榜页面,我们一直向下下拉页面,并打开浏览器的调试板,就可以看到如下的一个请求
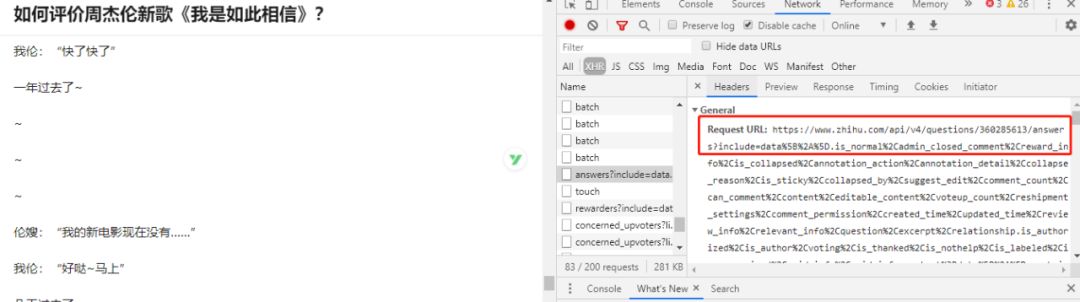
该接口返回了一个包含热榜回答信息的 json 文件,可以通过解析该文件来获取对应的回答
def get_answer_zhihu(id):
url = 'https://www.zhihu.com/api/v4/questions/%s/answers?include=' % id
headers = {"User-Agent": "", "Cookie": ""}
res = requests.get(url + Config.ZHIHU_QUERY, headers=headers)
data_json = res.json()
answer_info = []
for i in data_json['data']:
if 'paid_info' in i:
continue
answer_info.append({'author': i['author']['name'], 'voteup_count': i['voteup_count'],
'comment_count': i['comment_count'], 'content': i['content'],
'reward_info': i['reward_info']['reward_member_count']})
return answer_info
数据存储
获取到数据之后,我们需要存储到数据库中,以便于后续使用。因为后面准备使用 Flask 来搭建 API 服务,所以这里存储数据的过程也基于 Flask 来做,用插件 flask_sqlalchemy。
我们定义三张表,分别存储知乎热榜的详细列表信息,热榜的热度信息和热榜对应的回答信息
class ZhihuDetails(db.Model):
__tablename__ = 'ZhihuDetails'
id = db.Column(db.Integer, primary_key=True)
hot_id = db.Column(db.String(32), unique=True, index=True)
hot_name = db.Column(db.Text)
hot_link = db.Column(db.String(64))
hot_cardid = db.Column(db.String(32
))
class ZhihuMetrics(db.Model):
__tablename__ = 'ZhihuMetrics'
id = db.Column(db.Integer, primary_key=True)
hot_metrics = db.Column(db.String(64))
hot_cardid = db.Column(db.String(32), index=True)
update_time = db.Column(db.DateTime)
class ZhihuContent(db.Model):
__tablename__ = 'ZhihuContent'
id = db.Column(db.Integer, primary_key=True)
answer_id = db.Column(db.Integer, index=True)
author = db.Column(db.String(32), index=True)
voteup_count = db.Column(db.Integer)
comment_count = db.Column(db.Integer)
reward_info = db.Column(db.Integer)
content = db.Column(db.Text)
由于我们需要定时查询热榜列表和热榜的热度值,所以这里需要定时运行相关的任务,使用插件 flask_apscheduler 来做定时任务
我们的定时任务,涉及到了网络请求和数据入库的操作,把这部分定时任务代码单独拉出来,在 Flask 项目的根目录下创建一个文件 apschedulerjob.py,由于在运行该文件时,是没有 Flask app 变量的,所以我们需要手动调用 app_context() 方法来创建 app 上下文
def opera_db():
with scheduler.app.app_context():
...
当然,这里的 scheduler 变量是在 create_app 中初始化过的
from flask_apscheduler import APScheduler
scheduler = APScheduler()
def create_app(config_name):
app = Flask(__name__)
app.config.from_object(config[config_name])
config[config_name].init_app(app)
db.init_app(app)
scheduler.init_app(app)
...
接着,我们就可以根据前面的两个爬虫函数,来分别入库数据了
入库热榜热度数据
update_metrics = ZhihuMetrics(hot_metrics=i['target']['metricsArea']['text'],
hot_cardid=i['cardId'],
update_time=datetime.datetime.now())
入库热榜列表数据
new_details = ZhihuDetails(hot_id=i['id'], hot_name=i['target']['titleArea']['text'],
hot_link=i['target']['link']['url'], hot_cardid=i['cardId'])
入库热榜回答数据
new_content = ZhihuContent(answer_id=answer_id, author=answer['author'], voteup_count=answer['voteup_count'],
comment_count=answer['comment_count'], reward_info=answer['reward_info'],
content=answer['content'])
最后我们就可以在 Flask 的入口程序中启动定时任务了
import os
from app import create_app, scheduler
app = create_app(os.getenv('FLASK_CONFIG') or 'default')
if __name__ == '__main__':
scheduler.start()
app.run(debug=True)
编写 API
我们首先来做热榜列表的接口,在数据库表 ZhihuMetrics 中拿到当天热榜的最新热度信息,然后再根据热榜热度信息来获取对应的列表信息,可以总结到如下的一个函数中
def
zhihudata():
current_time = '%s-%s-%s 00:00:00' % (datetime.now().year, datetime.now().month, datetime.now().day,)
zhihumetrics_data = ZhihuMetrics.query.filter(ZhihuMetrics.update_time > current_time).group_by(ZhihuMetrics.hot_cardid).order_by(ZhihuMetrics.update_time).all()
metrics_list = db_opera.db_to_list(zhihumetrics_data)
details_list = []
for d in metrics_list:
zhihudetails_data = ZhihuDetails.query.filter_by(hot_cardid=d[1]).first()
details_list.append([zhihudetails_data.hot_name, zhihudetails_data.hot_link, d[0], d[1], d[2]])
return details_list
接着定义一个视图函数返回 json 数据
@api.route('/api/zhihu/hot/')
def zhihu_api_data():
zhihu_data = zhihudata()
data_list = []
for data in zhihu_data:
data_dict = {'title': data[0], 'link': data[1], 'metrics': data[2], 'hot_id': data[3], 'update_time': data[4]}
data_list.append(data_dict)
return jsonify({'code': 0, 'content': data_list}), 200
下面再来做热榜详情接口,该接口可以返回热榜热度走势信息,为前端画图提供数据。
def zhihudetail(hot_id):
zhihumetrics_details = ZhihuMetrics.query.filter_by(hot_cardid=hot_id).order_by(ZhihuMetrics.update_time).all()
Column = {'categories': [], 'series': [{'name': '热度走势', 'data': []}]}
for i in zhihumetrics_details:
Column['categories'].append(datetime.strftime(i.update_time, "%Y-%m-%d %H:%M"))
Column['series'][0]['data'].append(int(i.hot_metrics.split()[0]))
return Column
@api.route('/api/zhihu/detail//')
def zhihu_api_detail(id):
zhihu_detail = zhihudetail(id)
return jsonify({'code': 0, 'data': zhihu_detail}), 200
接入小程序
对于小程序端,我们这里使用了 uni-app 框架,这是一个可以一份代码多端运行的框架,还是比较不错的。
首先通过 IDE HBuilder 创建一个 uni-app 模板
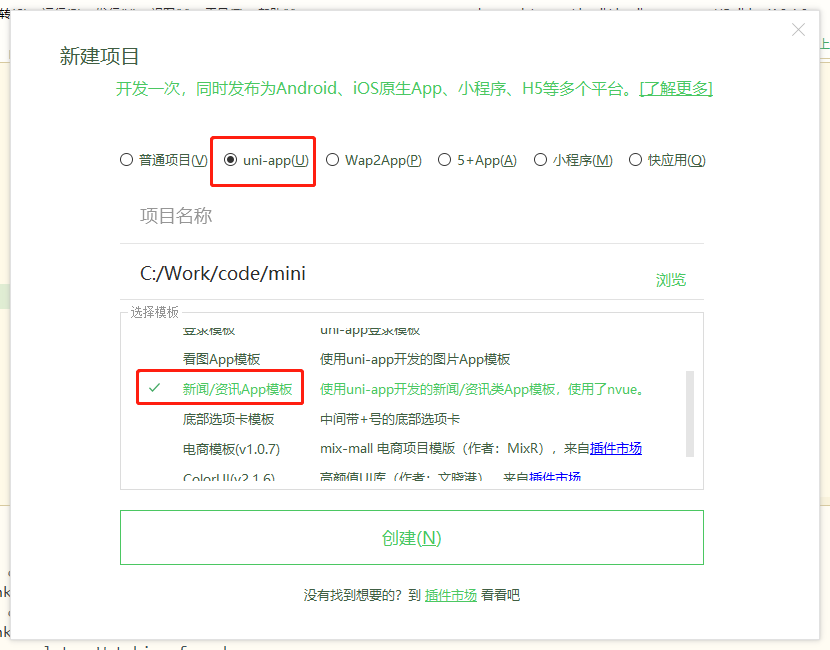
我们简单改造下该模板,首先修改下 index.nvue 文件,把 tabList 修改如下
data() {
return {
tabList: [{
id: "tab01",
name: '知乎热榜',
newsid: 0
}, {
id: "tab02",
name: '微博热榜',
newsid: 23
},
我们暂时只保留两个 tab 页签,没错后面还要再做微博的热榜!
接下来打开 news-page.nvue 文件,修改网络请求地址
uni.request({
url: 'http://127.0.0.1:5000/api/zhihu/hot/',
data: '',
把 URL 地址指向我们自己的 API 服务地址
然后再添加我们自己的新闻参数
hot_id: news.hot_id,
metrics: news.metrics,
news_url: news.link
再修改函数 goDetail 如下
goDetail(detail) {
if (this.navigateFlag) {
return;
}
this.navigateFlag = true;
uni.navigateTo({
url: '/pages/detail/detail-new?query=' + encodeURIComponent(JSON.stringify(detail))
});
setTimeout(() => {
this.navigateFlag = false;
}, 200)
},
点击每条热榜时,就会跳转到 url 对应的 /pages/detail/detail-new 页面
下面编写 detail-new.nvue 文件,这里主要用到了 uni-app 的插件 uCharts。这是一个高性能的跨端图表插件,非常好用。
template 部分
<template>
<view class="qiun-columns">
<view class="qiun-bg-white qiun-title-bar qiun-common-mt" >
<view class





