如若转载本文请在文章顶部标注“
本文转载自51CTO(ID:weixin51cto),作者:51CTO
最近我参加了Nexar组织的交通信号灯识别挑战赛,花费了十个星期认真的学习了深度学习,最终幸运的获得了第一名,收获了5000美元的奖金。
在这篇文章中,我会把我的解决方案描述一下,分享代码,当然还有一些并不完善的地方,未来我会继续改进。
即使你不是人工智能专家也无需担心读不懂这篇文章,因为文章重点放在创作理念和实践方法上,而不是具体的技术实施。

(
红绿灯识别演示
)
我把代码放在了github上,地址是https://github.com/davidbrai/deep-learning-traffic-lights,目前我正在维护之中
挑战赛的目标是识别出司机们使用Nexar应用所拍摄出的图像中的交通信号灯。也就是说在任意一张给定的图像中,识别器需要判断出是否有红绿灯并且输出红灯或是绿灯。当然,它应该只识别行驶方向的信号灯。
下面这几张图可以更清楚的说明:



以上就是我需要识别的三种可能性:没有红绿灯、红灯和绿灯。
要解决这个挑战,
最合适的解决方案是基于卷积神经网络,这是目前最流行的方法,应用深度神经网络来识别图像。
最终提交的识别模型大小也是评判的依据,模型文件越小,得分越高。此外,获胜所需的精度要达到95%。
Nexar提供了18659幅标记图像作为训练数据。每幅图像都标有上面三个类别中的一个(没有红绿灯/红灯/绿灯)。
我选择了Caffe来训练模型,主要原因是我对Caffe比较熟悉,而且它提供了大量的预训练模型。
用Python、NumPy和Jupyter Notebook用来进行结果分析、数据探索和脚本编写。
我购买了Amazon的GPU实例(g2.2xlarge)用来训练模型。到挑战赛结束后,AWS账单收了我263美元!这可真不便宜……
最终的识别器
最终,我的识别模型实现了对测试集合94.955%的精确度,模型大小为7.84 MB。相比较,GoogLeNet的模型占用了41 MB,VGG-16模型竟然要用到528 MB。
需要感谢Nexar,他们仁慈的允许了我的94.955%达到95%的精度要求。
总的来说,提高模型精确度的过程就是进行大量有逻辑和无逻辑的试验,以及反复纠错,下面是具体过程。
开始搭建模型时,我选择了ImageNet的预训练模型,用GoogLeNet搭建架构对它进行微调,很快这就帮我达到了90%的准确性!良好的开端!
SqueezeNet达到了AlexNet同级的精确度,参数却减少了50多个,而且模型尺寸只有不到0.5MB。
此外,它与ImageNet的预训练模型和Caffe的Zoo模型配合良好,这完美的切合了我的需求。SqueezeNet在github上的地址如下:
https://github.com/DeepScale/SqueezeNet
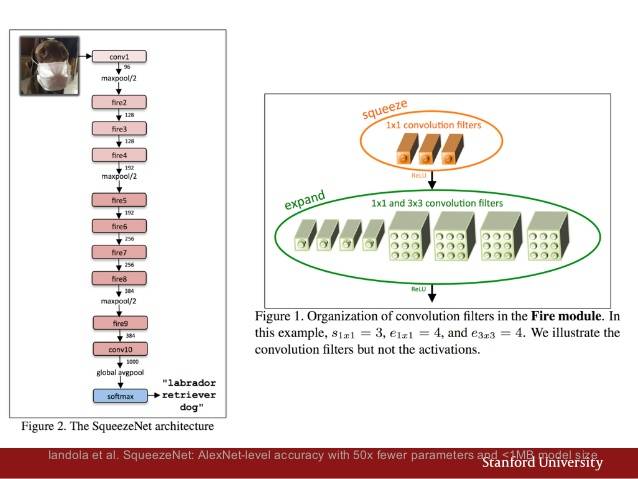
(SqueezeNet网络架构图 )
搭配好之后,导入Nexar的图片集合,经过一些简单的训练和调整,预训练模型的精度几乎从一开始就提升到了92%!效果非常赞!
Nexar提供的绝大部分图像都是水平的,但有大约2.4%是垂直的,而且没有上下左右的标识,如下图:

虽然这只是数据集的很小一部分,但想要达到95%的精度,这个问题是必须考虑的。
Nexar提供的JPEG图像没有EXIF数据,所以我想到将图片随机旋转0度、90度、180度和270度并且导入训练模型,用来确定天空的位置,确实获得了精度提高:
92%→92.6%
首先,我把数据分成3组:训练(64%)、验证(16%)和测试(20%)。几天之后,我把训练组和验证组合并,使用测试组来检查训练结果。
并且在模型中加入了“图像旋转”和“低发生率额外训练”,获得了不小的精度提升:
92.6%→93.5%
当分析模型识别的错误时,我注意到有些在模型中信任级别非常高的训练数据反而容易出错。
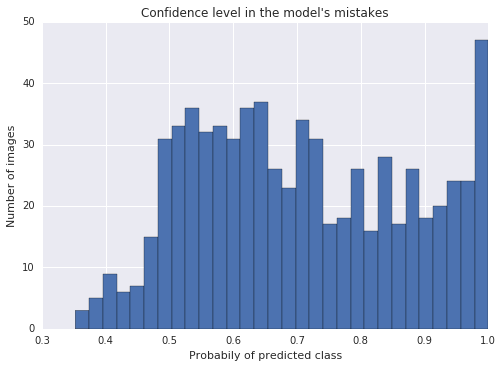
注意,在上面这张错误统计图中,最右边的栏达到了95%的信任度,这表示有大量的错误出自信任度超过95%的图像数据,这就很尴尬了。
为了解决这个问题,我不得不手动标注了709个图像,这花费了我一个小时的体力劳动,而且编写了一个Python脚本来帮助工作。当然花费的时间是值得的。
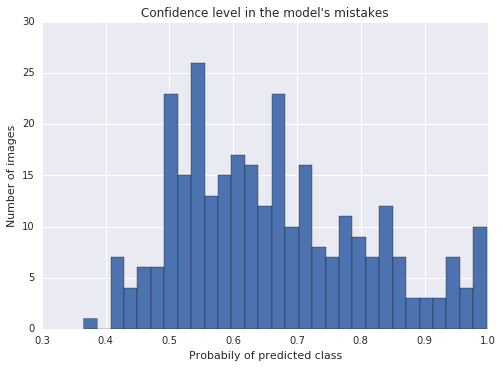
上面这张是经过重新标注和再训练的模型错误统计图,看起来好多了!
而且又一次提升了模型的精确度:
93.5%→94.1%
将几个模型结合在一起,给予相应的权重并加权计算它们的分析结果也会提高最终的精确度。
最终完成的识别器将3个单独训练的网络模型加以结合。
基于ImageNet的SqueezeNet预训练模型,根据手动修正后的图像集合进行训练。
训练数据增强步骤:
在测试时,每张图像会形成10个变体,平均计算出最终的预测结果。这10个变体为:
2号模型与1号模型非常相似,加上了图像旋转。在训练时间,图像会随机旋转90度、180度、270度或0度(不旋转)。在测试时,每一种情况都与模型1中创建变体做相同的分析。这样2号模型会分析40个变体,并将结果平均在一起。
3号模型不是基于SqueezeNet的微调,而是从零开始训练。背后的逻辑是即使准确率较低,但它会产生与上两个模型不同的特征,在三个模型合并之后,这会非常有用。
数据训练和测试过程与模型1基本相同:翻转和切割。
每个模型都会输出三个值,表示图像属于三大类中每一类的概率(没有红绿灯/红灯/绿灯)。我根据以下的权重平均计算它们的输出值:
-
模型1:0.28 #
-
模型2:0.49 #
-
模型3:0.23 #
权重的值大家可以自己定义,我是基于以前做网格搜索时获得的经验,这是一个非常简单的操作。
实际用于Nexar测试集的模型精度:94.955%

棕榈树上的绿色反光点让模型误判断为那是一个绿灯。










