作者 | P. Galeone
翻译 | 雁惊寒
【译者注】本文通过一个简单的Go绑定实例,让读者一步一步地学习到Tensorflow有关ID、作用域、类型等方面的知识。以下是译文。
Tensorflow并不是机器学习方面专用的库,而是一个使用图来表示计算的通用计算库。它的核心是用C++实现的,并且还有不同语言的绑定。Go语言绑定是一个非常有用的工具,它与Python绑定不同,用户不仅可以通过Go语言使用Tensorflow,还可以了解Tensorflow的底层实现。
Tensorflow的开发者正式发布了:
作为一个Go开发者而不是一个Java爱好者,我开始关注Go绑定,以便了解他们创建了什么样的任务。

地鼠与Tensorflow的徽标
首先要注意的是,Go API缺少对Variable的支持:该API旨在使用已经训练过的模型,而不是从头开始训练模型。安装Tensorflow for Go的时候已经明确说明了:
TensorFlow提供了可用于Go程序的API。这些API特别适合于加载用Python创建并需要在Go程序中执行的模型。
如果我们对培训ML模型不感兴趣,万岁!相反,如果你对培训模型感兴趣,那就有一个建议:
作为一个真正的Go开发者,保持简单!使用Python定义并训练模型;你可以随时使用Go来加载并使用训练过的模型!
简而言之,go绑定可用于导入和定义常量图;在这种情况下,常量指的是没有经过训练的过程,因此没有可训练的变量。
现在,开始用Go来深入学习Tensorflow吧:让我们来创建第一个应用程序。
在下文中,我假设读者已经准备好Go环境,并按照README(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/go/README.md)中的说明编译并安装了Tensorflow绑定。
让我们来重复一下什么是Tensorflow:
TensorFlow™是一款使用数据流图进行数值计算的开源软件库。图中的节点表示数学运算,而图的边表示在节点之间传递的多维数据数组(张量)。
我们可以把Tensorflow视为一种描述性语言,这有点像SQL,你可以在其中描述你想要的内容,并让底层引擎(数据库)解析你的查询、检查句法和语义错误、将其转换为内部表示形式、进行优化并计算出结果:所有这一切都会给你正确的结果。
因此,当我们使用任何一个API时,我们真正做的是描述一个图:当我们把图放到Session中并显式地在Session中运行图时,图的计算就开始了。
知道了这一点之后,让我们试着来定义一个计算图并在一个Session中进行计算吧。API文档(https://godoc.org/github.com/tensorflow/tensorflow/tensorflow/go)为我们提供了 (简写为
(简写为 )和
)和 包中所有方法的列表。
包中所有方法的列表。
我们可以看到,这两个包包含了我们需要定义和计算图形的所有内容。
前者包含了构建一个基本的“空”结构(就像Graph本身)的功能,后者是包含由C++实现自动生成绑定的最重要的包。
然而,假设我们要计算A与x的矩阵乘法,其中
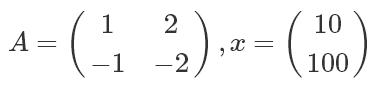
我假设读者已经熟悉了tensorflow图定义的基本思想,并且知道占位符是什么以及它们如何工作。下面的代码是对Tensorflow Python绑定的第一次尝试。我们来调用这个文件attempt1.go

代码注释的很详细,希望读者能阅读每一行注释。
现在,Tensorflow-Python用户期望该代码进行编译并正常工作。我们来看看它是否正确:

这是他看到的结果:

等等,这里发生了什么? 显然,存在两个名称都为“Placeholder”的操作。
每当我们调用一个方法来定义一个操作时,Python API都会生成不同的节点,无论是否已经被调用过。下面的代码返回3。
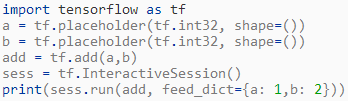
我们可以通过打印占位符的名称来验证此程序是否创建了两个不同的节点:print(a.name,b.name)生成Placeholder:0 Placeholder_1:0,因此,b占位符是Placeholder_1:0,而a占位符是Placeholder:0。
在Go中,相反,之前的程序会执行失败,因为A和x都命名为Placeholder。我们可以得出这样的结论:
Go API不会在每次调用函数来定义操作的时候自动生成新的名字:操作的名字是固定的,我们无法修改。
提问时间:
为了详细说明第二个答案,我们来解决节点名重复的问题。
正如我们刚刚看到的那样,每定义一个操作时,Python API都会自动创建一个新的名称。在底层,Python API调用类Scope的C++方法WithOpName。以下是方法的文档及其签名,保存在scope.h(https://github.com/tensorflow/tensorflow/blob/a5b1fb8e56ceda0ee2794ee05f5a7642157875c5/tensorflow/cc/framework/scope.h)中:

我们注意到,这个用于命名节点的方法返回了一个Scope,因此,节点名实际上是一个Scope。Scope是从根 /(空的图)到op_name的完整路径。
当我们尝试添加一个具有与/到op_name相同路径的节点时,WithOpName方法会添加一个后缀_(其中是一个计数器),因此它将成为同一范围内的重复的节点。
知道了这一点之后,为了解决重复节点名的问题,我们期望在Scope类型中找到WithOpName方法。可悲的是,这种方法并不存在。
相反,查看Scope类型的文档(https://godoc.org/github.com/tensorflow/tensorflow/tensorflow/go/op#Scope),我们可以看到唯一的一个方法:SubScope,它返回一个新的Scope。
文档里是这么说的:
SubScope返回一个新的Scope,这将导致添加到图中的所有操作都将以“namespace”为命名空间。如果命名空间与作用域内现有的命名空间冲突,则会添加一个后缀。
使用后缀的冲突管理与C++的WithOpName不同:WithOpName是在操作名之后添加后缀,但还是在同一作用域内(因此占位符变为了Placeholder_1),而Go的SubScope是在作用域名称后添加后缀。
这种差异会产生完全不同的图,但它们在计算上是等效的。
我们来改变占位符的定义,以此来定义两个不同的节点,此外,我们来打印一下作用域的名称。
让我们创建文件attempt2.go,把这几行从:

改成:

编译并运行:go run attempt2.go,输出结果:

提问时间:
关于Tensorflow的架构,我们学到了什么?节点完全是由被定义的作用域来标识的。作用域是我们从图的根到达节点的路径。有两种定义节点的方法:在不同的作用域(Go语言)中定义操作或更改操作名称。
我们解决了重复节点名称的问题,但另一个问题显示在我们的终端上。

为什么MatMul节点会出现错误?我们只是想增加两个tf.int64矩阵!从这段错误提示来看,int64是MatMul唯一不接受的类型。
int64类型的attr ‘T’的值不在允许的值列表中:half,float,double,int32,complex64,complex128
这个列表是什么?为什么我们可以做两个int32类型矩阵的乘法,而不是int64?
我们来解决这个问题,了解为什么会出现这种情况。
我们来看一下源代码(https://github.com/tensorflow/tensorflow/blob/r1.2/tensorflow/core/ops/math_ops.cc#L1048),寻找MatMul操作的C++声明:

该行定义了MatMul操作的接口:特别注意到代码里使用了REGISTER_OP宏来声明了op的:
这个宏调用不包含任何C++代码,但它告诉我们,在定义一个操作时,尽管它使用了模板,但是我们必须为指定的类型T(或属性)指定一个类型列表中的类型。实际上,属性.Attr("T: {half, float, double, int32, complex64, complex128}")是将类型T约束为该列表的一个值。
我们可以从教程中阅读到,即使在使用模板T时,我们也必须对每个支持的重载显式地注册内核。内核是以CUDA方式对C/C++函数进行的引用,这些函数将会并行执行。
因此,MatMul的作者决定仅支持上面列出的类型,而不支持int64。有两个可能的原因:
1. 疏忽了:这很有可能,因为Tensorflow的作者是人类!
2. 对尚未完全支持int64操作的设备兼容,因此内核的这种具体实现不足以在每个支持的硬件上运行。
回到刚才的错误提示:修改方法是显而易见的。我们必须将参数以支持的类型传递给MatMul。
我们来创建attempt3.go,把所有引用int64的行改为int32。
有一点需要注意:Go绑定有自己的一组类型,与Go的类型的一一对应。当我们将值输入到图中时,我们必须关注映射关系。从图形中获取值时,必须做同样的事情。
执行go run attempt3.go。结果:

万岁!
提问时间
关于Tensorflow的架构,我们学到了什么?每个操作都与自己的一组内核相关联。被视为描述性语言的Tensorflow是一种强大的类型语言。它不仅要遵守C++类型规则,而且还要在op的注册阶段只实现某些指定类型的能力。
使用Go来定义并执行一个图,使我们有机会更好地了解Tensorflow的底层结构。使用试错法,我们解决了这个简单的问题,我们一步一步地学到了有关图、节点和类型系统这些新东西。
SDCC 2017·深圳站之架构&大数据技术实战峰会将于2017年6月10-11日于深圳南山区中南海滨大酒店举行,集阿里、腾讯、百度、滴滴出行、Intel、微博、唯品会的资深架构师和一线实践者,纳知名研发案例,遇见苏宁云商大数据中心总监陈敏敏、Apache RocketMQ联合创始人冯嘉、饿了么大数据平台部总监毕洪宇等大牛。
票务火热,预购从速,团购立减1000元,更多详情及购票可点击「阅读原文」查看。










