

原文来源
:arXiv
作者:
Jun Hatori、Yuta Kikuchi、Sosuke Kobayashi、Kuniyuki Takahashi、Yuta Tsuboi、Yuya Unno、Wilson Ko、Jethro Tan
「雷克世界」编译:嗯~是阿童木呀、EVA
导语:现如今,随着人工智能的发展,机器人变得越来越普及,人类也越来越需要以一种方便和直观的方式与机器人进行交互。对于许多现实世界的任务来说,使用口语指令比编程更直观。而在接下来的这篇文章中,科学家们提出了首个可以处理无约束口语指令的机器人系统,并且可以通过交互式对话来阐明操作者的意图。为未来的通过口语与人类进行交互的机器人系统奠定了基础,而且这篇文章被称为ICRA 2018关于人机交互(HRI)的最佳论文。
口语自然语言的理解是机器人与人类进行有效沟通的一项基本技能。然而,由于以下几种原因,处理不受约束的口语指令是很有挑战性的:(1)复杂的结构和在口语中使用的各种各样的表达方式,以及(2)人类指令固有的模糊性。在本文中,我们提出了第一个用于控制具有无约束口语语言的机器人的综合系统,它能够有效地解决口语指令的不明确问题。具体地说,我们将基于深度学习的对象检测与自然语言处理技术结合起来,以处理不受约束的口语指令,并提出了一种方法,让机器人通过对话解决指令的不明确问题。通过我们对模拟环境和物理工业机械臂的实验,我们证明了我们的系统能够有效地理解人类操作员的自然指令,并展示了如何通过一个交互式的阐明过程来提高目标选择任务的成功率。
随着机器人变得越来越无所不在,人类也越来越需要以一种方便和直观的方式与机器人进行交互。对于许多现实世界的任务来说,使用口语指令比编程更直观,而且比其他的交流方法(比如触摸屏的用户界面或手势)更通用,因为它可能涉及抽象概念或使用高级指令。因此,使用自然语言作为人类和机器人之间交互的手段是可取的。

图1:通过人机交互进行目标选取的例子。如果给定的指令具有解释不明确性的问题,我们的机器人会要求进行阐明。
然而,要实现解释语言并相应采取行动的机器人概念,有两个主要的挑战。首先,我们日常生活中使用的口语指令既没有预先定义的结构,也没有有限的词汇表,而且通常包括不常见的和非正式的表达方式。例如,“嘿,伙计,抓住那个棕色的毛茸茸的东西”,参见图1。其次,在解释口语语言方面存在固有的不明确性,因为人类并不总是尽可能地使他们的指令明确起来。举个例子,在该环境中可能会有多个“毛茸茸的”对象(如图1所示),在这种情况下,机器人需要反过来问,例如“哪一个?”。尽管正确处理这种多样和模糊的表达是构建家用或服务机器人的关键因素,但是迄今为止,几乎没有做出什么努力以解决这些挑战,尤其是在人机交互的环境中。
在本文中,我们解决了口语人机交流中的这两个挑战,并开发了一个机器人系统,使人类操作员可以使用无约束口语指令进行交流。为了处理复杂的结构和不受约束的语言多样性,我们将现有的用于目标检测模型和目标对象指称表达(object-referring expression)的最佳模型结合并修改到一个集成的系统中,该系统可以处理各种各样的口语表达以及它们在现实世界环境中对各种目标的映射。这种修改使得它可以在没有明确目标类信息(object class information)的情况下对网络进行训练,并实现对未看见目标的零样本识别(zero-shot recognition)。为了处理口语指令中固有的不确定性问题,我们的系统也关注于交互阐明(interactive clarification)的过程,在这个过程中,可以通过对话解决给定指令中的不明确性问题。此外,我们的系统智能体将语言和视觉反馈结合在一起(如图1所示),使得人类操作员可以提供额外的解释来缩小有意义目标的范围,这与人类的交流方式相似。我们表明,口语语言指令确实有效地提高了现实世界中目标选取的端到端精确度。
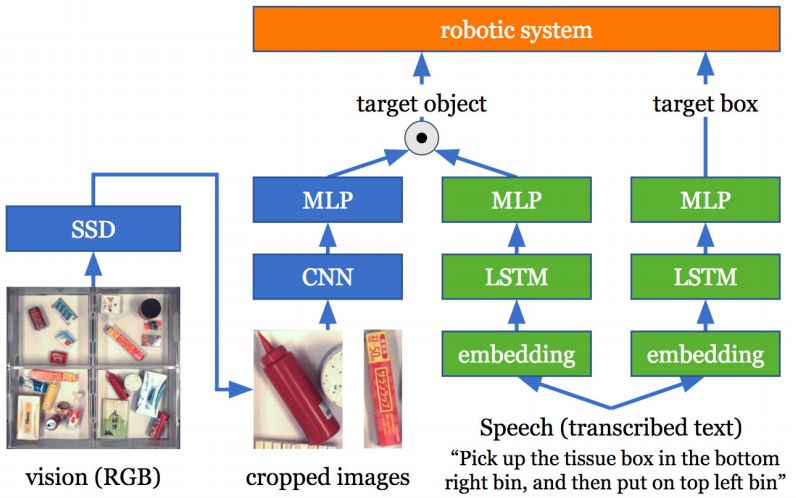
图2:神经网络体系结构概述。使用SSD将从我们的视觉系统输入的图像分割成裁剪图像,然后被馈送到CNN中以提取图像特征。从视觉和文本(语音)输入中提取的图像和文本特征被馈送到目标对象检测模块,而只有文本特征被馈送到目标框选择模型中。
尽管自然语言指令的使用已经在机器人领域得到了关注,但我们的研究是第一个提出一个综合系统,该系统集成了交互式阐明过程,同时通过人机对话支持无约束的口语指令。为了在复杂逼真的环境中对我们的系统进行评估,我们创建了一个新的具有挑战性的数据集,其中包含各种各样的真实世界的目标,且每个目标都用口语指令进行注释。
相关研究
A.用自然语言进行人机交互
自然语言处理最近在机器人领域受到了很多关注。科学家门已经进行了一些关于人机交互的研究,例如那些关注抽象空间概念的表达空间、基数和顺序的概念的研究,或者那些关注如何对机器人进行提问以消除歧义的研究。以往一些科学家的研究表明,空间中的位置关系对于处理多个目标来说至关重要。然而,这些研究隐含性地假定人类指示是精确的,即在可解释性方面不存在模棱两可。而正如我们在上文中所提到的那样,自然语言本质上就是不明确的。
图3:平均(左)和高度混乱(右)环境中的样本示例。每个边框的尺寸是400mm×405mm。
对机器人的基于语言的反馈,特别是在解释不明确的情况下往往被忽略了,除了诸如D.Whitney等人所著的《通过社会反馈减少目标获取交互中的错误》这样的少数研究之外。《通过社会反馈减少对象获取交互中的错误》着重于使用自然语言指令进行目标获取以及通过手势进行指向。然而,实验只能在一个简单的、受控的环境中进行,且最多包含六个已知和已标记的目标。此外,来自机器人的反馈仅限于简单的二元确认:即“是这个吗?”虽然可以通过设计环境和标签并预先对机器人进行教学来执行诸如烹饪等特定任务,但是在环境中放置大量杂项物体的情况下,特别是存在没有一个特定或通用调用名称的目标的情况下,很难对其作出相应的回应。
B.用自然语言理解视觉信息
最近,在与计算机视觉和自然语言处理相关的多模式研究中取得了重大进展。通过使用基于神经网络模型进行的图像字幕,已对图像的理解能力进行了改进和测量。将语言信息映射到视觉语义空间和图像检索也已被纳入研究进程。为了获得更精确的理解,为每个目标或关系密集地标注图像的工作也已经完成。进一步的研究工作涉及在一个存在类似目标的环境中,完成指称表达式,生成或理解有分歧的句子的任务。





