特约作者:史春奇
数据应用学院
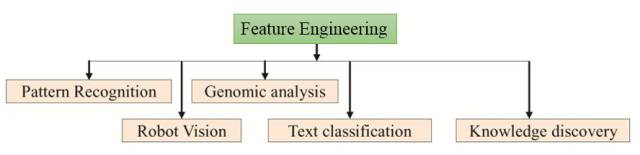
特征选择
(Feature Selection,FS)和
特征抽取
(Feature Extraction, FE)是特征工程(Feature Engineering)的两个重要的方面。 他们之间最大的区别就是
是否生成新的属性
。 FS仅仅对特征
进行排序(Ranking)和选择
, FE更为复杂,需要
重新认识
事物, 挖掘新的角度, 创新性的创立新的属性,
而目前深度学习这么火, 一个很重要的原因是缩减了特征提取的任务。
不过, 目前特征工程依然是各种机器学习应用领域的重要组成部分。
1.为什么要特征选择?
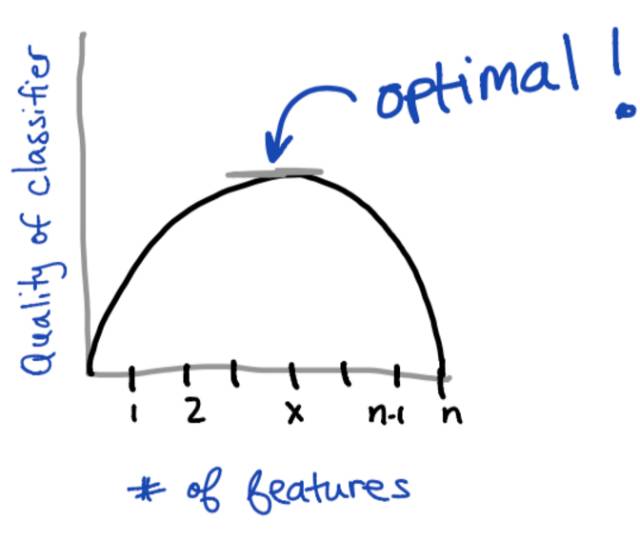
1.1特征选择与分类器性能的关系
一般说来,当固定一个分类器的话, 所选择的特征数量和分类器的效果之间会有一个曲线, 在某个x(1
1.2 为什么特征少了不行?
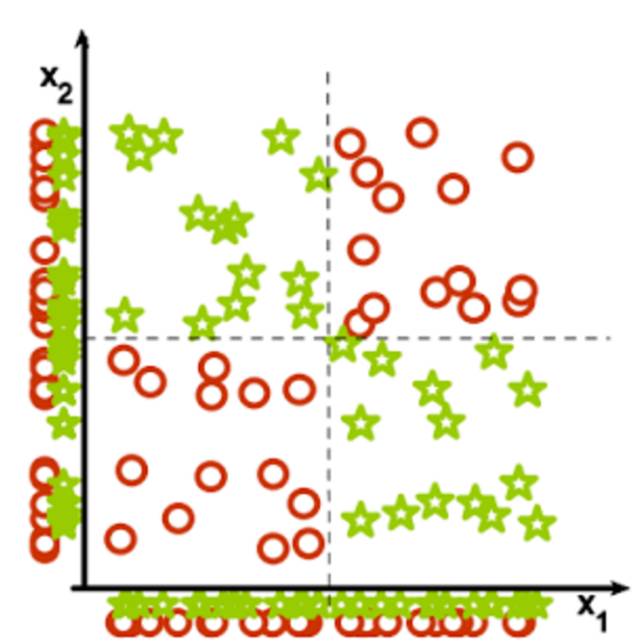
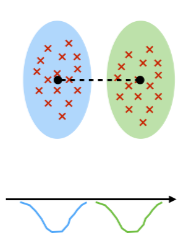
这个比较直观, 特征少了会导致无法区分的情况发生。 如下图所示,仅仅依赖x1或者x2特征, 都无法区分这两类数据, 所以当特征数量过小, 很可能导致
数据重叠
。进而, 所有分类器都会失效。
1.3 为什么特征多了也不行?
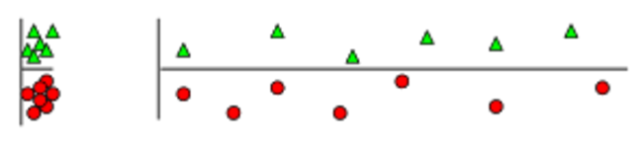
那为什么特征多了也不行呢? 如下图所示,明明根据纵轴来判断就可以容易的区分两类, 但是因为引入了横轴的特征, 使得同类数据在空间中距离
变远,变稀疏
了。 进而使得很多分类器失效。 所以, 特征不是越多越好!
2. 特征选择的一般流程
根据前面如何得到一个最优的子集, 那么特征选择的的一般流程就是, 找一个集合,然后针对某个学习算法, 测试效果如何, 一直循环直到找到最优集合为止。
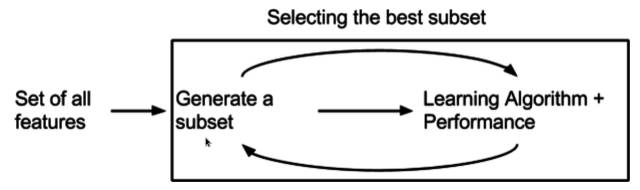
如果把Evaluation再突出表示, 那么整个流程就会是如下图这样一个过程。
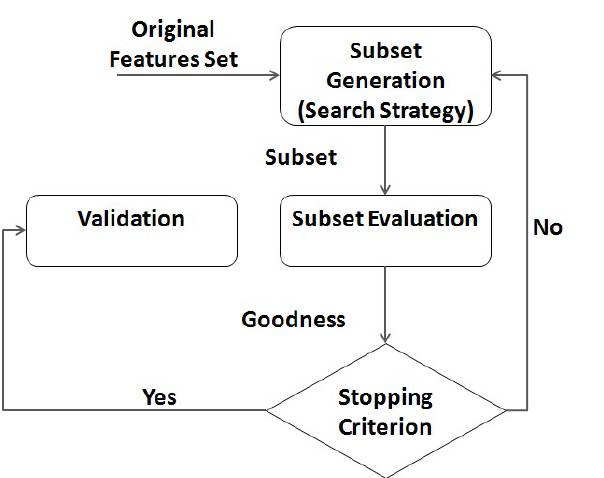
那么按照这个流程, 是不是特征选择就解决呢? 固定一个算法, 然后搜索
(Search)
一个测试子集, 然后进行Cross-Validation进行评价,直到找到最优目标。 那么这个搜索空间有多大呢?假设有n个特征, 每个特征可以选择或者不选择, 那么就是
2的n次方
的搜索空间,n为特征数量。所以基本上
n=10的时候
,就是一个1024次的尝试。如果
每次尝试1分钟
, 光这个就
需要1天时间
。 尤其当n>10的情况, 是非常常见的。
所以当n
穷举法(Exhaustive): 暴力穷尽
贪心法(Greedy Selection): 线性时间
模拟退火(Simulated Annealing): 随机尝试找最优
基因算法(Genetic Algorithm): 组合深度优先尝试
邻居搜索(Variable Neighbor Search): 利用相近关系搜索
我们把基于Cross-Validation和基因算法(GA)的一般流程列在如下:
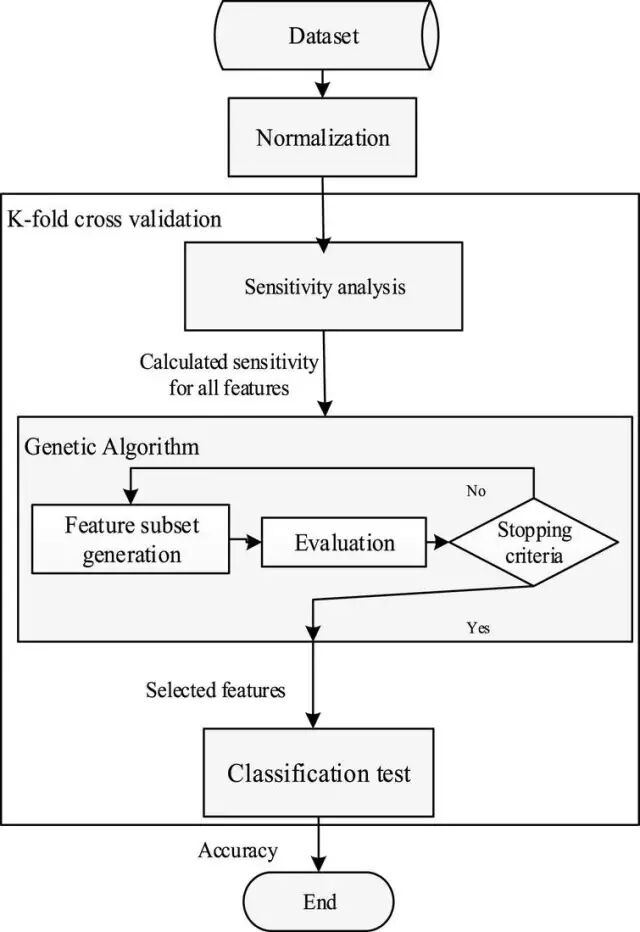
但是, 始终当n很大的时候, 这个
搜索空间会很大
,如何找最优值还是需要一些
经验结论
。
3. 机器学习特征选择的经典三刀?
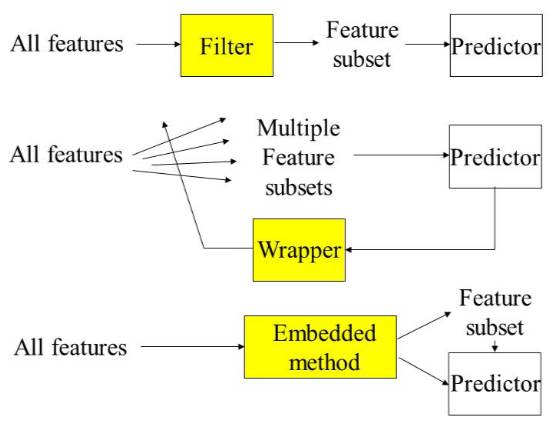
特征选择的经典经验总结起来主要有三刀:
飞刀(Filter)
,
弯刀(Wrapper)
,
电刀(Embedded)
。 类比起来:
小李飞刀
(Filter):
快速
无比, 但是能不能打的准,还得看各自功力。
圆月弯刀
(Wrapper):
实力
无穷, 但是会不会用, 需要点悟性和魔力,还靠点运气。
高频电刀
(Embedded):
模式单调,快速并且效果明显
, 但是如何参数设置, 需要深厚的背景知识。

Filter, Wrapper, Embedded 为什么是具有这些特性呢?
3.1 Filter 过滤式 (飞刀)
顾名思义,就是要基于
贪心的思想
, 把需要的特征筛/滤出来。 一般说来, 基于贪心就需要对特征进行打分。 而这个打分可以基于
领域知识, 相关性, 距离
,
缺失, 稳定性
等等。
单一特征选择
根据每个特征属性和目标属性之间的计算值来进行排序选择:
a. Welch's t-Test:
来判断两个属性的分布的均值方差距离。
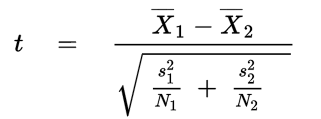
b. Fish-Score
:
和
Welch's t-Test类似, 计算两个分布的距离, 均值只差和方差之和的距离。
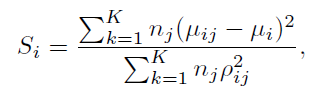
c. Chi-Squared test
:
计算类别离散值之间的相关性。
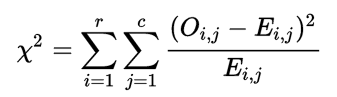
d. Information Gain
:
计算两个划分的一致性。
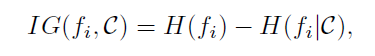
多特征选择
根据多个特征属性和目标属性之间的计算值来进行排序选择:
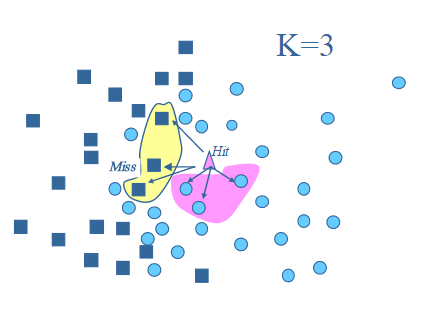
e. Relief-F
: 根据随机选择的样本点,来计算属性之间的相关性。
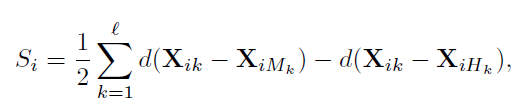
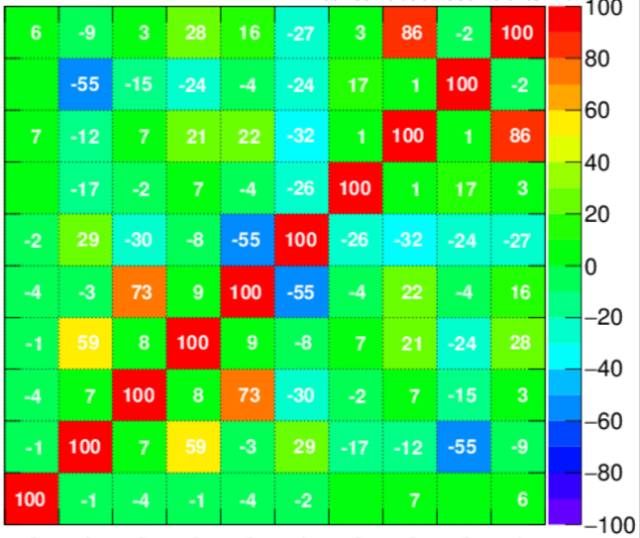
f. Correlation Feature Selection (CFS)
: 利用属性之间的相关性, 进行选择。
3.2. Wrapper 包裹式 (弯刀)
就是先选定特定算法,然后再根据算法效果来选择特征集合。 一般会选用普遍效果较好的算法, 例如Random Forest, SVM, kNN等等。
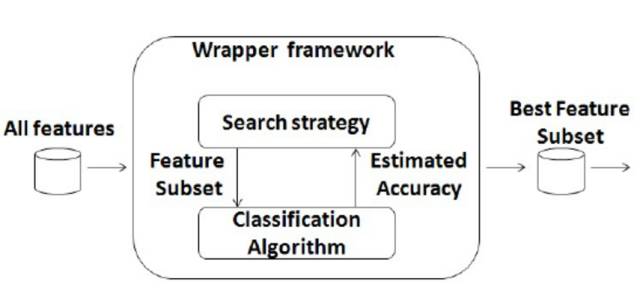
这可以使用前面提到的各种减小搜索空间的尝试。 其中最经典的是使用启发式搜索(Heuristic Search), 而概括的来说主要分为两大类:
g. Forward Selection:
挑出一些属性, 然后慢慢增大挑出的集合。
h. Backward Elimination:
删除一些属性,然后慢慢减小保留的集合。
3.3 Embedded 嵌入式 (电刀)
利用正则化思想, 将部分特征属性的权重
变成零
。 常见的正则化有L1的Lasso,L2的Ridge和混合的Elastic Net。其中L1的算子有明显的特征选择的功能。
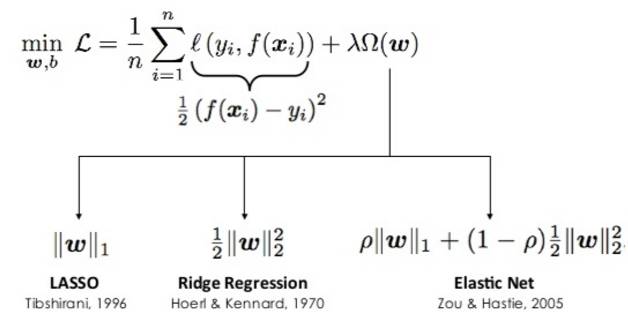
在这里面,比较简单的就是会自动进行特征选择, 而且一次性就搞定了, 速度也不错, 难点就是
损失函数的选择
和
缩放参数
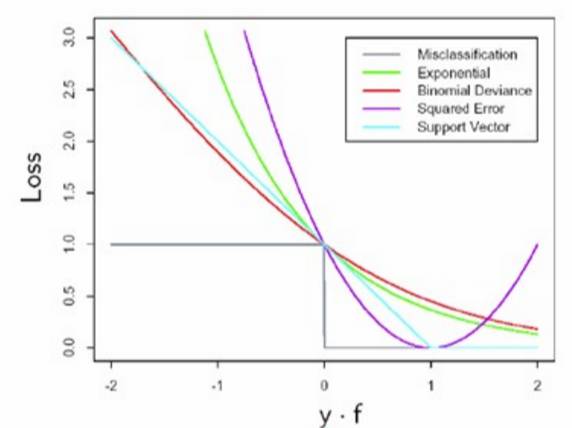
的选择。 常见的损失函数如下图所示:
Binary(0-1) loss: 灰线 对应错误率
Square loss
:
紫线
对应 最新二乘法
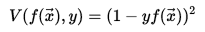
Hinge loss
: 浅蓝 对应 SVM
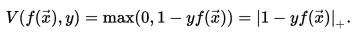
Logistic loss
:红线 对应 逻辑回归
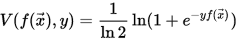
Exponential loss
:绿线 对应 adaboost
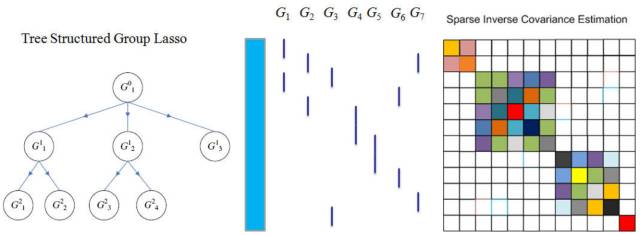
结构化Lasso
除了上述的简单的Lasso,还有结构化的Lasso。
i. Group Lasso:
先将属性进行分组, 然后对每个分组,看成一个属性那样 的采用Lasso的方法选择, 要么全要, 要么全部不要。 再进一步, Sparse Group Lasso再在组内进行选择。
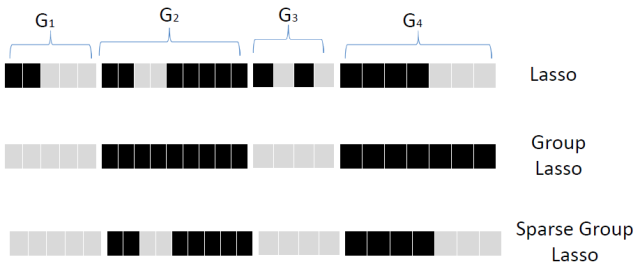
j. Tree-Structured Lasso:
除了前面的扁平(Flat)的结构外, 还有层次化的结构。
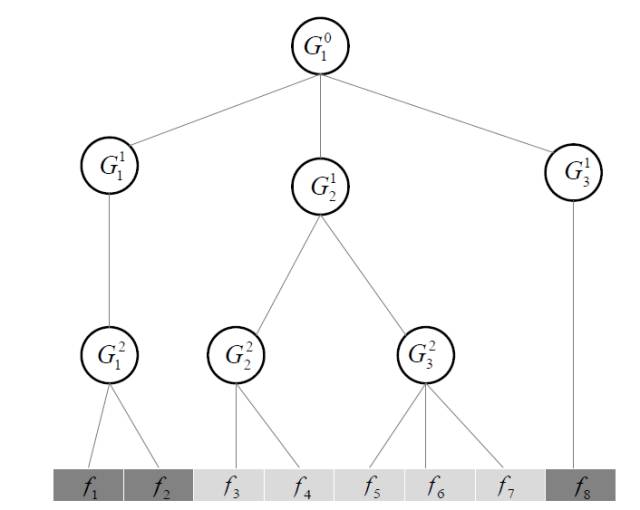
对于这种情况, 同样采用类似
Group Lasso的思想
。 对于一个数的子结构, 要么全要或者全不要,也可以允许分支单独要。
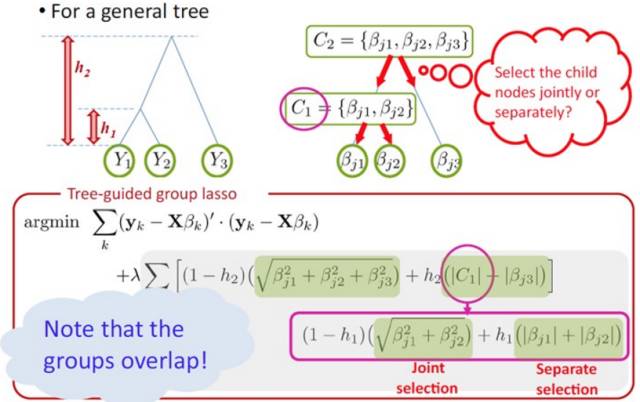
在这种树结构的思想下, 那么每个
树的分支的正则化
惩罚也可以采用不同的形式。
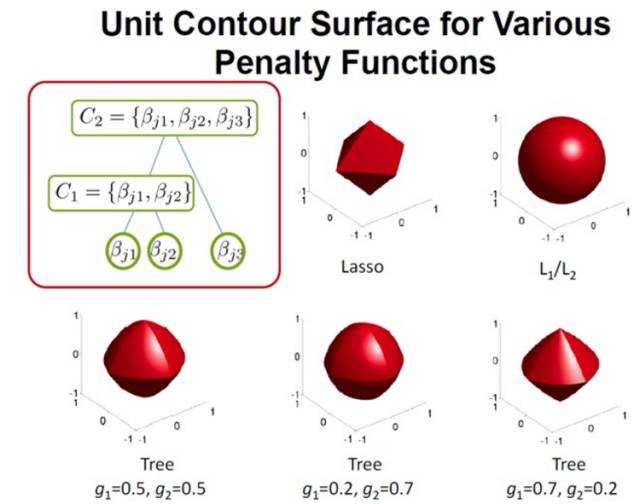
k. Graph Structure Lasso:
更进一步还可以推广到基于图的Lasso
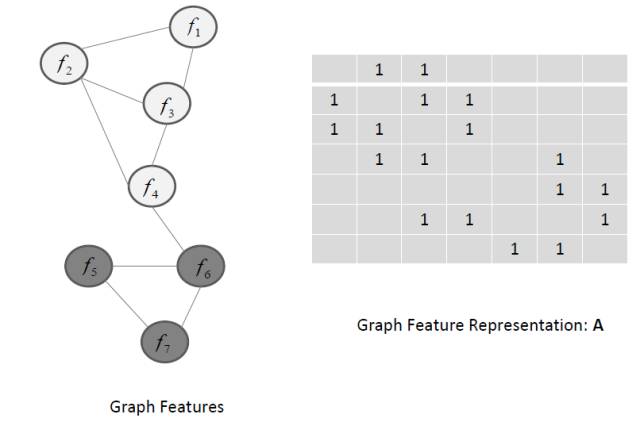
在图的情况下, 那么
两两节点
之间要定义一个惩罚项。
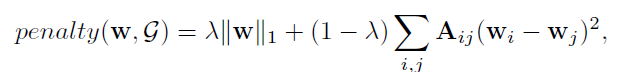
树结构Lasso也可以利用图来表示。
再次强调, 很多时候, 需要综合上面的三刀来进行综合选择。 特征选择不是一个容易的任务噢。
小结, 特征选择的三刀要用的好需要自己实战体会的, 下面再简单归纳下:
Filter (F刀):
优点: 快速
, 只需要基础统计知识
。
缺点:特征之间的组合效应难以挖掘。
Wrapper(W刀):
优点: 直接面向算法优化, 不需要太多知识。
缺点: 庞大的搜索空间, 需要定义启发式策略。
Embedded(E刀):
优点: 快速, 并且面向算法。
缺点: 需要调整结构和参数配置, 而这需要深入的知识和经验。

参考:
http://www.rokkincat.com/blog/2016/04/28/feature-selection
http://www.denizyuret.com/2014/02/machine-learning-in-5-pictures.html





