本文内容非商业用途可无需授权转载,请务必注明作者及本微信公众号、微博ID:唐僧_huangliang,以便更好地与读者互动。

听说
Gen-Z
这个新的互连标准组织已经有段时间了,之前没太仔细研究,直到看了《
FMS2017
闪存峰会演讲资料下载(持续更新)
》中的这份资料,觉得有必要写点东西跟大家分享一下。
内存、
PCIe
带宽跟不上
CPU
核心数增长
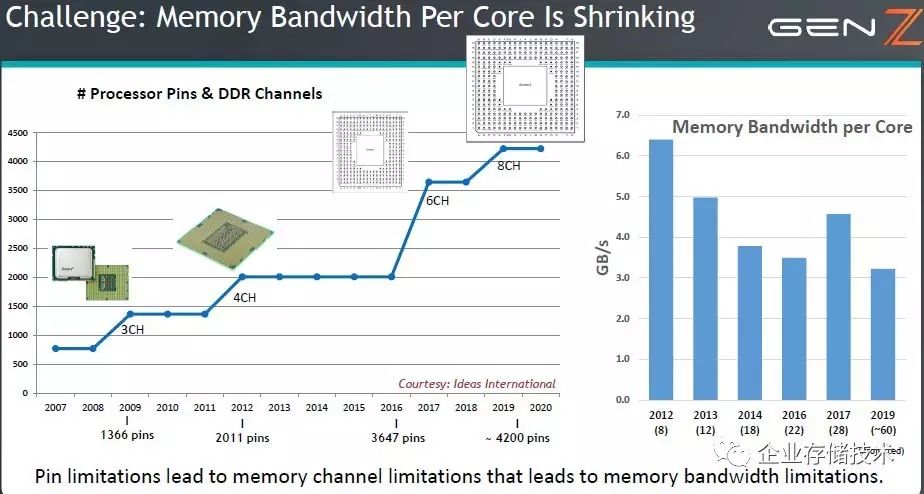
如上图,从
Xeon5500/5600
时代开始
Intel
在
CPU
中集成了内存控制器,当时是每个
LGA-1366
插槽
3
通道;到
XeonE5
时代增加到每个
LGA-2011
插槽
4
通道;及至代号为
Skylake-EP
(
Purley
)的最新一代
Xeon Scalable
服务器,每个
LGA-3647
插槽控制
6
通道内存,参见
《
IntelXeon SP
服务器架构曝光:
ApachePass
、
QuickAssist
》。
AMD
现在又一次想做超车者,在
EPYC
(
Naples
)平台上祭出
LGA-4094
超大封装和
8
通道内存控制器。(扩展阅读:《
AMDEPYC
官方资料乌龙?谈服务器
CPU
互连效率
》)可以预见的是,
Intel
下一代服务器
CPU
插槽也只有增大而没有减小的道理。
而内存通道的增加赶不上核心数量,于是平均
每个
Core
的内存带宽总体呈下降趋势
。最大
28
核的
Xeon SP
核这一代是个例外,不知
2019
年计划的
60
核又会是怎样的设计?

伴随而来的是,
CPU
、内存的功耗和物理空间占用等方面的不断提升。关于上图中列出的
2U 4
节点服务器演进,我在《
2U4
节点
XeonSP
服务器设计:扩展性与散热的权衡
》里面曾有深入一些的讨论,有兴趣的读者可以看看。
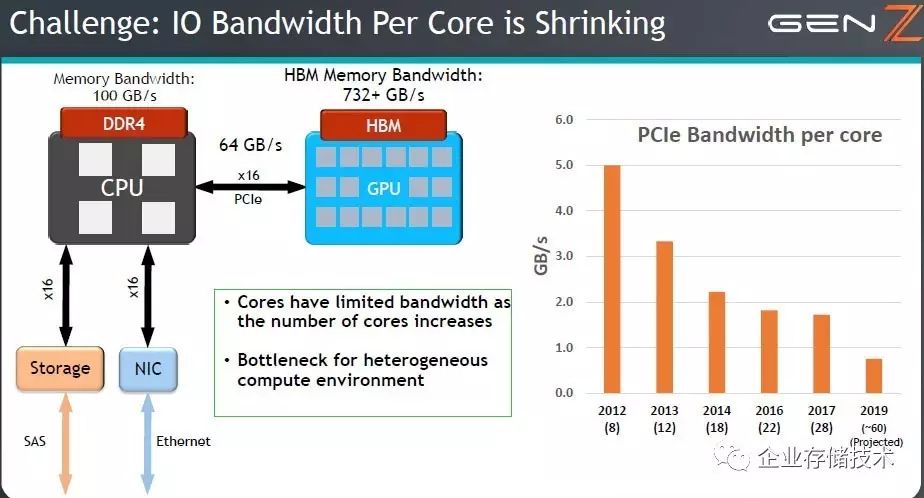
除了内存带宽,没有和计算密度成正比增长的还有
I/O
带宽。
Intel
这一代更新每
CPU
提供的
PCIe lane
数量从
40
加到了
48
个,
PCIe 3.x 8GT/s
到单一设备的带宽不变。到下一代的
PCIe4.0
,
PCIex16
双向总带宽可接近
64GB/s
,而
CPU
本地
DDR4
内存带宽已达
100GB/s
,
GPU
上的
HBM
带宽更是超过
732GB/s
。
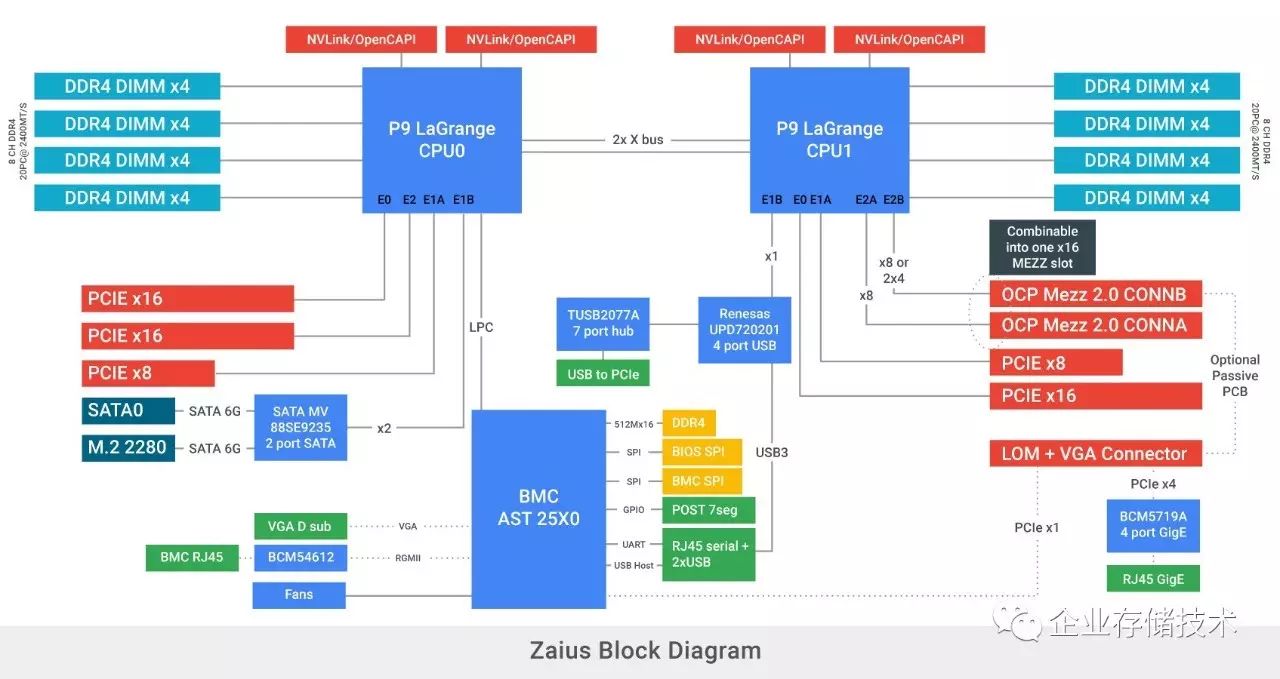
在尚未发布的
POWER9 LaGrange
平台上,整合有
PCI Gen4
控制器,两颗
CPU
一共引出
84lane
,此外每
CPU
还支持
2
个
x8 lane
的
NVLink/OpenCAPI@ 25Gbps
。更多细节参见《
初探
OpenPOWER9
服务器设计:
x86
不再寂寞
》。
有人说是
PCIe 4.0
正式规范不断跳票导致了
Power9
的发布推迟,胡乱猜测一句,
Intel
在这里面有没有点私心呢?另一方面
IBM
也开始多条腿走路,
NVLink/OpenCAPI
的
25Gbps
速率就已经超过了
PCIe 4.0
的
16GT/s
,而
PCIe 5.0
草案中才涉及
25GT/s
和
32GT/s
。
Gen-Z
为什么要以内存为中心?
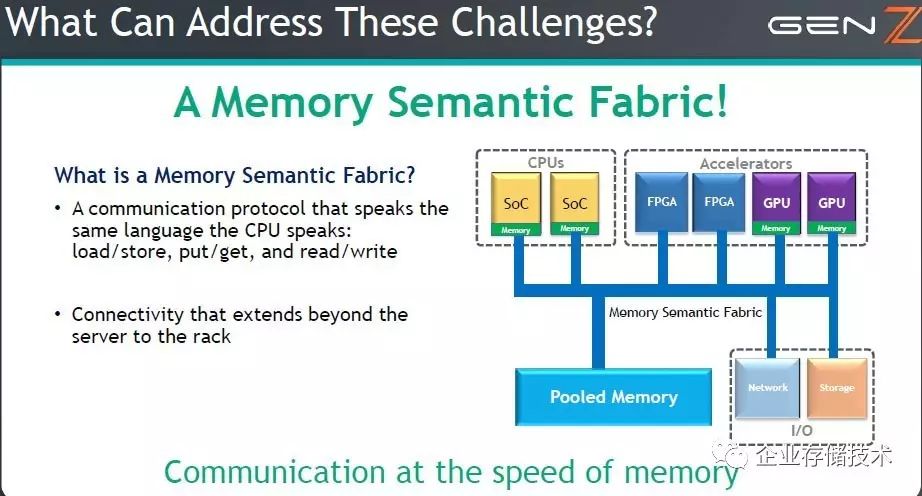
Gen-Z
支持直连、交换或者
Fabric
拓扑
面对挑战,
Gen-Z
提出了以内存为中心的架构,其核心思想是一个
内存语义的
Fabric
通信协议
。如上图,
主内存脱离
CPU
而池化
,
CPU
角色相对弱化为
SoC
(其本地控制的内存可能用于管理),而
FPGA
、
GPU
加速器,网络、存储
I/O
则提升到对等的角色。
是不是和
HP The Mechine
有点相似呢?而该架构显然是
Intel
不愿接受的,因为这些年来他们做了以下事情:
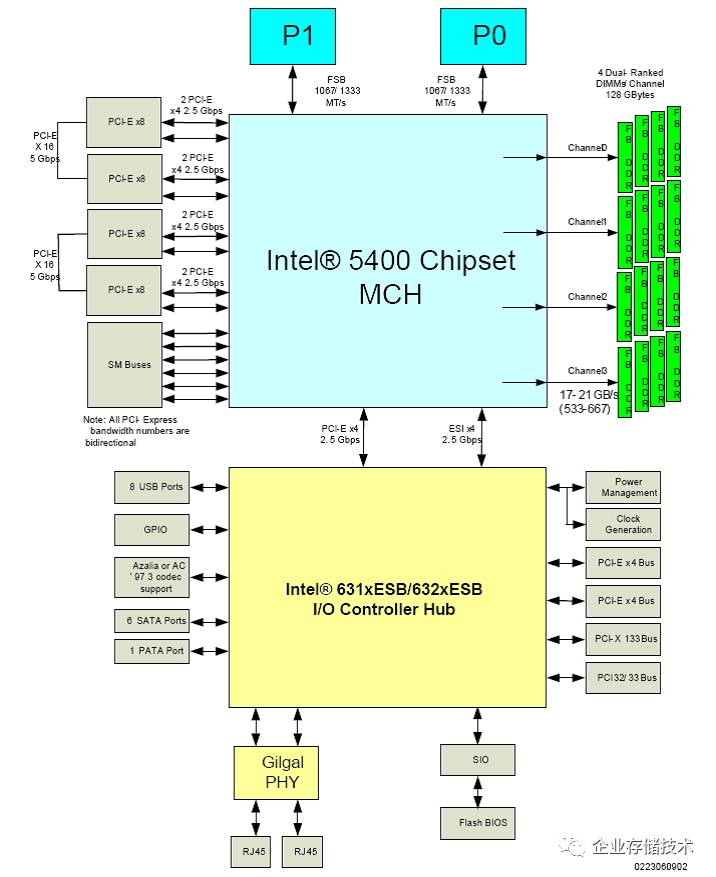
在当初
IntelXeon 5000/5400
系列和之前的服务器平台,
MCH
北桥
一直是整个系统的核心枢纽,向上有
FSB
前端总线连接
CPU
,同时提供内存控制器、
PCIe
控制器,并向下连接南桥。
后来
AMD
从
Opteron
(
K8
)开始在
CPU
中
整合内存控制器
,听说因为他们请来了
Alpha
的架构师,而这个方向也是从
RISC
小型机学来的。
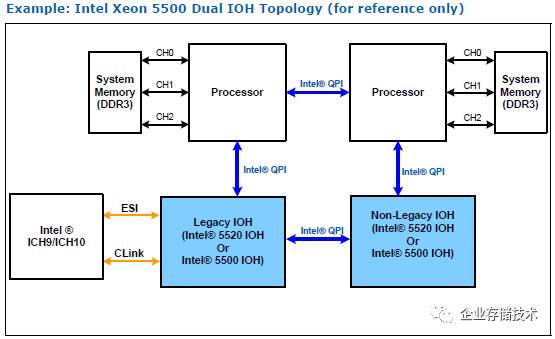
后来的事情许多朋友都清楚,
Intel
为了提高内存性能
/
降低延时,并且让
CPU
间通信不在受
FSB
绕道北桥所累,在
Xeon 5500
平台上取消
MCH
同时引入
QPI
互连,把内存控制器整合进
CPU
。
此时
PCIe
控制器仍保留在
IOH
芯片组中,并且还可以增加第二颗
IOH
以提高
PCIe
扩展能力。但
IOH
使用的
QPI
是
Intel
私有协议,毕竟不能实现像
PCIe Switch
那样拓扑
。再后来到了
Xeon E5
平台,
Intel
进一步提高集成度,
将
PCIe
控制器整合进
CPU
,回到了我们前面的讨论。
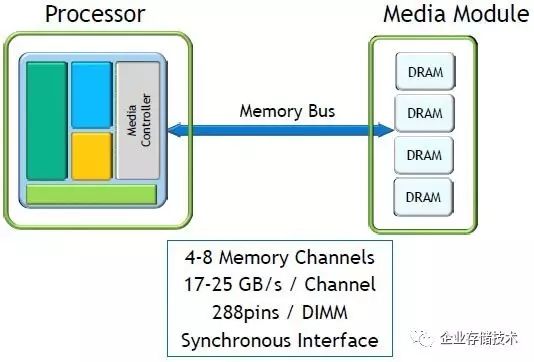
在当前的架构体系(包括
x86
)中,
CPU
控制的
内存总线是每个通道
72bit
(含
ECC
)同步接口
,每个
DDR4 DIMM
内存插槽
288pin
。
4-8
个内存通道提供每通道
17-25GB/s
带宽
。
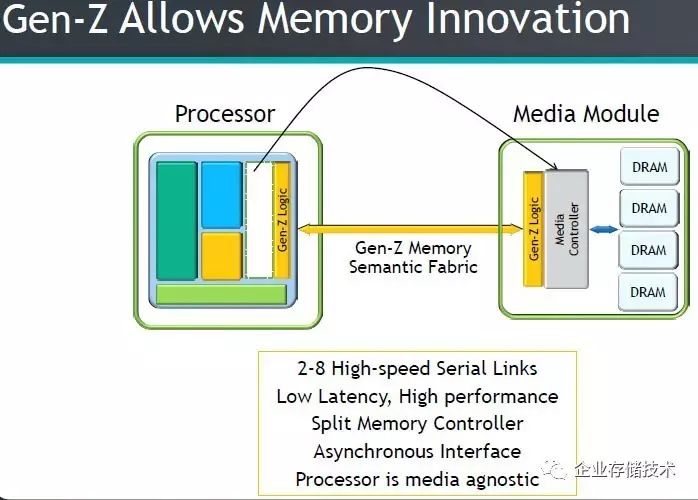
而换成
Memory Semantic Fabric
之后,
处理器和内存(
Media Module
)之间通过
Gen-Z Logic
连接,把内存控制器拆分到
CPU
之外
。此时可以有
2-8
个高速串行链路
,号称低延时、高性能的
异步接口,处理器和内存介质无关性
(即支持
DDR
几代不再取决
/
绑定于
CPU
)。
外置内存控制器是否划算?
其实
Intel
也不是没干过类似的事情,其实在历史上他们曾经两次引入内存缓冲技术,大家还记得
FBD
(全缓冲内存)和
SMI
吗?
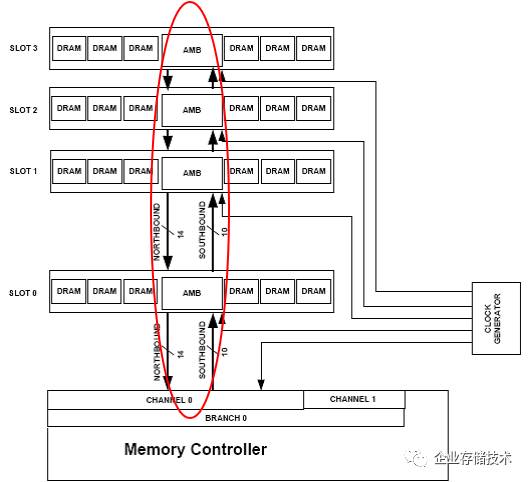
Fully Buffered DIMM
出现于
Intel 5000
系列芯片组,在双路服务器平台上终止于
5400
。当时
刚开始在主板上引入
4
通道内存
,大概是
64/72
位
DDR
接口布线设计遇到难度,于是改用一种
14bit
下行(北向)
/10bit
上行(南向)的接口技术。北桥的内存通道连接到
内存中央的
AMB
芯片
,再由此在同一个通道内的向下串连更多
DIMM
。这个时期遇到的问题是内存不对等的延时增加,以及每条
DIMM
上
AMB
增加了
成本和功耗
。
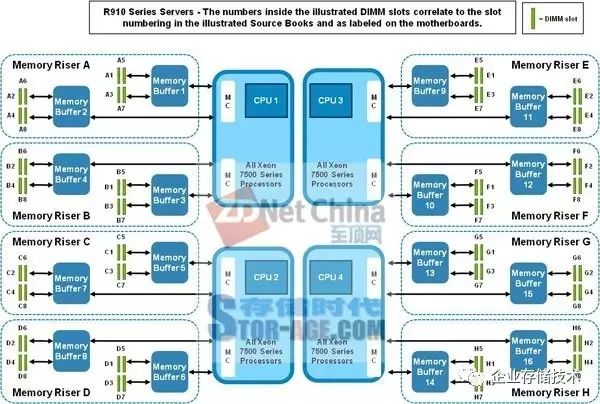
第二次是从
Xeon 7500
一直到
XeonE7 v4
。上图以
Dell PowerEdge R910
服务器资料为例,
4
颗
CPU
支持
8
块内存板,内存控制器
由
SMI
接口经过缓存芯片之后连接通用内存
。提高内存数量和容量的支持是
SAP HANA
类应用喜欢的,但这也带来了
一定的性能影响
。

PowerEdge R910
的内存板,我在《
四路服务器进化:
R930
内存板瘦身、偏置
CPU
散热
》中曾经提到后来的设计尺寸缩小了不少,但增加的
成本和耗电
却不可避免。
最终
Intel
也放弃了这种设计,详情参见《
四路
XeonSP
服务器内存减半:
Intel
葫芦里卖的什么药?
》,我在这里就不再重复。
相比之下,
Gen-Z
的高速串行链路有点类似于用
PCIe
点对点连接
CPU
和内存控制器
,如果只是
从成本和主板设计复杂性上看未必比现在的
Xeon E5
、
SP
划算
。
Gen-Z
的价值还不只这些,我将在明天的下篇中继续和大家讨论以下主题:
-
另类
RSD
:复用
PCIe pin
提升整体内存带宽
-
在更小连接器上跑出更高带宽(
25-100GB/s
)
-
联盟中还缺席了谁?
PCI-SIG
的反应
未完待续
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
HL_Storage

长按二维码可直接识别关注
历史文章汇总
(传送门):
http://chuansong.me/account/huangliang_storage





