消息队列在互联网领域里得到了广泛的应用,它多应用在异步处理、模块之间的解偶和高并发的消峰等场景,消息队列中表现最好的当属Apache开源项目Kafka,Kafka使用支持高并发的Scala语言开发,利用操作系统的缓存原理达到高性能,并且天生具有可分区,分布式的特点,而且有不同语言的客户端,使用起来非常的方便。
Kclient是Kafka生产者客户端和消费者客户端的一个简单易用的框架,它具有高效集成、高性能、高稳定的高级特点。
在继续阅读kclient的功能特性、架构设计和使用方法之前,读者需要对Kafka进行基本的学习和了解。如果读者是Kafka的初学者,而且英文还不错,也可以直接参考Kafka官方在线文档:Kafka 0.8.2 Documentation,如果对英文不感性趣,可以在网上搜索Kakfa的中文资料进行学习,内容需要涵盖Kafka的使用向导以及利用操作系统缓存的“空中接力”、持久化、分片机制、高可用等原理。
本文包含了背景介绍、功能特性、架构设计、使用指南、API简介、后台监控和管理、消息处理机模板项目、以及性能压测相关章节。如果你想使用kclient快速的构建Kafka处理机服务,请参考消息处理机模板项目章节; 如果你想了解kclient的其他使用方式、功能特性、监控和管理等,请参考功能特性、使用指南、API简介、后台监控和管理等章节; 如果你想更深入的理解kclient的架构设计和性能指标,请参考架构设计和性能压测章节。
简化了Kafka客户端API的使用方法, 特别是对消费端开发,消费端开发者只需要实现MessageHandler接口或者相关子类,在实现中处理消息完成业务逻辑,并且在主线程中启动封装的消费端服务器即可。它提供了各种常用的MessageHandler,框架自动转换消息到领域对象模型或者JSON对象等数据结构,让开发者更专注于业务处理。如果使用服务源码注解的方式声明消息处理机的后台,可以将一个通用的服务方法直接转变成具有完善功能的处理Kafka消息队列的处理机,使用起来极其简单,代码看起来一目了然,在框架级别通过多种线程池技术保证了处理机的高性能。
在使用方面,它提供了多种使用方式:
直接使用Java API;
与Spring环境无缝集成;
服务源码注解,通过注解声明方式启动Kafka消息队列的处理机。
除此之外,它基于注解提供了消息处理机的模板项目,可以根据模板项目通过配置快速开发Kafka的消息处理机。
为了在不同的业务场景下实现高性能, 它提供不同的线程模型:
适合轻量级服务的同步线程模型;
适合IO密集型服务的异步线程模型(细分为所有消费者流共享线程池和每个流独享线程池)。
另外,异步模型中的线程池也支持确定数量线程的线程池和线程数量可伸缩的线程池。
框架级别处理了常见的异常,计入错误日志,可用于错误手工恢复或者洗数据,并实现了优雅关机和重启等功能。
同步线程模型
在这种线程模型中,客户端为每一个消费者流使用一个线程,每个线程负责从Kafka队列里消费消息,并且在同一个线程里进行业务处理。我们把这些线程称为消费线程,把这些线程所在的线程池叫做消息消费线程池。这种模型之所以在消息消费线程池处理业务,是因为它多用于处理轻量级别的业务,例如:缓存查询、本地计算等。
异步线程模型
在这种线程模型中,客户端为每一个消费者流使用一个线程,每个线程负责从Kafka队列里消费消息,并且传递消费得到的消息到后端的异步线程池,在异步线程池中处理业务。我们仍然把前面负责消费消息的线程池称为消息消费线程池,把后面的异步线程池称为异步业务线程池。这种线程模型适合重量级的业务,例如:业务中有大量的IO操作、网络IO操作、复杂计算、对外部系统的调用等。
后端的异步业务线程池又细分为所有消费者流共享线程池和每个流独享线程池。下面详细介绍下。
所有消费者流共享线程池:所有消费者流共享线程池对比每个流独享线程池,创建更少的线程池对象,能节省些许的内存,但是,由于多个流共享同一个线程池,在数据量较大的时候,流之间的处理可能互相影响。例如,一个业务使用2个区和两个流,他们一一对应,通过生产者指定定制化的散列函数替换默认的key-hash, 实现一个流(区)用来处理普通用户,另外一个流(区)用来处理VIP用户,如果两个流共享一个线程池,当普通用户的消息大量产生的时候,VIP用户只有少量,并且排在了队列的后头,就会产生饿死的情况。这个场景是可以使用多个topic来解决,一个普通用户的topic,一个VIP用户的topic,但是这样又要多维护一个topic,客户端发送的时候需要显式的进行判断topic目标,也没有多少好处。
每个流独享线程池:每个流独享线程池使用不同的异步业务线程池来处理不同的流里面的消息,互相隔离,互相独立,不互相影响,对于不同的流(区)的优先级不同的情况,或者消息在不同流(区)不均衡的情况下表现会更好,当然,创建多个线程池会多使用些许内存,但是这并不是一个大问题。
另外,异步业务线程池支持确定数量线程的线程池和线程数量可伸缩的线程池。
对于消息处理过程中产生的业务异常,当前在业务处理的上层捕捉了Throwable, 在专用的错误恢复日志中记录出错的消息,后续可根据错误恢复日志人工处理错误消息,也可重做或者洗数据。TODO:考虑实现异常Listener体系结构, 对异常处理实现监听者模式,异常处理器可插拔等,默认打印错误日志。
由于默认的异常处理中,捕捉异常,在专用的错误回复日志中记录错误,并且继续处理下一个消息。考虑到可能上线失败,或者上游消息格式出错,导致所有消息处理都出错,堆满错误恢复日志的情况,我们需要诉诸于报警和监控系统来解决。
由于消费者本身是一个事件驱动的服务器,类似Tomcat,Tomcat接收HTTP请求返回HTTP响应,Consumer则接收Kafka消息,然后处理业务后返回,也可以将处理结果发送到下一个消息队列。所以消费者本身是非常复杂的,除了线程模型,异常处理,性能,稳定性,可用性等都是需要思考点。既然消费者是一个后台的服务器,我们需要考虑如何优雅的关机,也就是在消费者服务器在处理消息的时候,如果关机才能不导致处理的消息中断而丢失。
优雅关机的重点在于解决如下3个问题:
第一个问题: 如果一个后台程序运行在控制台的前台,通过Ctrl + C可以发送退出信号给JVM,也可以通过kill -2 PS_IS 或者 kill -15 PS_IS发送退出信号,但是不能发送kill -9 PS_IS, 否则进程会无条件强制退出。JVM收到退出信号后,会调用注册的钩子,我们通过的注册的JVM退出钩子进行优雅关机。
第二个问题: 线程分为Daemon线程和非Daemon线程,一个线程默认继承父线程的Daemon属性,如果当前线程池是由Daemon线程创建的,则Worker线程是Daemon线程。如果Worker线程是Daemon线程,我们需要在JVM退出钩子中等待Worker线程完成当前手头处理的消息,再退出JVM。如果不是Daemon线程,即使JVM收到退出信号,也得等待Worker线程退出后再退出,不会丢掉正在处理的消息。
第三个问题: 在Worker线程从Kafka服务器消费消息的时候,Worker线程可能处于阻塞,这时需要中断线程以退出,没有消息被丢掉。在Worker线程处理业务时有可能有阻塞,例如:IO,网络IO,在指定退出时间内没有完成,我们也需要中断线程退出,这时会产生一个InterruptedException, 在异常处理的默认处理器中被捕捉,并写入错误日志,Worker线程随后退出。
kclient提供了三种使用方法,对于每一种方法,按照下面的步骤可快速构建Kafka生产者和消费者程序。
1) 下载源代码后在项目根目录执行如下命令安装打包文件到你的Maven本地库。
mvn install
2) 在你的项目pom.xml文件中添加对kclient的依赖。
com.robert.kafka
kclient-core
0.0.1
3) 根据Kafka官方文档搭建Kafka环境,并创建两个Topic, test1和test2。
4) 然后,从Kafka安装目录的config目录下拷贝kafka-consumer.properties和kafka-producer.properties到你的项目类路径下,通常是src/main/resources目录。
Java API提供了最直接,最简单的使用kclient的方法。
构建Producer示例:

构建Consumer示例:


kclient可以与Spring环境无缝集成,你可以像使用Spring Bean一样来使用KafkaProducer和KafkaConsumer。
构建Producer示例:
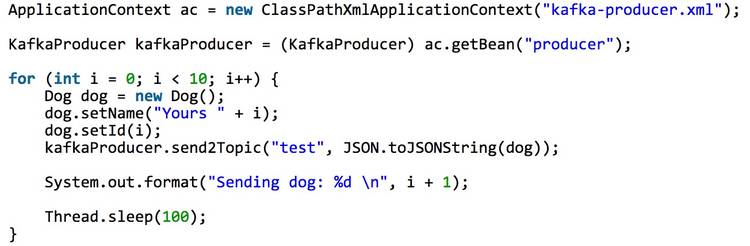

构建Consumer示例:



kclient提供了类似Spring声明式的编程方法,使用注解声明Kafka处理器方法,所有的线程模型、异常处理、服务启动和关闭等都由后台服务自动完成,极大程度的简化了API的使用方法,提高了开发者的工作效率。
注解声明Kafka消息处理器:

注解启动程序:

注解Spring环境配置:

KafkaProducer类提供了丰富的API来发送不同类型的消息,它支持发送字符串消息,发送一个普通的Bean,以及发送JSON对象等。在这些API中可以指定发送到某个Topic,也可以不指定而使用默认的Topic。对于发送的数据,支持带Key值的消息和不带Key值的消息。
发送字符串消息:

发送Bean消息:

发送JSON对象消息:

KafkaConsumer类提供了丰富的构造函数用来指定Kafka消费者服务器的各项参数,包括线程池策略,线程池类型,流数量等等。
使用PROPERTIES文件初始化:

使用PROPERTIES对象初始化以及消息处理器注解、消息处理机模板项目可以查看以下链接继续阅读:
http://www.jianshu.com/p/304f2fd8388b
Benchmark应该覆盖推送QPS、接收处理QPS以及单线程、多线程生产者的用例。
用例1: 轻量级服务同步线程模型和异步线程模型的性能对比。
用例2: 重量级服务同步线程模型和异步线程模型的性能对比。
用例3: 重量级服务异步线程模型中所有消费者流共享线程池和每个流独享线程池的性能对比。
用例4: 重量级服务异步线程模型中每个流独享线程池的对比的确定数量线程的线程池和线程数量可伸缩的线程池的性能对比。
由于笔者在发文的时候还没有时间完成前面四种场景的压测,暂时留给读者亲自动手,作为一个练习。
尽管本文设计和实现的kclient项目提供了许多高级功能,并且使用起来方便,而且笔者在几家公司里在线上进行了应用,已经发挥了不少的作用,但是,还有一些细节需要提高。
kclient处理器项目中管理Restful服务暂时只提供了获得状态的API,需要进行进一步的丰富,增加对线程池的监控,以及消息处理性能的监控。
当前注解@ErrorHandler里面的exception参数为必选,完全可以使用方法第一参数进行推导,简化开发人员配置的工作。
模板项目还不完善,需要增加启动和关闭脚本,这样读者可以直接拷贝使用。
尽管线上应用已经证明了kclient没有性能问题,但是开发一款中间件系统是需要闭环的,需要尽快把性能压测这块昨晚并且形成压测报表。
今日荐文
点击下方图片即可阅读

今年,架构师关注的技术点有何不同?从云计算、大数据、微服务、容器,到现在的人工智能,架构师应该怎么做?这里推荐一场会议,为你总结了100+国内外技术专家现阶段的架构实践,8折即将截止,点击“阅读原文”,看看对你有何启发。









