
向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
本文github源码地址:
在公众号 datadw 里 回复 CNN 即可获取。
这几周因为在做竞赛所以没怎么看论文刷题写博客,今天抽时间把竞赛用到的东西总结一下。先试水了一个很小众的比赛–文因互联,由AI100举办,参赛队不足20个,赛题类型是文本分类。选择参赛的主要原因是其不像阿里们举办的竞赛那样,分分钟就干一件事就是特征工程和调参,然后数据又多又乱,不适合入门。其次一个原因就是目前我的研究方向就是NLP,之前也做过一个文本分类的东西,所以就参赛了。这里将主要介绍我在比赛中用到的几个模型,从理论到代码实现进行总结。
1,数据集
大家可以到竞赛官网查看赛题并下载数据集,数据集中主要包含下面几个文件,可见数据集很小也很简单,只需要使用training.csv文件进行训练我们的文本分类模型,使用testing.csv进行预测并提交结果即可:
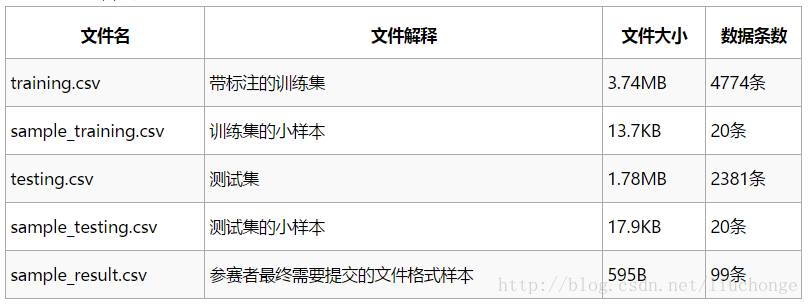
下面是训练集的前两行,每一行的第一个数字表示该行文本的类别,后面的描述就是要建模的文本。这个数据集是11个公司的描述数据,我们要根据4774条训练数据去预测2381条数据的类别标签。除此之外,我们还可以看到这些训练数据存在较严重的类别不平衡问题。如下图所示:

2,合晟资产是一家专注于股票、债券等二级市场投资,为合格投资者提供专业资产管理服务的企业。公司业务范围包括资产管理、投资咨询和投资顾问服务。公司管理的私募基金产品主要包括股票型、债券型资产管理计划或证券投资基金,管理总资产规模80亿元左右。根据中国证券投资基金业协会数据,公司管理的私募证券投资基金(顾问管理)类规模较大,公司管理规模处于50亿元以上的第一梯队。
2,公司的主营业务为向中小微企业、个体工商户、农户等客户提供贷款服务,自设立以来主营业务未发生过变化。
了解完数据集,接下来我们开始进行文本分类,开始提交结果。
2, 朴素贝叶斯分类法
在这里插句题外话,往往这种竞赛大家喜欢一上来什么都不做先提交一个结果站站场面==也就是提交一个随机结果、均值等。因为我看到这个比赛的时候都已经快结束了,比较匆忙,所以第一次提交的也是直接用随机数生成的,后来还自作多情的按照训练集的类比占比作为每个类别概率生成随机数(结果显示确实有提高),代码如下所示:
import numpy as np
with open('output/random_out.csv', 'w') as f:
for i in range(1, 2382):
f.write(str(i))
f.write(',')
aa = np.random.random()
b = 0
if aa <= 0.25:
b = 3
elif aa <= 0.5:
b = 4
elif aa <= 0.7:
b =6
elif aa <= 0.775:
b=7
elif aa <= 0.825:
b = 5
elif aa <= 0.875:
b = 8
elif aa <= 0.925:
b = 10
elif aa <= 0.95:
b = 11
elif aa <= 0.975:
b = 2
elif aa <= 1:
b = 9
f.write(str(b))
f.write('\n')
import numpy as npwith open('output/random_out.csv', 'w') as f: for i in range(1, 2382):
f.write(str(i))
f.write(',')
aa = np.random.random()
b = 0
if aa <= 0.25:
b = 3
elif aa <= 0.5:
b = 4
elif aa <= 0.7:
b =6
elif aa <= 0.775:
b=7
elif aa <= 0.825:
b = 5
elif aa <= 0.875:
b = 8
elif aa <= 0.925:
b = 10
elif aa <= 0.95:
b = 11
elif aa <= 0.975:
b = 2
elif aa <= 1:
b = 9
f.write(str(b))
f.write('\n')
好,接下来说正经的,我用的第一种方法就是朴素贝叶斯,可以参见我之前的一篇博客http://blog.csdn.net/liuchonge/article/details/52204218
介绍了使用CHI选择特征,TFIDF计算特征权重,朴素贝叶斯分类的整体流程。因为之前做了这样的尝试,所以这里直接套过来看看效果如何,代码入下,这里的代码都是自己实现的,太丑,其实可以直接调用gensim的接口去做,以后有时间改改代码:
本文github源码地址:
在公众号 datadw 里 回复 CNN 即可获取。
这里我们可以为每个类选出最具代表性的十个词语看一下,从下面的特征词可以看出来,我们程序提取的特征词还是很具有类别区分度的,也可以看出第四类和第九类、第五类和第八类较为相似,可能在分类上会比较难区分:
feature_words = [[u'物业管理', u'物业', u'房地产', u'顾问', u'中介', u'住宅', u'商业', u'开发商', u'招商', u'营销策划'],
[u'私募', u'融资', u'金融', u'贷款', u'基金', u'股权', u'资产', u'小额贷款', u'投资', u'担保'],
[u'软件', u'互联网', u'平台', u'信息化', u'软件开发', u'数据', u'移动', u'信息', u'系统集成', u'运营'],
[u'制造', u'安装', u'设备', u'施工', u'机械', u'工程', u'自动化', u'工业', u'设计', u'装备'],
[u'药品', u'医药', u'生物', u'原料药', u'药物', u'试剂', u'GMP', u'片剂', u'制剂', u'诊断'],
[u'材料', u'制品', u'塑料', u'环保', u'新型', u'化学品', u'改性', u'助剂', u'涂料', u'原材料'],
[u'养殖', u'农业', u'种植', u'食品', u'加工', u'龙头企业', u'产业化', u'饲料', u'基地', u'深加工'],
[u'医疗器械', u'医疗', u'医院', u'医用', u'康复', u'治疗', u'医疗机构', u'临床', u'护理'],
[u'汽车', u'零部件', u'发动机', u'整车', u'模具', u'C36', u'配件', u'总成', u'车型'],
[u'媒体', u'制作', u'策划', u'广告', u'传播', u'创意', u'发行', u'影视', u'电影', u'文化'],
[u'运输', u'物流', u'仓储', u'货物运输', u'货运', u'装卸', u'配送', u'第三方', u'应链', u'集装箱']]
接下来调用train.py函数,就可以得到我们的预测结果,这里我使用了朴素贝叶斯、决策树、SVC三种算法,但是结果显示朴素贝叶斯效果更好,根据参数不同测试集准确率大概达到了78%~79%左右。此外还有几个地方可以调节:
特征词维度的选择,即上面代码feature_select_use_new_CHI()函数中每个类别选择多少个特征词,取值范围在100-500
特征权重的计算方式,即上面代码document_features()函数中对每个特征词的权重计算方式,我们可以认为只要出现就记为1,否则为零;或者使用其在该文本中出现次数作为权重;或者使用TF-IDF作为权重,或者其他方法。
分类器的选择及参数调整,其实我们应该取出500条记录作为测试集去验证模型好坏以及作为参数选择的依据,但是因为时间比较紧迫,所以我并未作这部分工作==
documents_feature =json.load(open('tmp/documents_feature.txt', 'r'))
test_documents_feature = json.load(open('tmp/test_documents_feature.txt', 'r'))
print "开始训练分类器"classifier = nltk.NaiveBayesClassifier.train(documents_feature)results = classifier.classify_many([fs for fs in test_documents_feature])with open('output/TFIDF_out.csv', 'w') as f: for i in range(2381):
f.write(str(i+1))
f.write(',')
f.write(str(results[i]+1))
f.write('\n')
此外,在获得了上面所说的类别特征词之后(每类取十个),我还尝试着用简单的类别匹配方法进行分类,思路很简单,就是看测试集包含哪个特征集中的单词更多,代码入下:
result = []
qq = 0with open('data/testing.csv', u'r') as f: for line in f:
content = ""
for aa in line.split(',')[1:]:
content += aa
word_list, word_set = jieba_fenci(content, stopwords_list)
label = 2
count = 0
for i, cla in enumerate(feature_words):
tmp = 0
for word in word_list: if word in cla:
tmp += 1
if tmp > count:
count = tmp
label = i+1
if count == 0:
qq += 1
result.append(label)
result = []
qq = 0with open('data/testing.csv', u'r') as f: for line in f:
content = ""
for aa in line.split(',')[1:]:
content += aa
word_list, word_set = jieba_fenci(content, stopwords_list)
label = 2
count = 0
for i, cla in enumerate(feature_words):
tmp = 0
for word in word_list: if word in cla:
tmp += 1
if tmp > count:
count = tmp
label = i+1
if count == 0:
qq += 1
result.append(label)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
这个效果一般,准确率好像是在69%或者74%左右,记不太清了。
3,XGBoost算法–文本分类
考虑到xgboost算法在各类竞赛中都有很好的效果,我也决定使用该算法尝试一下效果如何,在网上找了一篇博客,直接套用到这里。我们使用所有的词作为特征进行one-hot编码(使用from sklearn.feature_extraction.text import CountVectorizer和 from sklearn.feature_extraction.text import TfidfTransformer),代码如下:
本文github源码地址:
在公众号 datadw 里 回复 CNN 即可获取。
import xgboost as xgbimport csvimport jiebaimport numpy as npfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfTransformerdef readtrain(path):
with open(path, 'rb') as csvfile:
reader = csv.reader(csvfile)
column1 = [row for row in reader]
content_train = [i[1] for i in column1]
opinion_train = [int(i[0])-1 for i in column1]
print '训练集有 %s 条句子' % len(content_train)
train = [content_train, opinion_train] return traindef stop_words():
stop_words_file = open('stop_words_ch.txt', 'r')
stopwords_list = [] for line in stop_words_file.readlines():
stopwords_list.append(line.decode('gbk')[:-1]) return stopwords_listdef segmentWord(cont):
stopwords_list = stop_words()
c = [] for i in cont:
text = ""
word_list = list(jieba.cut(i, cut_all=False)) for word in word_list: if word not in stopwords_list and word != '\r\n':
text += word
text += ' '
c.append(text) return cdef segmentWord1(cont):
c = [] for i in cont:
a = list(jieba.cut(i))
b = " ".join(a)
c.append(b) return c
train = readtrain('data/training.csv')
train_content = segmentWord1(train[0])
train_opinion = np.array(train[1]) print "train data load finished"test = readtrain('data/testing.csv')
test_content = segmentWord(test[0])print 'test data load finished'vectorizer = CountVectorizer()
tfidftransformer = TfidfTransformer()
tfidf = tfidftransformer.fit_transform(vectorizer.fit_transform(train_content))
weight = tfidf.toarray()print tfidf.shape
test_tfidf = tfidftransformer.transform(vectorizer.transform(test_content))
test_weight = test_tfidf.toarray()print test_weight.shape
dtrain = xgb.DMatrix(weight, label=train_opinion)
dtest = xgb.DMatrix(test_weight) param = {'max_depth':6, 'eta':0.5, 'eval_metric':'merror', 'silent':1, 'objective':'multi:softmax', 'num_class':11} evallist = [(dtrain,'train')] num_round = 100 bst = xgb.train(param, dtrain, num_round, evallist)
preds = bst.predict(dtest)with open('XGBOOST_OUTPUT.csv', 'w') as f: for i, pre in enumerate(preds):
f.write(str(i + 1))
f.write(',')
f.write(str(int(pre) + 1))
f.write('\n')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
效果不错,测试集可以达到80%的准确度,出乎意料的好==然后我还尝试将提取出来的特征用到XGBoost模型上,也就是在train.py中调用xgboost模型,结果发现准确度出不多也是80%左右,没有很大提升。其实这里也应该做参数优化的工作,比如xgboost的max_depth、n_estimate、学习率等参数等应该进行调节,因为时间太紧我这部分工作也没做,而是使用的默认设置==
4, 卷积神经网络
这里使用YOON KIM的模型框架,代码使用WILDML的,可以参见我之前的一篇博客,为了适用于本任务,修改一下 data_helpers.py文件中的代码,增加load_AI100_data_and_labels()函数,用于读取训练集和测试集。然后就可以训练了,这里使用随机初始化的词向量,让其随模型训练,效果不错,测试集精确度达到了82%以上,之后我还尝试了一下使用char-cnn模型,但是效果不太好,根本就没有办法收敛,可能是参数选择的不对或者训练集太小了,但是到这比赛就结束了,我也没有时间和机会去尝试更所得模型和参数==
5,别人的方法
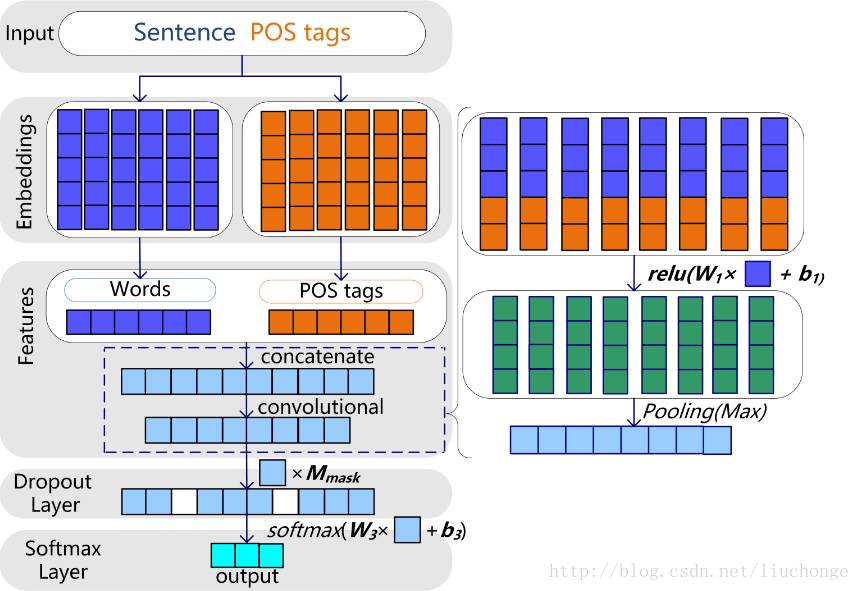
赛后,举办方请第一名的选手分享了方法和经验,我发现他也是使用的卷积神经网络,不过分词的时候加入了词性标注,然后使用gensim单独训练词向量,然后卷积层的使用了1000个卷积核等等吧,其分享链接为:
Tensorflow的CNNs模型实战:根据短文本对企业分类
模型架构如下图所示:
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注










