
图:pixabay
原文来源:arXiv
作者:YuXuan Liu、Abhishek Gupta、Pieter Abbeel、Sergey Levine
「机器人圈」编译:嗯~阿童木呀、BaymaxZ
模仿学习(Imitation learning)是自主系统获取控制策略的有效方法,尤其是当明确的奖励函数不可用时,可使用由专家,通常是人类操作者提供的监督作为演示。然而,标准的模仿学习方法假设智能体可以接收到“观察-行动”元组样本,而这些往往可以提供给监督学习算法。这与人类和动物的模仿行为是截然相反的:我们观察另一个人的行为表现,然后找出哪些行动将实现这些行为,以何种视角、周围环境以及具体体现补偿这种变化。我们将这种模仿学习称为观察模仿(imitation-from-observation),并提出了一种具有环境转化和深度强化学习的、基于视频预测的模仿学习方法。这便引出模仿学习中的假设,即演示应该包括在同一环境中的观察和行动,并且可以进行各种有趣的应用,包括学习机器人技能,如观察人类使用工具的视频所涉及到的工具,进行简单使用。实验结果表明,我们的方法可以实现一系列基于常见家务活动建模的、真实世界机器人任务的观察模仿。
学习(learning)可以使诸如机器人之类的自主智能体,去学习适用于各种非结构化环境的复杂行为技能。为了使自主智能体能够学习这些技能,必须向他们提供一个监督信号,从而指示出所需行为的目标。
这种监督通常来自两个来源,其中之一:强化学习中的奖励函数,指定哪些状态和行动是可取的,或者是模仿学习中的专家演示,提供成功行为的样本。这两种模式已经与诸如深度神经网络这样的高容量模型相结合,以便能够通过原始的感官观察来学习复杂的技能(Ross,Mnih和 Levine等人在其论文中皆有所提及)。强化学习的一个主要优点是,智能体可轻易获得技能,而这只需要通过奖励函数对目标所提供的一个高级描述进行审查和查错就可以实现。但是,奖励函数可能难以手动指定,特别是当任务的成功只能从诸如摄像机图像的复杂观察中确定时(Edwards等人于2016所著论文中有所提及)。
一般来说,模仿学习可通过使用成功行为的样本来绕过这个问题。通用的模仿学习的方法包括通过行为克隆的直接模仿学习(Pomerleau于1988所著论文和Bojarski等人于2016所著论文中皆有所提及)和通过反强化学习的奖励函数学习(Ng和Russell于2000所著论文中有所提及)。这两种设置通常都假设智能体可以接收到包含“观察-行动”元组序列的样本,然后必须学习一个函数,在泛化到新情景时,将样本序列完成从观察到行动的映射。
但是,这种模仿概念与人类和动物所进行的模仿有着天壤之别:当我们在观察别人从而学习新技能时,我们不接受以自我为中心的观察和参考标准。观察是从其他视角中获得的,而行动是未知的。此外,人类不仅能够从现场观察中学习演示行为,还可以从与自己有着明显不同的行为的视频中进行学习。
我们可以设计能够在这种情况下成功实施的模仿学习方法吗?而针对这个问题的解决方案将在机器人技术方面具有相当可观的实际价值,因为它产生的模仿学习算法可以直接利用那些记录人们执行期望行为的自然视频,而这个是可以从互联网上获得的。
我们把这个问题定义为为观察模仿(imitation-from-observation)。观察模仿的目标是仅学习来自所期望的行为的观察序列(例如摄像机图像)的策略,而每个序列是从环境差异下获得的。环境的差异可能包括实时环境的变化,正在操作对象的变化,以及视角的变化,而观察结果可能是由图像序列组成的。我们将在下文第3节正式定义这个问题。
我们的观察模仿算法是基于学习环境转化模型的,它可以将论证从一个环境(例如,第三人称视角和人类演示者)转换到另一个环境中(例如,第一人称视角和机器人)。通过训练一个模型来执行这种转换,我们获得了一个非常适合追踪演示行为的特征表示。然后我们使用深度强化学习来优化行为,从而能够在目标环境中最佳地追踪转化演示。正如我们在实验中所阐述的那样,这种方法明显比以前那些学习固定特征空间(Stadie等人所著论文中有所提及),进行对抗模仿学习(Ho和Ermon于2016所著论文中有所提及),或直接追踪预先训练的视觉特征的方法更具有鲁棒性(Sermanet等人所著论文有所提及)。我们的转化方法是能够提供具有可解释性的奖励函数,并且在许多模仿和实际操纵任务中表现良好,其中就包括需要机器人模仿人类工具使用的任务。
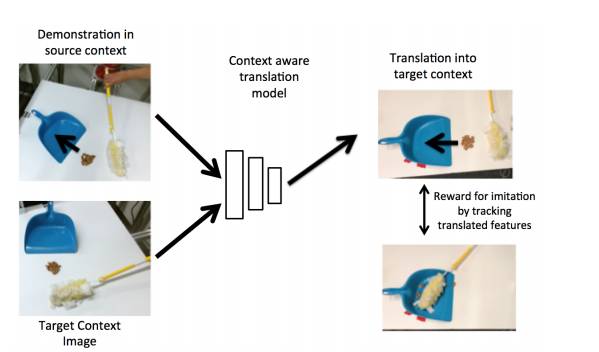
使用Context Aware translation模型进行的观察模仿
我们的实验旨在评估我们的环境转化模型是否能够实现模仿观察,以及现代代表性方法对这种模仿学习任务的表现如何。我们想要回答的具体问题是:
(1)我们的环境转化模型能否处理原始图像观察、视角变化,以及对象在环境之间的外观和位置的变化?
(2)与我们的方法相比,以前的模仿学习方法,在存在这种变化的情况下,表现如何?
(3)我们的方法对现实世界的图像有何好处,能否使现实世界的机器人系统学习操作技巧?
所有结果,包括说明性视频和进一步的实验细节,请访问https://sites.google.com/site/imitationfromobservation/。
模拟环境
为了与替代现有的模仿学习方法进行详细比较,我们使用MuJoCo模拟器(Todorov等人于2012年提出)设置了四个模拟操作任务。演示是使用参考标准奖励函数(ground truth reward function)和先前策略优化算法(prior policy optimization)(Schulman等人于2015提出)生成的。

图:四个模拟任务:到达(左上)、清扫(左下)、推(右上)和击打(右下)
这些任务如上图所示。第一个任务是要求机器人手臂在存在颜色和外观变化的情况下,到达由红盘指示的目标位置。第二个任务是在存在不同的牵引器物体的情况下,将白色圆筒推到红色的杯托上。第三项任务要求模拟机器人在视角不同的情况下将五颗灰球从灰尘中扫除。第四个任务是使用7个自由度的操纵器将一个白球击中一个红色的目标。
6.2环境转化的比较性评估

在新环境(中间)中执行一个到达任务(上)演示的示例图,最下面一行是转化的观察序列(底部)
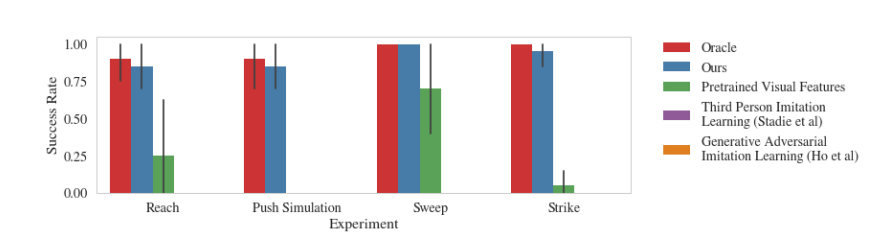
图5:与几种现有方法进行对比,到达、推、清扫和打击任务的比较。结果表明,我们的方法成功地学习了每个任务,而先前的方法无法执行到达、推送和打击任务,只有预先训练的视觉特征方法能够在清扫任务中得到较好的改善。第三人称模仿学习和生成对抗模仿学习在图表上的成功率均为0%。
我们的方法的比较评估结果如图5所示。性能是根据目标对象到测试目标的最终距离进行评估的。在到达任务中,这是指机器人的手与目标的距离,在推动任务中,这是指圆柱体与目标的距离,在清扫任务中,这对应球在簸箕中的平均距离,并且在击打任务中,这是指球离目标位置的最后距离。
如图5所示,结果表明,当从随机环境中提供演示时,我们的方法能够成功地学习每个任务。 值得注意的是,以前的方法在到达、推,或者打击任务方面,均没有成功,而且清扫任务也很费力。这表明在存在环境差异的情况下,模仿观察是一个非常有挑战性的问题。可在项目网站上查看定性结果视频:https://sites.google.com/site/imitationfromobservation/。
真实环境
•推

从视频中转化,将实际演示中的推动任务设置为模拟环境中的状态
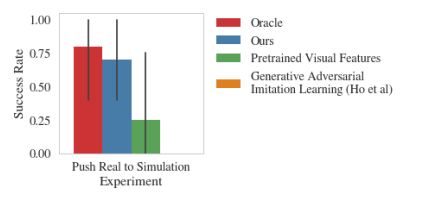
我们的方法与其他方法在真实世界中的演示与模拟世界中的策略学习的成功率对比


我们的方法的视频从Sawyer机器人的任意视角成功地将对象推送到目标上。左:人类提供的演示动作。右:机器人模仿学习
•清扫

上图:演示人员将杏仁扫进簸箕;下图:演示人员将杏仁倒进锅中

上图:使用我们的方法,机器人成功地将杏仁扫进簸箕
下图:使用我们的方法,机器人成功地将杏仁倒入烹饪盘中
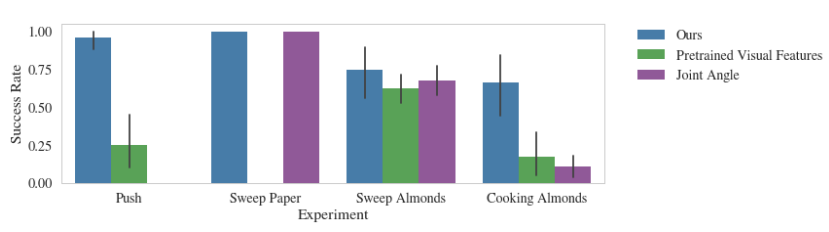
使用Sawyer机器人,我们的方法与现实世界任务的其他基准的成功率曲线对比。x轴是实验类型,y轴上显示不同方法的成功率。每个任务的成功度量有所不同。
我们研究了如何通过学习以在不同的环境之间转化示范观察序列,例如视角的差异以执行模仿观察。在将观察结果转化成目标环境之后,我们可以用强化学习来跟踪这些观察结果,让学习者重现观察到的行为。转化模型通过在训练集中观察到的不同环境之间进行转化,来进行训练,并将其泛化为学习者未知的环境。我们的实验表明,我们的方法可以用于执行各种操作技能,可以跟踪由人类演示者提供的工具使用的现实世界演示,并可用于现实世界中的机器人控制来做普通的家务。
虽然我们的方法在现实世界任务和模拟中的几个任务上表现良好,但它有一些限制。
首先,需要大量的示范来学习转化模型。对于每个任务,从头开始训练端到端的模型,可能在实践中效率低下,将我们的方法与先前工作中提出的更高层次的表达相结合,可能会导致训练更有效)。
第二,我们需要观察多个环境中的演示,以便学会如何在他们之间进行转化。实际上,可用环境的数量可能很少。在这种情况下,探索如何将多个任务组合成一个单一的模型是有价值的,其中不同的任务可能来自不同的环境。
最后,在今后的工作中探索明确处理领域转换将是令人激动的,以便直接从获得的人类演示者的视频中(例如网上视频)学习机器人技能。
了解更多论文详情,欢迎下载https://arxiv.org/pdf/1707.03374.pdf
 欢迎加入
欢迎加入

中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展

关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册




