当我有一个想法,并且这个想法很有意思,正好戳中我技能的盲区时,我便有一种强大的要将其实验一番的冲动。自从上周做一个「
前端中的后端
」的想法出炉后,这周我几乎寝食难安,随时随地都在想这件事,所以后来干脆撸起袖子开干,毕竟 Linus 大神告诫我们:

一旦开干,就有些搂不住了,每日正常工作开会带娃做饭之余,我几乎是 7-12-7 地将其一点点折腾出来,为了优化每一分时间,我甚至把哄小贝睡觉的时间从平均一个小时缩减到 25 分钟(诀窍是:唱摇篮曲的时候不断地假装打哈欠 —— 哈欠是会传染的)。
这种沉浸式的,集中精神全力以赴做一件事的感觉让我很快乐。在这个过程中,我第一次正式写 swift,就被迫在
Data
,
UsafeRawBufferPoiner
和
UnsafePointer
之间游蹿,不得不深入到 xcodebuild / swift package / xcframework 的细节去把一切东西自动化地在 CI 中完整地串联起来。当你真正深入去做一件事情的时候,你会发现,你的认知和实际情况相差很大 —— 比如:和我花在 swift package 上编译 static library 所花的巨大精力相比,在Rust 上构建 FFI 代码的过程简直就像闲庭信步,真是大大出乎了我的意料。
当我最终在 xcode 里测试通过 swift 和 rust 交互的整个流程,并且将其运行在 github action(使用 ubuntu 而不是 osx)做了一个相对完整的 CI 后,可想而知,我有多么兴奋:

更令人兴奋的是,在整个过程中,我学到了:
-
如何更好地定制化 prost build,让生成的 rust 的 protobuf 代码能够完美兼容不够严谨的 JSON 数据。
-
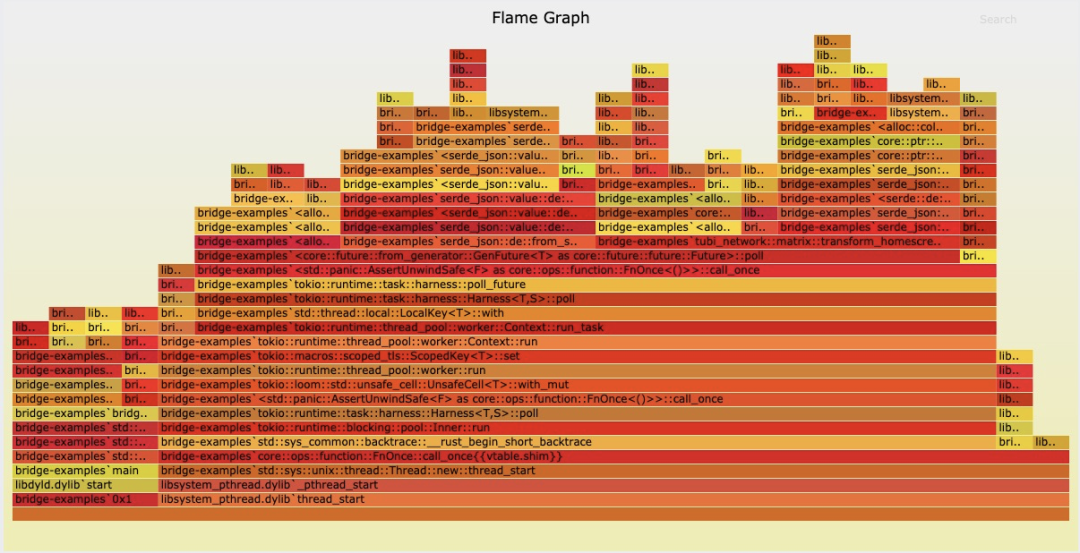
如何生成 rust 代码的 flamegraph,来更好地剖析代码中的低效的部分,然后结合 citerion 做 benchmark,来优化和提升代码运行的效率 —— 通过这个过程,我把一个不起眼的函数的效率提升了几乎一倍。
-
如何使用 Mozilla 提供的
ffi-support
,让跨语言调用时即便 Rust 侧
panic
,整个应用程序也不会崩溃。
-
如何更好地拆分 rust crate,让 unit test 变得更加简单。
-
如何更合理地使用
unsafe
。这是我第一个真正使用 unsafe Rust 的项目。嗯,不少心得。
-
如何使用 tokio/future runtime,使其可以把任务从调用的线程(swift 线程)转交给一组 Rust 的线程,并通过 callback 返回。这个其实很简单的工作,由于我一开始思路错了,导致走了很多弯路。
-
如何写包含 unit test,formatter,linter 的严肃的 swift 代码(嗯,我之前为了学语言写过 playground 代码和 swift UI,但没有正经写过包含单元测试的 Swift 代码)。
-
如何使用 swift protobuf 和在 swift 上做 performance benchmark。
-
如何使用 swift package manager,以及如何在 xcode 里链接静态库。
-
如何把静态库打包成 xcframework(很遗憾,arm 的静态库目前还无法成功打包进去)。
-
如何优雅地撰写复杂的 Makefile。
这些学到的内容也许值得写好几篇文章,就看我有没有时间,以及有没有心情了。在做这个 POC 的时候,我纠结过,是用一套公开的 API 来撰写一个开源的 POC 项目,还是特定对于 Tubi 的业务做一个更贴近生产环境的闭源 POC 项目。几经思考之后,我决定还是做成一个闭源 POC 项目,因为这样可以更好地通过已有的业务来更好地评估「前端中的后端」这件事情的难度以及意义。等一切坑都趟平后,我会在做 quenya client 端代码自动生成时,将这个流程及代码生成结合起来,做一套通过 OpenAPI spec 生成 Rust 代码,用于 FFI 的 protobuf 定义,以及对应的 swift/kotlin/typescript 的 binding 的代码。这将是另外一个故事了。
好,废话不多说。我们来具体讲讲实现过程中我关于架构,设计,以及具体编码过程中的一些思考。我写的项目名字叫 olorin:olorin 是 Gandalf 的另外一个名字,就像 Gandalf 联合起护戒小分队一样,我希望这个项目可以将 iOS/android/web/osx/windows 很好地联合起来。
架构和设计
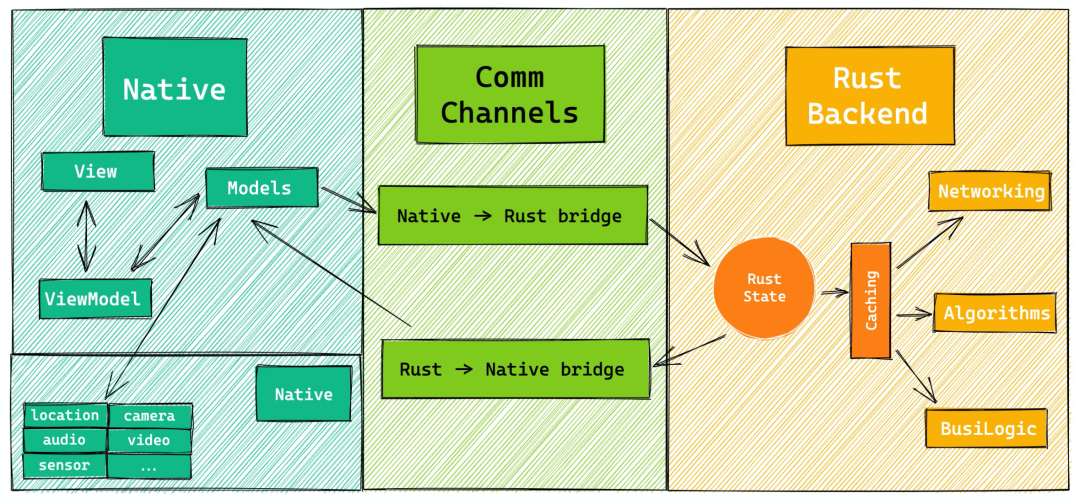
如果你看过上一篇文章,那么你还大概记得这样一个架构:
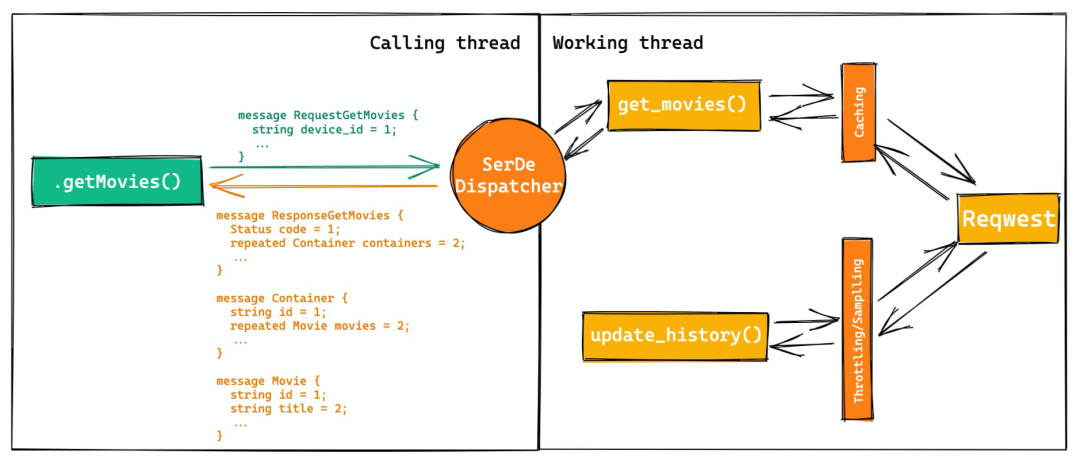
以及一个设想中的 API 的实现流程:
olorin 的实现几乎完全按照这个架构完成:
更为具体的流程见下图:
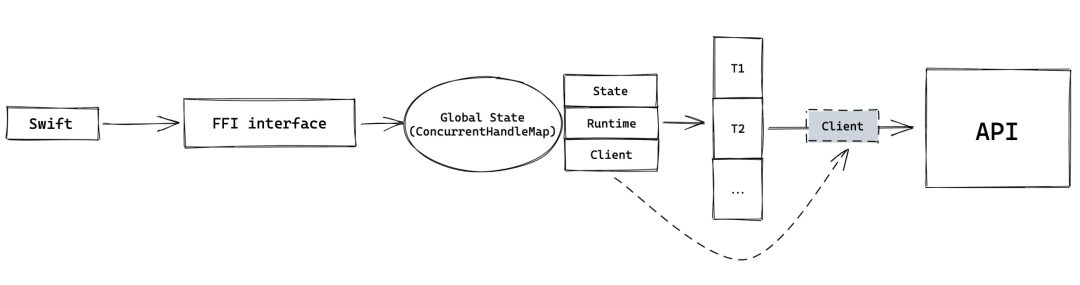
这里面,FFI 接口是至关重要的,它包括下面几个函数:
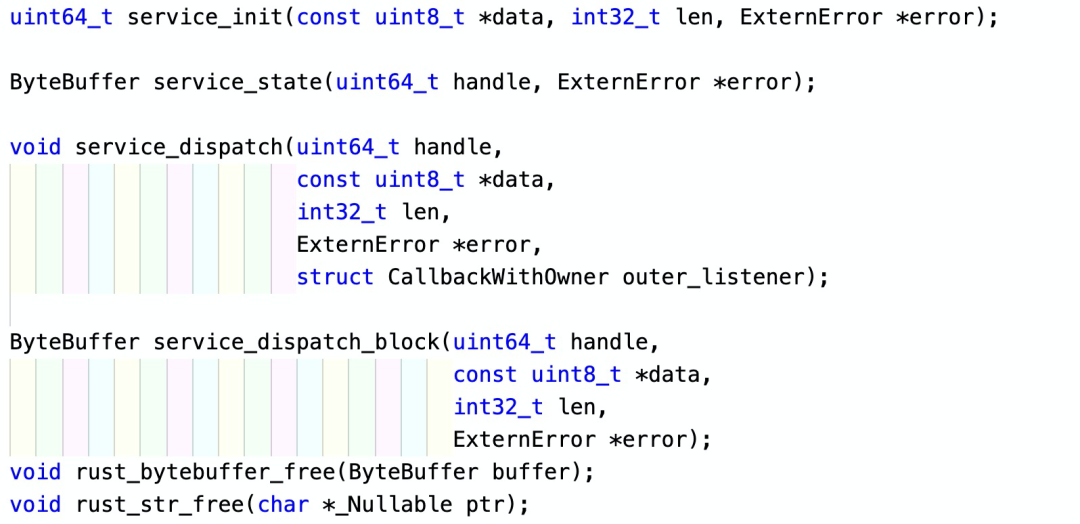
service_init
Rust 侧的初始化。Swift 代码提供一个用于初始化的 protobuf 字节流的指针和长度,Rust 侧创建对应的运行时,然后返回给 Swift 一个句柄,供以后的请求使用。这个请求一般是 app 启动时调用。Swift 可以提供一些基本的服务器请求参数,比如设备 ID,平台,用户 ID,要请求的服务器域名(prod/staging/dev)等信息。Rust 代码会利用设备 ID 和用户 ID(如果存在)在本地存储里查找是否有之前储存的用户状态,如果有,就加载到 State 中;如果没有,就创建新的 State。
service_dispatch/service_dispatch_block
这两个函数一个用于异步请求,一个用于同步请求。同步请求会阻塞 Swift 代码所在的线程;而异步请求则在不同的线程执行,完成之后调用 Swift 侧提供的 callback,提交结果。
请求的时候会提供之前获取的句柄,来找到对应的 Rust 运行时及状态。此外,还要提供请求所包含的 protobuf 字节流的指针和长度。因为所有的请求都走这一个接口,所以它被封装成为 protobuf 的一个 oneof message,如下所示(有删减):
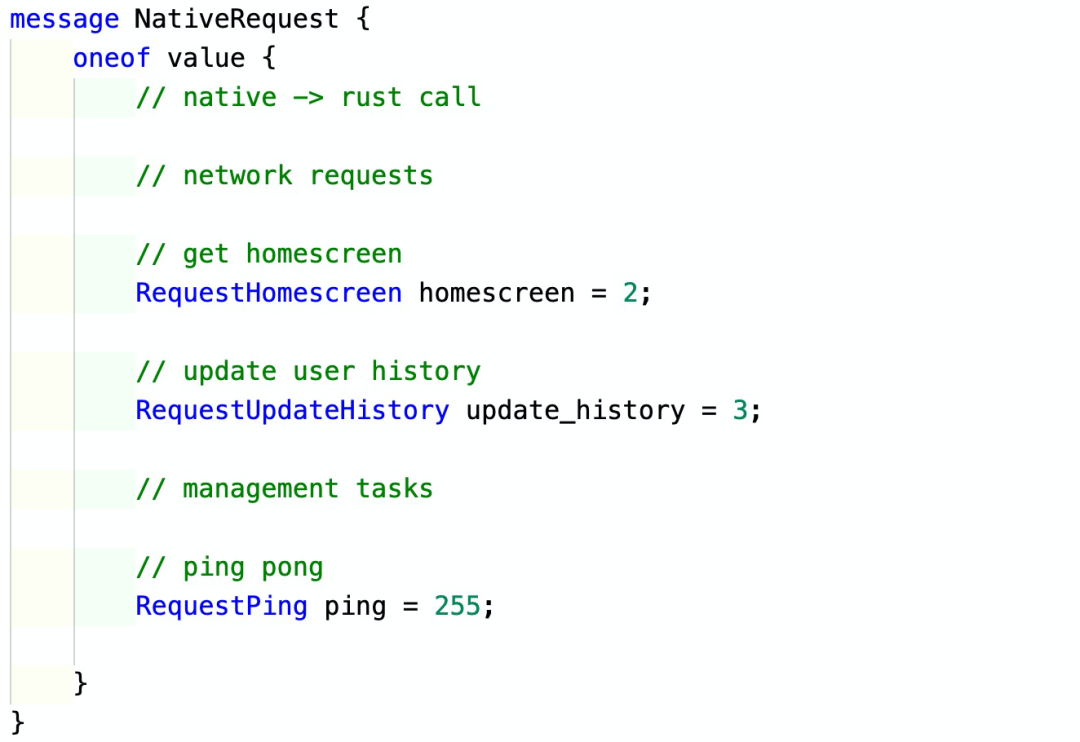
这种通过使用 oneof 来统一调用接口的方法,我是跟 Tendermint 的 ABCI 学的,非常好用。这样,我们在处理请求的时候,就可以根据其类型进行相应的 dispatch 了:
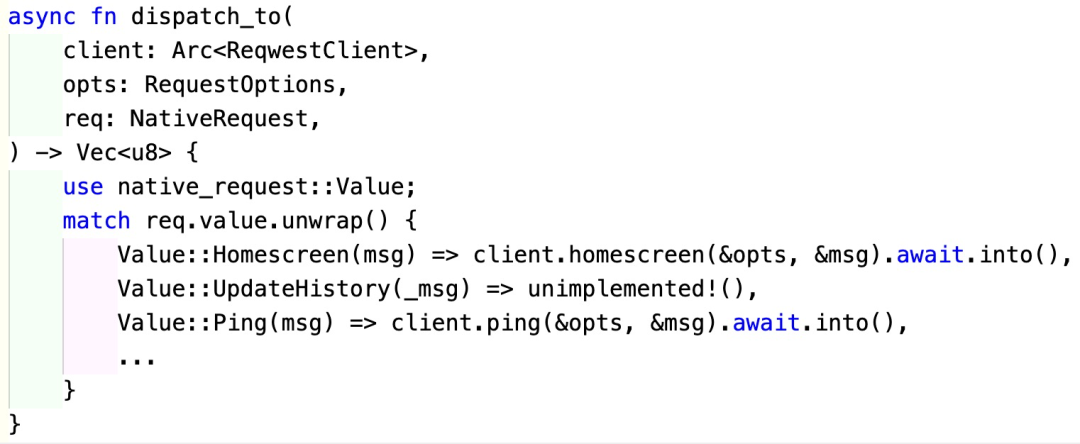
之所以提供一个同步和一个异步的接口,完全是为了客户端灵活而设置的。我自己没有做过生产环境的客户端,不知道哪种方式最适合客户端使用,所以干脆都提供了。好在对于 Tokio 来说,不过是
spawn
和
block_on
的区别而已。
我看了 Firefox sync 的部分代码,它只提供了同步调用的接口,所以整体上的设计比我这里所列的要简单。其实同步调用挺好的,不容易出错。
service_dispatch
接口具体在 Rust 中的实现并不困难。我们只需要了解如何做 Rust C FFI 即可。其实没什么神秘的,只需要注意三点:
一个完整流程
我们看一个从 Swift 到 Rust 的完整的 Ping/Pong 的代码,看看具体是怎么运作的。
首先在 Swift 侧,我们先初始化
service
结构。初始化的时候会调用 Rust 侧的初始化,生成上文我们所说的 runtime/state。

当我们在 Swift 里调用
service.ping
时,会先生成一个
AbiRequestPing
。这是我用 Apple 官方的 swift protobuf 库,基于我定义的 protobuf 生成的结构。由于 Swift import 一个库之后,所有的结构就无需 namespace 可以直接访问,所以我加了一个前缀(在 protobuf 定义:
option swift_prefix="Abi"
),一来好找,二来避免和其它数据结构冲突。
生成好
AbiRequestPing
后,需要将其进一步封装到
AbiNativeRequest
(见上文的 protobuf 定义),然后将其序列化成字节流。因为接下来要将这个字节流传给 Rust,所以我们需要将其转换成
UnsafeByte
。之后调用
service_dispatch_block
,同步返回结果 —— 为了简单起见,我们先不看异步的流程。这个结果是一个
ByteBuffer
结构。这是 Rust 传给 Swift 的指针,所以我们需要将其处理成一个
UnsafeRawBufferPointer
,封装成
Data
,再反序列化成
AbiResponsePong
。

这里面的核心是
rustCall
函数,它负责处理和内存安全相关的代码,我们先放下不表。
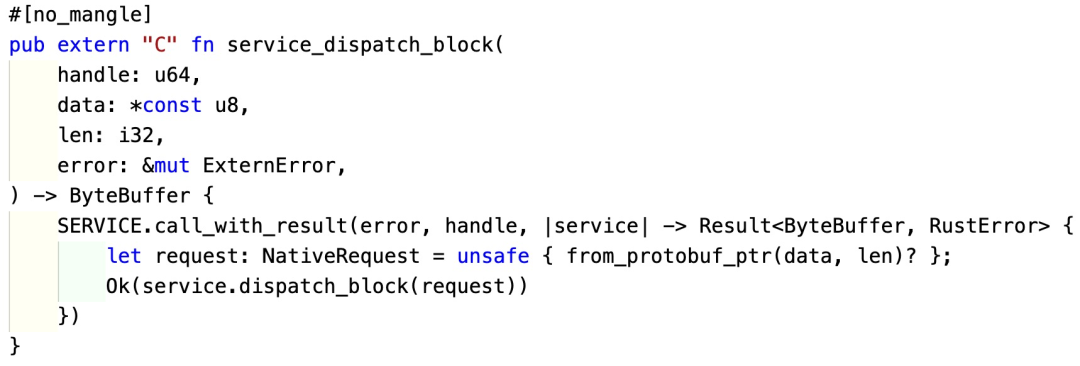
Rust 侧的
service_dispatch_block
,会把传入的指针转换成
Vec
,然后再反序列化成
NativeRequest
,就可以正常使用了。
内存管理
这时候,你可能会想到:数据在 Swift 和 Rust 间传来传去,究竟谁应该负责清理内存?
答案是:谁原本拥有的内存,谁负责释放。
Swift 侧是调用方,其传递给 Rust 的内存都在
withUnsafeBytes
闭包中,Rust 函数调用栈结束后,对该内存的引用消失,所以没有内存泄漏的危险,不需要手工处理。
Rust 是被调方,内存传递给 Swift 后,并不知道 Swift 会何时何地结束引用,所以 Rust 自己的所有权模型被略过(因为使用了
unsafe
),需要手工「释放」。释放的原则:
-
任何 Rust 传给 Swift 的 buffer,包括各种指针和字符串(字符串也是指针,但往往会被人忽略),都需要手工释放。
-
所谓的「释放」,只不过是把原来的指针再还给 Rust,并由 Rust 代码从指针中构建数据结构来重新「拥有」这块内存,这样 Rust 的所有权模型会接管并在合适的时候进行释放。
-
当「拥有」这块内存的 Rust 函数结束后,内存被回收。
这也就意味着 Rust 代码需要为自己传出去的内存提供回收的方法,供 Swift 使用。上文中提到的 FFI 接口,有两个函数:
rust_bytebuffer_free
和
rust_str_free
是负责做这个事情的。因为我们两个语言之间交互的主要接口就几个,而涉及的指针,只有以下两种,所以我们只需要相应地处理:
我们看刚才被忽略的
rustCall
代码:

如果你仔细看这段 Swift 代码,你可能会非常疑惑,这里没有调用
rust_str_free
的代码释放包含错误消息的字符串啊?
这里用了 Swift 的一个很有用的模式:使用参数标签来扩展已有的功能。Swift 有着非常强大的
extension
能力[2],辅以参数标签,能力爆表:

这段代码里我只需扩展
String
,为其
init
函数增加一个我自己的会「归还」Rust 指针并初始化字符串的实现即可。
说句题外话,初学 Swift 的时候,我觉得函数的参数标签是个非常鸡肋的功能,边写边吐槽它的繁琐(对于一个不太使用 xcode,大部分时候在 vscode 写代码的人来说,需要额外敲很多键),后来发现参数标签可以用作重载,卧槽,对我这个 Swift 小白来说,简直就是如获至宝。现在我已经离不开参数标签,并且开始吐槽:为啥 Rust 不支持参数标签(及重载)?
错误处理
跨语言的错误处理是一个很有意思的技术活。我们需要回答一个核心问题:如何把 Rust 代码的错误
Resut
,优雅地转化成 Swift 里的
Exception
?
一种思路是,把
Result
中的
E
,也就是
Error
,转化成一个 C 的结构体,包含错误码 (enum)和错误消息(char *),然后在 Swift 侧,利用这个信息重组并抛出异常。
另一种思路是,Rust 代码中返回的 protobuf 中包含错误信息,然后在 Swift 侧,查看这一信息并在需要的时候抛出异常。
因为我已经在使用 protobuf 来传递数据,所以我更加喜欢第二种思路的处理方式:简洁且没有额外的内存需要释放,然而,我使用的库
ffi-support
在其封装的 FFI 调用接口上,强行安置了
ExternalError
这个参数,使得我只能使用第一种思路。
如果你再看一眼
service_dispatch_block
的实现,会对下面这个闭包式的调用感到困惑:
call_with_result
为什么要设计成这样的形式?
这是因为其它语言调用 Rust 的时候,Rust 代码有可能
panic
(比如
unwrap()
失败),这将会直接导致调用的线程崩溃,从而可能让整个应用崩溃。从开发的角度,我们应该避免任何代码主动产生 panic,而是要把所有错误封装到
Result
中,但因为我们的代码会调用第三方库,我们无法保证所有第三方库都严格这样处理。对于 Swift 代码来说,Rust 代码所提供的库是一个黑盒,它理应保证不会出现任何会导致崩溃的行为。所以,我们需要一旦遇到
panic
时,能够进行栈展开(stack unwinding)。
我们知道,当函数正常调用结束后,其调用栈会返回到调用之前的状态 —— 你可以写一段简单的 C 代码,编译成 .o,然后用 objdump 来查看编译器自动插入的栈展开代码。然而,当一层层调用,栈不断累积的时候,如果内层的函数抛出了异常,而很外面的函数才捕获这个异常,那么,(支持异常处理的)编译器会插入回溯代码,一路把栈回溯到捕获异常的位置。在这个过程中,涉及到的上下文中所有的栈对象和用智能指针管理的堆对象都会并回收,不会有内存泄漏(对于 C++ 来说,非智能指针分配出的对象会泄漏)。对于 Rust 来说,栈展开是内存安全的,不会有任何内存泄漏。下图是我在 google image 里找到的关于栈展开不错的实例[3](我自己就懒得画了):
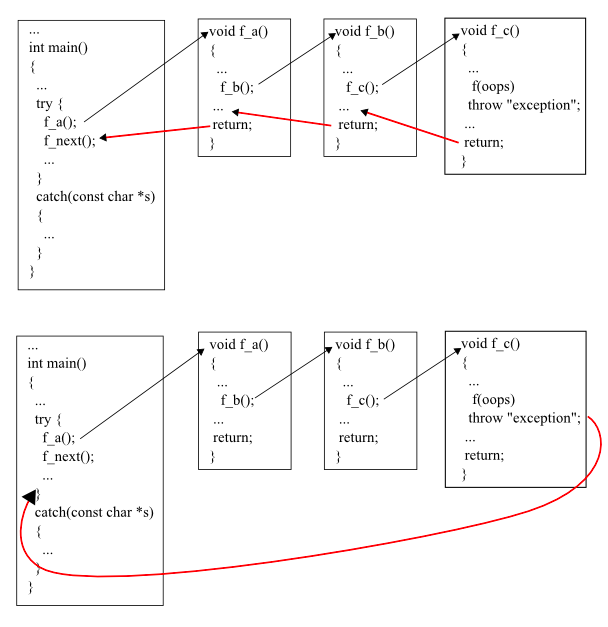
所以
call_with_result
就是为了保证在 FFI 这一层,所有调用的代码都有合适的栈展开代码来把任何潜在的 panic 捕获到并回溯堆栈,让 Swift(或者其他语言)的代码就像经历了一次异常。只要 Swift 代码捕获这个异常,那么程序依旧能够正常处理。
call_with_result
的具体实现如下,感兴趣的可以深入了解:

单元测试
我们讲了跨语言调用的解决方案,实现方法,以及内存管理和异常处理这些在实际开发中非常重要的部分。接下来,我们讲讲同样非常重要却往往被人忽视的部分:单元测试。
Rust FFI 接口之外的单元测试自不必说,该怎么搞就怎么搞,我们用单元测试(以及 property testing)保证纯粹的 Rust 代码在逻辑上的正确性。
Rust 提供给其它语言的 C FFI,需要妥善测试。这里有几个挑战:
-
我们要为测试环境提供一个贴近于 Swift 调用 Rust 的运行环境,比如:所有的测试使用同一个
service_init
产生的 handle。这个,可以通过
std::sync::Once
来完成。
-
对于
service_dispatch
,模拟 Swift callback 函数。
-
因为
service_dispatch
在其他线程中执行,因此测试结果出错需要能够被测试线程捕获。
2 和 3 的实现方法可以参考以下实例:

可以看到,
assert_eq!
在
on_result
回调中调用,而这个回调运行在 tokio 管理的若干个线程中的某个,因而有可能测试线程结束时,该线程还没有结束。所以这里我们需要不那么优雅地通过
sleep
阻塞一下测试线程。这里因为回调是一个 C 函数,无法做成 Rust 的闭包,因此,使用
channel
同步两个线程的思路行不通。如果大家有比
sleep
更好的方法,欢迎跟我探讨。我个人非常讨厌在 test 中显式地
sleep
来进行同步。
即便我们阻塞了足够多的时间,这里还有另一个问题:
assert_eq!
产生的
panic
无法被测试线程捕获到。所以我们在 FFI 代码的测试初始化时,需要添加
panic
处理的 hook。这里,我们让
panic
发生后,做完正常的处理流程,就立刻结束整个进程。这样,在 tokio 运行时某个线程中调用的
assert_eq!
被触发并产生错误时,测试能够正常退出并显示测试错误。
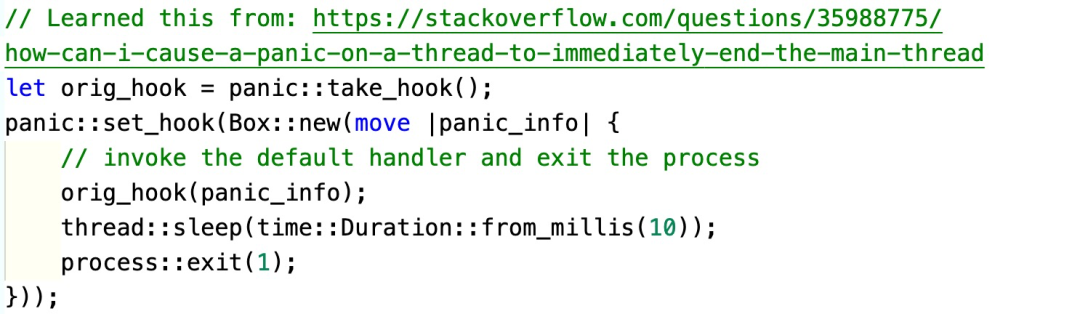
同样的,这个代码也只需执行一次,所以也应该将其包裹在
std::sync::Once
中。
Rust 开发的心得
我认为 Rust 开发的一大好处是你可以不断将代码拆分成新的 crate,让这些小的 crate 可以有自己完整的单元测试。这样非常符合 SRP(Single Responsibility Principle)。在这个 POC 里,我做的 Rust 侧代码:










