今天做题,其中一道是
请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什么样的场景。
一直想对这些大数据计算框架总结一下,只可惜太懒,一直拖着。今天就借这个机会好好学习一下。
一张表
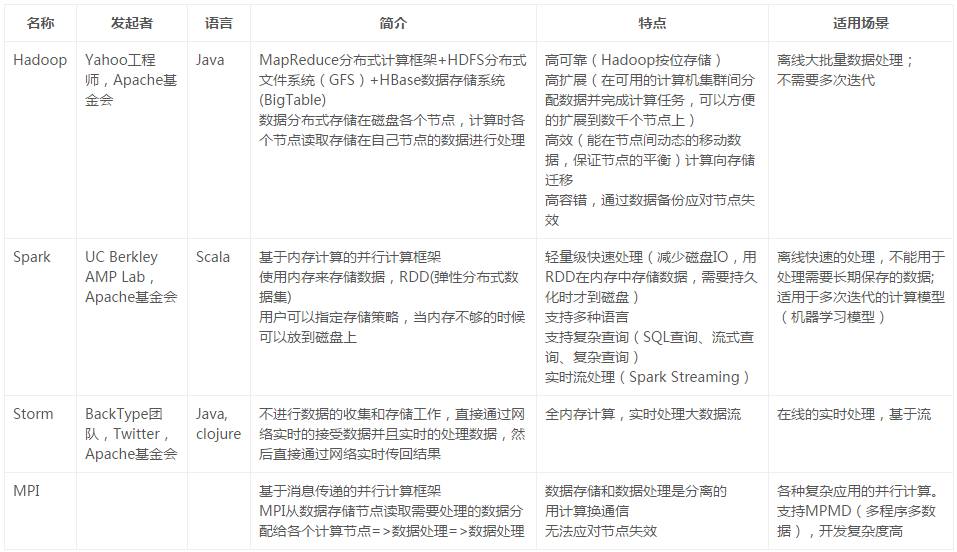
Hadoop就是解决了大数据的可靠存储和处理。现在的Hadoop主要包含两个框架
大规模存储系统HDFS:在由普通PC组成的集群上提供高可靠的文件存储,通过将块保存成多个副本的办法来解决服务器或硬盘坏掉的问题。以低功耗、高性能的方式储存数据,并且能优化大数据的种类和读取速度。
计算引擎YARN:可以承载任何数量的程序框架,原始的框架是MR,通过Mapper和Reduccer的抽象提供一个编程模型,可以在一个或上百个PC组成的不可靠集群上并发的、分布式的处理大量数据集,而把并发、分布式和故障恢复等计算细节隐藏起来。
-
抽象层次低,需要手工编写代码来完成,使用上难以上手。
-
只提供两个操作,Map和Reduce,表达力欠缺。
-
一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的。
-
处理逻辑隐藏在代码细节中,没有整体逻辑
-
中间结果也放在HDFS文件系统中
-
ReduceTask需要等待所有MapTask都完成后才可以开始
-
时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
-
对于迭代式数据处理性能比较差
Apache Spark是一个新兴的大数据处理的引擎,主要特点是提供了一个集群的分布式内存抽象,以支持需要工作集的应用。
这个抽象就是RDD(Resilient Distributed
Dataset),RDD就是一个不可变的带分区的记录集合,RDD也是Spark中的编程模型。Spark提供了RDD上的两类操作,转换和动作。转换是用来定义一个新的RDD,包括map,
flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros,
sortByKey, mapValues等,动作是返回一个结果,包括collect, reduce, count, save, lookupKey。
在Spark中,所有RDD的转换都是是惰性求值的。RDD的转换操作会生成新的RDD,新的RDD的数据依赖于原来的RDD的数据,每个RDD又包含多个分区。那么一段程序实际上就构造了一个由相互依赖的多个RDD组成的有向无环图(DAG)。并通过在RDD上执行动作将这个有向无环图作为一个Job提交给Spark执行。
Spark对于有向无环图Job进行调度,确定阶段(Stage),分区(Partition),流水线(Pipeline),任务(Task)和缓存(Cache),进行优化,并在Spark集群上运行Job。RDD之间的依赖分为宽依赖(依赖多个分区)和窄依赖(只依赖一个分区),在确定阶段时,需要根据宽依赖划分阶段。根据分区划分任务。
Spark支持故障恢复的方式也不同,提供两种方式,Linage,通过数据的血缘关系,再执行一遍前面的处理,Checkpoint,将数据集存储到持久存储中。
Spark为迭代式数据处理提供更好的支持。每次迭代的数据可以保存在内存中,而不是写入文件。
-
抽象层次低,需要手工编写代码来完成,使用上难以上手。
=>基于RDD的抽象,实数据处理逻辑的代码非常简短。
-
只提供两个操作,Map和Reduce,表达力欠缺。
=>提供很多转换和动作,很多基本操作如Join,GroupBy已经在RDD转换和动作中实现。
-
一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的。
=>一个Job可以包含RDD的多个转换操作,在调度时可以生成多个阶段(Stage),而且如果多个map操作的RDD的分区不变,是可以放在同一个Task中进行。
-
处理逻辑隐藏在代码细节中,没有整体逻辑
=>在Scala中,通过匿名函数和高阶函数,RDD的转换支持流式API,可以提供处理逻辑的整体视图。代码不包含具体操作的实现细节,逻辑更清晰。
-
中间结果也放在HDFS文件系统中
=>中间结果放在内存中,内存放不下了会写入本地磁盘,而不是HDFS。
-
ReduceTask需要等待所有MapTask都完成后才可以开始
=>
分区相同的转换构成流水线放在一个Task中运行,分区不同的转换需要Shuffle,被划分到不同的Stage中,需要等待前面的Stage完成后才可以开始。
-
时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
=>通过将流拆成小的batch提供Discretized Stream处理流数据。
-
对于迭代式数据处理性能比较差
=>通过在内存中缓存数据,提高迭代式计算的性能。
End
为了让大家能有更多的好文章可以阅读,36大数据联合华章图书共同推出「祈文奖励计划」,该计划将奖励每个月对大数据行业贡献(翻译or投稿)最多的用户中选出最前面的10名小伙伴,统一送出华章图书邮递最新计算机图书一本。投稿邮箱:[email protected]
点击查看:你投稿,我送书,「祈文奖励计划」活动详情>>>
如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?
排名前50的开源Web爬虫用于数据挖掘
33款可用来抓数据的开源爬虫软件工具
在中国我们如何收集数据?全球数据收集大教程
PPT:数据可视化,到底该用什么软件来展示数据?
干货|电信运营商数据价值跨行业运营的现状与思考
大数据分析的集中化之路 建设银行大数据应用实践PPT
【实战PPT】看工商银行如何利用大数据洞察客户心声?










