
resolvewang,Python中文社区专栏作者
Python和Go爱好者。具有较为丰富的爬虫和反爬虫经验,对web编程略知一二,对基础架构比较感兴趣
前言
本系列文章计划分三个章节进行讲述,分别是理论篇、基础篇和实战篇。理论篇主要为构建分布式爬虫而储备的理论知识,基础篇会基于理论篇的知识写一个简易的分布式爬虫,实战篇则会以微博为例,教大家做一个比较完整且足够健壮的分布式微博爬虫。通过这三篇文章,希望大家能掌握如何构建一个分布式爬虫的方法;能举一反三,将celery用于除爬虫外的其它场景。目前基本上的博客都是教大家使用scrapyd或者scrapy-redis构建分布式爬虫,本系列文章会从另外一个角度讲述如何用requests+celery构建一个健壮的、可伸缩并且可扩展的分布式爬虫。
本系列文章属于爬虫进阶文章,期望受众是具有一定Python基础知识和编程能力、有爬虫经验并且希望提升自己的同学。小白要是感兴趣,也可以看看,看不懂的话,可以等有了一定基础和经验后回过头来再看。
另外一点说明,本系列文章不是旨在构建一个分布式爬虫框架或者分布式任务调度框架,而是利用现有的分布式任务调度工具来实现分布式爬虫,所以请轻喷。
分布式爬虫概览
何谓分布式爬虫?
通俗的讲,分布式爬虫就是多台机器多个 spider 对多个 url 的同时处理问题,分布式的方式可以极大提高程序的抓取效率。
构建分布式爬虫通畅需要考虑的问题
(1)如何能保证多台机器同时抓取同一个URL?
(2)如果某个节点挂掉,会不会影响其它节点,任务如何继续?
(3)既然是分布式,如何保证架构的可伸缩性和可扩展性?不同优先级的抓取任务如何进行资源分配和调度?
基于上述问题,我选择使用celery作为分布式任务调度工具,是分布式爬虫中任务和资源调度的核心模块。它会把所有任务都通过消息队列发送给各个分布式节点进行执行,所以可以很好的保证url不会被重复抓取;它在检测到worker挂掉的情况下,会尝试向其他的worker重新发送这个任务信息,这样第二个问题也可以得到解决;celery自带任务路由,我们可以根据实际情况在不同的节点上运行不同的抓取任务(在实战篇我会讲到)。本文主要就是带大家了解一下celery的方方面面(有celery相关经验的同学和大牛可以直接跳过了)
Celery知识储备
celery基础讲解
按celery官网的介绍来说
Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。它是一个专注于实时处理的任务队列,同时也支持任务调度。
下面几个关于celery的核心知识点
broker:翻译过来叫做中间人。它是一个消息传输的中间件,可以理解为一个邮箱。每当应用程序调用celery的异步任务的时候,会向broker传递消息,而后celery的worker将会取到消息,执行相应程序。这其实就是消费者和生产者之间的桥梁。
backend: 通常程序发送的消息,发完就完了,可能都不知道对方时候接受了。为此,celery实现了一个backend,用于存储这些消息以及celery执行的一些消息和结果。
worker: Celery类的实例,作用就是执行各种任务。注意在celery3.1.25后windows是不支持celery worker的!
producer: 发送任务,将其传递给broker
beat: celery实现的定时任务。可以将其理解为一个producer,因为它也是通过网络调用定时将任务发送给worker执行。注意在windows上celery是不支持定时任务的!
下面是关于celery的架构示意图,结合上面文字的话应该会更好理解
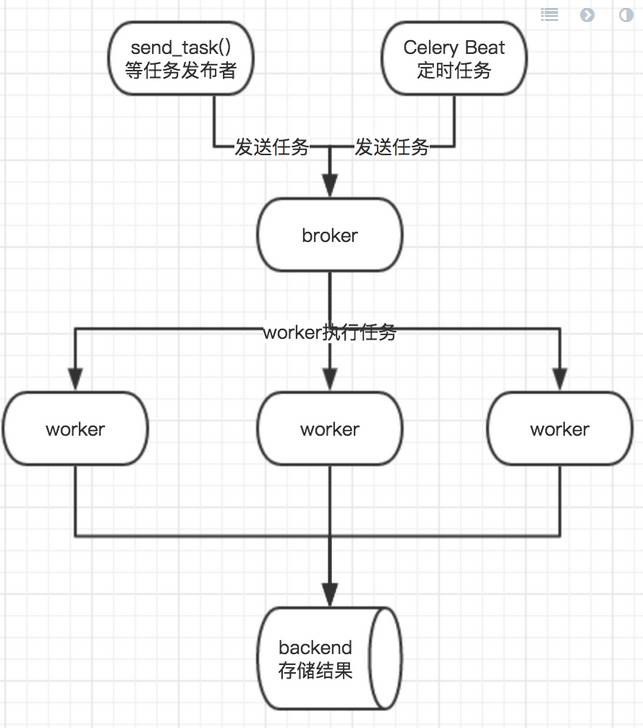
由于celery只是任务队列,而不是真正意义上的消息队列,它自身不具有存储数据的功能,所以broker和backend需要通过第三方工具来存储信息,celery官方推荐的是 RabbitMQ和Redis,另外mongodb等也可以作为broker或者backend,可能不会很稳定,我们这里选择Redis作为broker兼backend。
关于redis的安装和配置可以查看这里
实际例子
先安装celery
pip install celery
我们以官网给出的例子来做说明,并对其进行扩展。首先在项目根目录下,这里我新建一个项目叫做celerystudy,然后切换到该项目目录下,新建文件tasks.py,然后在其中输入下面代码
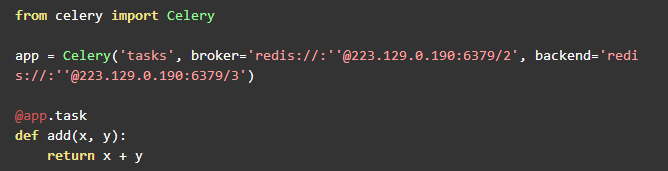
这里我详细讲一下代码:我们先通过app=Celery()来实例化一个celery对象,在这个过程中,我们指定了它的broker,是redis的db 2,也指定了它的backend,是redis的db3, broker和backend的连接形式大概是这样
redis://:password@hostname:port/db_number
然后定义了一个add函数,重点是@app.task,它的作用在我看来就是将add()
注册为一个类似服务的东西,本来只能通过本地调用的函数被它装饰后,就可以通过网络来调用。这个tasks.py中的app就是一个worker。它可以有很多任务,比如这里的任务函数add。我们再通过在命令行切换到项目根目录,执行
celery -A tasks worker -l info
启动成功后就是下图所示的样子
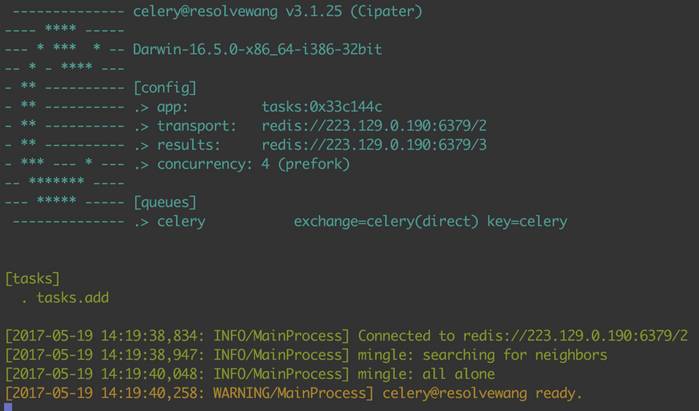
这里我说一下各个参数的意思,-A指定的是app(即Celery实例)所在的文件模块,我们的app是放在tasks.py中,所以这里是 tasks;worker表示当前以worker的方式运行,难道还有别的方式?对的,比如运行定时任务就不用指定worker这个关键字; -l info表示该worker节点的日志等级是info,更多关于启动worker的参数(比如-c、-Q等常用的)请使用
celery worker --help
进行查看
将worker启动起来后,我们就可以通过网络来调用add函数了。我们在后面的分布式爬虫构建中也是采用这种方式分发和消费url的。在命令行先切换到项目根目录,然后打开python交互端
from tasks import add
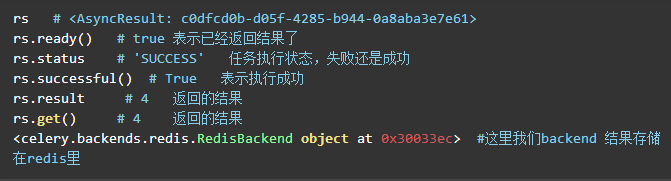
rs = add.delay(2, 2)
这里的add.delay就是通过网络调用将任务发送给add所在的worker执行,这个时候我们可以在worker的界面看到接收的任务和计算的结果。

这里是异步调用,如果我们需要返回的结果,那么要等rs的ready状态true才行。这里add看不出效果,不过试想一下,如果我们是调用的比较占时间的io任务,那么异步任务就比较有价值了
上面讲的是从Python交互终端中调用add函数,如果我们要从另外一个py文件调用呢?除了通过import然后add.delay()这种方式,我们还可以通过send_task()这种方式,我们在项目根目录另外新建一个py文件叫做 excute_tasks.py,在其中写下如下的代码
from tasks import add
if __name__ == '__main__':
add.delay(5, 10)
这时候可以在celery的worker界面看到执行的结果

此外,我们还可以通过send_task()来调用,将excute_tasks.py改成这样

这种方式也是可以的。send_task()还可能接收到为注册(即通过@app.task装饰)的任务,这个时候worker会忽略这个消息

定时任务
上面部分讲了怎么启动worker和调用worker的相关函数,这里再讲一下celery的定时任务。
爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能。在上述基础上,我们将tasks.py文件改成如下内容

然后先通过ctrl+c停掉前一个worker,因为我们代码改了,需要重启worker才会生效。我们再次以celery -A tasks worker -l info这个命令开启worker。
这个时候我们只是开启了worker,如果要让worker执行任务,那么还需要通过beat给它定时发送,我们再开一个命令行,切换到项目根目录,通过
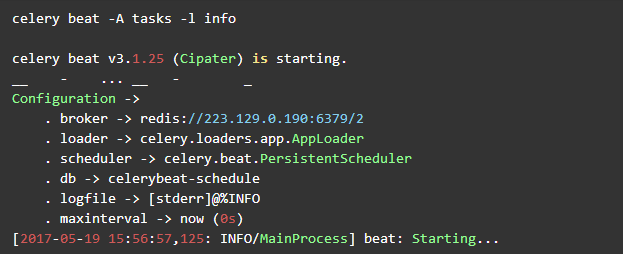
这样就表示定时任务已经开始运行了。
眼尖的同学可能看到我这里celery的版本是3.1.25,这是因为celery支持的windows最高版本是3.1.25。由于我的分布式微博爬虫的worker也同时部署在了windows上,所以我选择了使用 3.1.25。如果全是linux系统,建议使用celery4。
此外,还有一点需要注意,在celery4后,定时任务(通过schedule调度的会这样,通过crontab调度的会马上执行)会在当前时间再过定时间隔执行第一次任务,比如我这里设置的是60秒的间隔,那么第一次执行add会在我们通过celery beat -A tasks -l info启动定时任务后60秒才执行;celery3.1.25则会马上执行该任务。
关于定时任务更详细的请看官方文档celery定时任务(http://docs.celeryproject.org/en/master/userguide/periodic-tasks.html)
至此,我们把构建一个分布式爬虫的理论知识都讲了一遍,主要就是对于celery的了解和使用,这里并未涉及到celery的一些高级特性,实战篇可能会讲解一些我自己使用的特性。
下一篇我将介绍如何使用celery写一个简单的分布式爬虫,希望大家能有所收获。
此外,我写了一个分布式的微博爬虫(https://github.com/ResolveWang/WeiboSpider),主要就是利用celery做的分布式实战篇我也将会以该项目其中一个模块进行讲解,有兴趣的可以点击看看,也欢迎有需求的朋友试用。
长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
— 人生苦短,我用Python —
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS
本文为作者原创作品,未经作者授权同意禁止转载
点击阅读原文可进入Python圈子获取下方资料:
人工智能与深度学习国内外最新资料、Python web开发、数据分析、网络爬虫学习资料大全、《Python爬虫入门》、《Python简易爬虫实战案例》、《TensorFlow从入门到案例》课件,《Python数据科学入门》案例源代码及各类Python资料、技术源码、行业信息精选定期分享。










