正文
本文来自英国伦敦大学学院博士张伟楠在携程技术中心主办的深度学习Meetup中的主题演讲,介绍了深度学习在在Multi-field Categorical(多字段分类)数据集上的应用,涉及FM和FNN等算法。

本次分享主要讲的是深度学习在Multi-field Categorical 这类数据集上的应用,这种类型的数据主要呈现以下特征:有多个域,每个域上的数据以ID格式呈现。本课题就是在信息检索这一大类下的应用,它的应用主要体现在:网络搜索、推荐系统、广告展示这些领域。深度学习对连续数据和序列数据(比如:图片像素、语音、自然语言等)有比较好的效果且目前已经有了比较成熟的应用,如:图像识别、语音识别等。
而现实世界中又有很多现象需要多字段的分类数据来描述,那如果用深度学习来处理多字段的分类数据,效果又会是怎样呢?本文通过用户在线广告点击行为预测的应用实例来向大家展示深度学习在多字段分类数据的应用效果。
文章将详细介绍了FM和FNN算法在处理多值分类数据方面的优势,并把这两种算法与神经网络在特征变量处理方面的差异做了对比,最后通过一个用户在线广告点击行为预测的实例比较了LR、FM、FNN、CCPM、PNN-I等不同算法的实际预测效果。
深度学习目前的应用现状
深度学习目前比较成熟的应用主要集中在:机器视觉、语音识别、自然语言处理这些课题上,这些应用领域的共同特点是它们的数据集是连续的。比如:图形识别中每个图层与它之后的图层局部都有比较紧密的联系;语音信息前后也有比较强的相关关系;在自然语言处理中每个WORD虽然是离散的,但是其前后的数据也是强相关的。对于这种类型的数据,人可以轻易理解这些数据,但是一般的机器学习算法处理这种数据却是非常困难的,而深度学习却可以很好的从底层逐层学习出高层的模式,这就是深度学习的优势。
而今天我们要了解的数据 Multi-field Categorical Data与上述这些连续或是序列数据是有区别的,Multi-field Categorical Data会有多种不同的字段,比如:[Weekday=Wednesday, Gender=Male, City=London,…],那这样我们就比较难识别这些特征之间的关系。给大家举例一个直观的场景:比如现在有一个凤凰网站,网站上面有一个迪斯尼广告,那我们现在想知道用户进入这个网站之后会不会有兴趣点击这个广告,类似这种用户点击率预测在信息检索领域就是一个非常核心的问题。
那一般普遍的做法就是通过不同的域来描述这个事件然后预测用户的点击行为,而这个域可以有很多,比如:
• Date: 20160320• Hour: 14• Weekday: 7• IP: 119.163.222.*
• Region: England
• City: London
• Country: UK
• Ad Exchange: Google
• Domain: yahoo.co.uk• URL: http://www.yahoo.co.uk/abc/xyz.html• OS: Windows
• Browser: Chrome
• Ad size: 300*250• Ad ID: a1890
• User tags: Sports, Electronics
可能我们还会有这些用户的身份信息,比如该用户是学生等,那我们可以通过这些多维度的取值来描述这个事件然后来预测用户的点击行为。回到刚才的那个场景,那么什么样的用户会点击这个广告呢?我们可能猜想:目前在上海的年轻的用户可能会有需求,如果今天是周五,看到这个广告,可能会点击这个广告为周末做活动参考。那可能的特征会是:[Weekday=Friday, occupation=Student, City=Shanghai],当这些特征同时出现时,我们认为这个用户点击这个迪斯尼广告的概率会比较大。
这种场景在WEB Search、广告展示、推荐系统领域会经常遇到,比如Google和百度在做广告点击率预测时,他们人工地把这种分类数据做四阶或是五阶的结合特征,最终在一个超级大的数据集上去学习特征,而这个过程需要耗费大量人力去做特征处理,本次要讲的就是应用深度学习去直接学习这类数据特征。
传统的做法是应用One-Hot Binary的编码方式去处理这类数据,例如现在有三个域的数据X=[Weekday=Wednesday, Gender=Male, City=Shanghai],其中 Weekday有7个取值,我们就把它编译为7维的二进制向量,其中只有Wednesday是1,其他都是0,因为它只有一个特征值;Gender有两维,其中一维是1;如果有一万个城市的话,那City就有一万维,只有上海这个取值是1,其他是0。

那最终就会得到一个高维稀疏向量。但是这个数据集不能直接用神经网络训练:如果直接用One-Hot Binary进行编码,那输入特征至少有一百万,第一层至少需要500个节点,那么第一层我们就需要训练5亿个参数,那就需要20亿或是50亿的数据集,而要获得如此大的数据集基本上是很困难的事情。
FM、FNN以及PNN模型
因为上述原因,我们需要将非常大的特征向量嵌入到低维向量空间中来减小模型复杂度,而FM(Factorisation machine)无疑是被业内公认为最有效的embedding model:

第一部分仍然为Logistic Regression,第二部分是通过两两向量之间的点积来判断特征向量之间和目标变量之间的关系。比如上述的迪斯尼广告,occupation=Student和City=Shanghai这两个向量之间的角度应该小于90,它们之间的点积应该大于0,说明和迪斯尼广告的点击率是正相关的。这种算法在推荐系统领域应用比较广泛。
那我们就基于这个模型来考虑神经网络模型,其实这个模型本质上就是一个三层网络:

它在第二层对向量做了乘积处理(比如上图蓝色节点直接为两个向量乘积,其连接边上没有参数需要学习),每个field都只会被映射到一个 low-dimensional vector,field和field之间没有相互影响,那么第一层就被大量降维,之后就可以在此基础上应用神经网络模型。
我们用FM算法对底层field进行embeddding,在此基础上面建模就是FNN(Factorisation-machine supported Neural Networks)模型:

模型底层先用FM对经过one-hot binary编码的输入数据进行embedding,把稀疏的二进制特征向量映射到 dense real 层,之后再把dense real 层作为输入变量进行建模,这种做法成功避免了高维二进制输入数据的计算复杂度。
那我们把这些模型应用到iPinYou数据集上,模型效果如下所示:

那我们可以看出FNN的效果优于LR和 FM 模型。我们进一步考虑FNN与一般的神经网络的区别是什么?大部分的神经网络模型对向量之间的处理都是采用加法操作,而FM 则是通过向量之间的乘法来衡量两者之间的关系。我们知道乘法关系其实相当于逻辑“且”的关系,拿上述例子来说,只有特征是学生而且在上海的人才有更大的概率去点击迪斯尼广告。但是加法仅相当于逻辑中“或”的关系,显然“且”比“或”更能严格区分目标变量。
所以我们接下来的工作就是对乘法关系建模。可以对两个向量做内积和外积的乘法操作:

可以看出对外积操作得到矩阵而言,如果该矩阵只有对角线上有值,就变成了内积操作的结果,所以内积操作可以看作是外积操作的一种特殊情况。通过这种方式,我们就可以衡量连个不同域之间的关系。
在此基础之上我们搭建的神经网络如下所示:
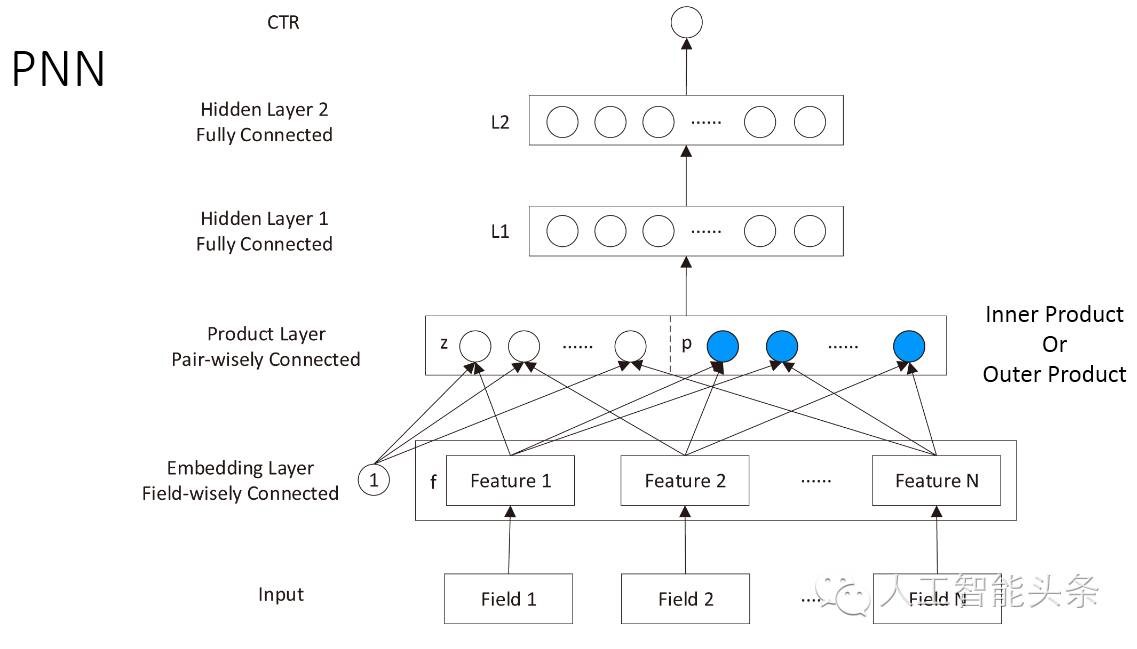
首先对输入数据进行embedding处理,得到一个low-dimensional vector层,对该层的任意两个feature进行内积或是外积处理就得到上图的蓝色节点,另外一种处理方式是把这些Feature直接和1相乘复制到上一层的Z中,然后把Z和P接在一起就可以作为神经网络的输入层,在此基础上我们就可以应用神经网络去模型了。
那么对特征做内积或是外积处理就会产生一个复杂度的问题:假设有60个域,那么把这些feature做内积处理,就会产生将近1000多个元素的矩阵,如此就会产生一个很大的weight矩阵,那我们需要学习的参数就很多,那我们的数据集可能就满足不了这个要求。那接下来的做法就是:由于weight矩阵是个对称阵,我们可以用factorization来处理这个对称阵,把它转换为一个小矩阵乘以这个小矩阵的转置,这样就会大大减少我们所需要训练的参数:

模型效果评估
接下来我们可以看一下模型在两个不同数据集上面的应用效果:
第一个数据集Criteo Terabyte Dataset:这个数据集有13个数值变量,26个类别变量,我们节选了8天将近300GB的数据量,前7天作为训练集,由于这个数据集正样本过少,我们对负样本做了欠抽样的处理。
第二个数据集iPinYou Dataset:共有24个类别变量,我们截取了连续10天的数据量。
我们应用的比较算法有:LR (Logistic regression)、FM(Factorisation machine)、FNN(Factorisation machine supported neural network)、CCPM(Convolutional click prediction model)、PNN-I(Inner product neural network)、PNN-II(Outer product neural network)、PNN-III(Inner&outer product ensembled neural network)
评估模型我们主要看的是以下几个指标:
Area under ROC curve (AUC):非常关键的指标
Log loss:该值越小,说明点击率预估的准确度越高

Root mean squared error (RMSE):值越大模型效果越好,作为参考

Relative Information Gain (RIG):值越大模型效果越好

最终各个模型的效果如下:

我们主要看的是AUC这个指标,业内一般模型提升2个百分点就会带来巨大收益,可以看到从LR到PNN,模型效果提升了近5个百分点,由此可见FM、FNN、PNN这几类模型效果比LR显著要好。
其他的实验结果,比如dropout,业内认为0.5是比较好的值,我们PNN-II模型的实验结果也证明了这一点:

我们还测试了最佳的隐层层数,隐层层数并不是越多越好,层数过多的模型会出现过拟合效应,这个隐层数是跟数据集大小相关,一般而言数据集越大所需要的隐层就越多,我们这里模型显示的最佳隐层是3层:
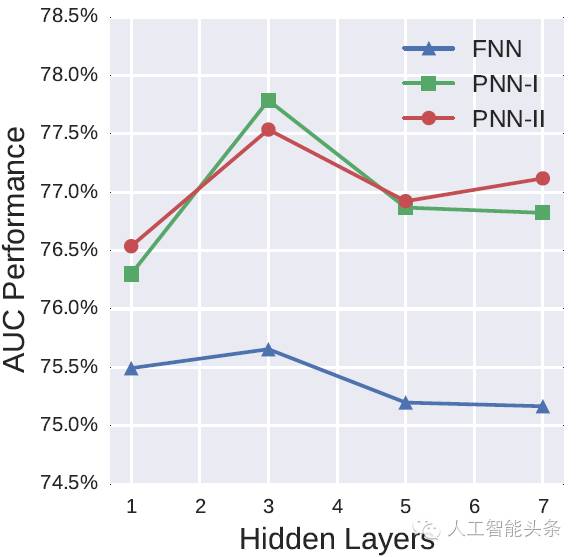
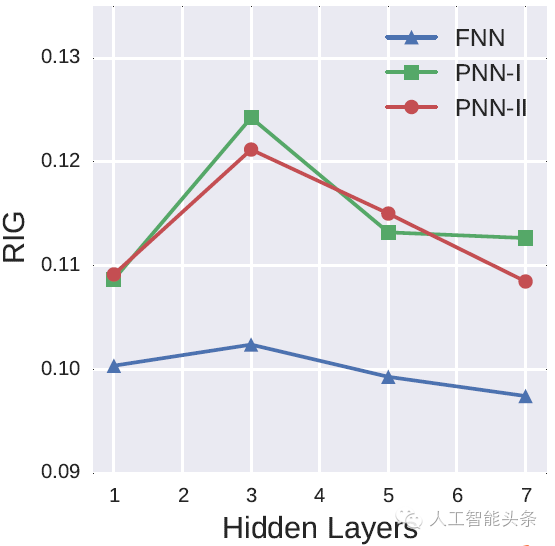
我们同时在小数据集iPinYou Dataset上看了一下各模型的稳健性,发现PNN-1和PNN-2模型效果超过其他模型一直处在稳步上升的过程:

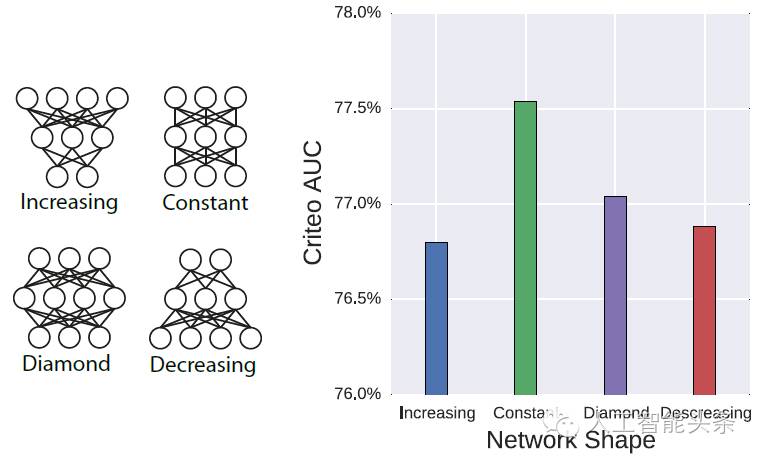
之后我们还学习了神经网络不同层级节点数目的分布,一下有四种不同的层级节点分布形态,结果发现constant 和 diamond 这两种形态的表现效果比较好,increasing形态效果最差,说明我们不应该在第一层就过度压缩特征向量:
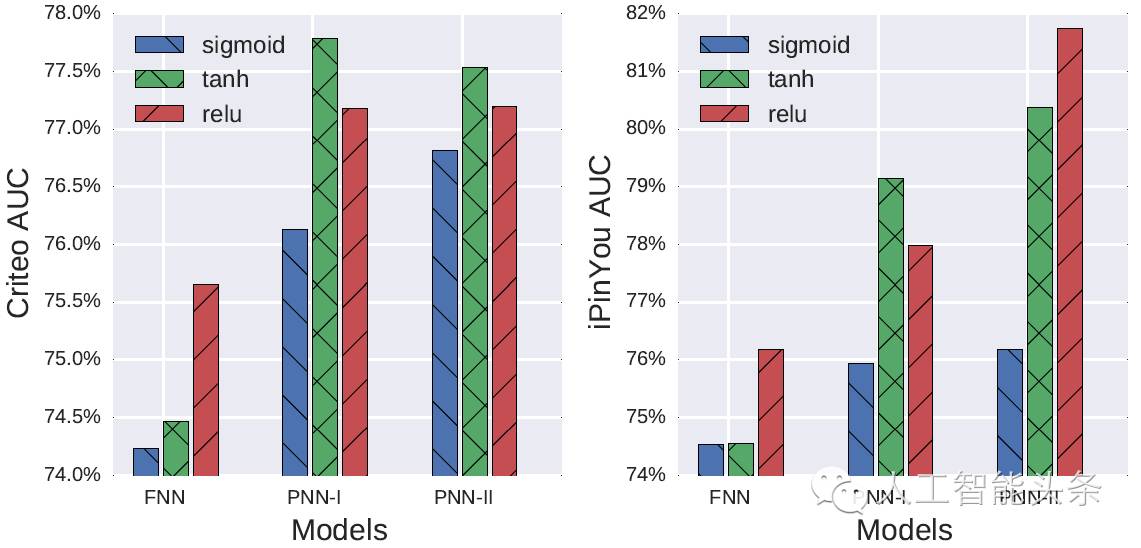
我们还对比了不同隐层节点的Activation Functions的效果,结果发现tanh 和 relu明显优于sigmoid:
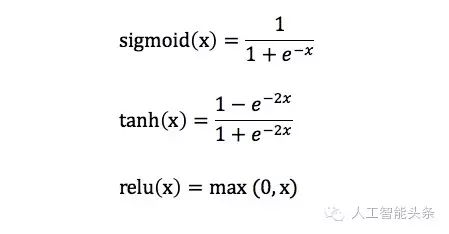
小结
深度学习在多字段分类数据集上也能取得显著的应用效果;
通过内积和外积操作找到特征之间的相关关系;
在广告点击率的预测中,PNN效果优于其他模型。
PPT下载:[用户在线广告点击行为预测的深度学习模型] by 张伟楠
本分享涉及的研究工作由张伟楠与其在上海交通大学和伦敦大学学院的同事共同完成,文章由携程技术中心(微信公号ctriptech)侯淑芳根据演讲内容整理,并经过演讲者本人确认和授权发布。
责编:周建丁([email protected])
CCAI 2016中国人工智能大会将于8月26-27日在京举行,AAAI主席,多位院士,MIT、微软、大疆、百度、滴滴专家领衔全球技术领袖和产业先锋打造国内人工智能前沿平台,6+重磅大主题报告,4大专题论坛,1000+高质量参会嘉宾,探讨人机交互、机器学习、模式识别及产业实战。门票限时八折优惠中(http://huiyi.csdn.net/activity/product/goods_list?project_id=3023)。










