
题图由我厂AI生成
谷歌CEO的闭门讲话中的AI前沿
一、施密特的讲话
最近,谷歌前CEO施密特在斯坦福给大学生们做了一个关于AI的讲话。
媒体炒作说,
施密特本来以为是一个闭门讲话,所以讲了很多不公开的秘密
。
在演讲进行的过程中,别人告诉他,这个演讲正在直播。
有没有这件事情呢?
有。
施密特开始确实以为是一个闭门讲话,当他得知这个讲话正在被直播,他就有些吃惊。
但是施密特讲的东西,并没有什么桌面低下的话,而是可以公开讲的。
我第一时间,就把讲话内容给我们AI社群的人进行了分享。
施密特这个人,在IT互联网行业影响力还是很大的,以精明著称。
2006年,施密特就上了福布斯富豪排行榜,位列129位。
2023年,施密特在福布斯美国富豪排行榜上,以200亿美金的身价位于36位。
2024年,施密特在胡润全球富豪榜上,以200多亿美金,排名87位。
施密特是世界上第一批,以打工的身份,通过获得股权而得以成为富豪的人。
他的特长是什么呢?
就是善于把技术变现,构建持久的盈利模式。
他原来在Sun公司的时候,就把当时Sun认为是失败技术的Java搞起来了。
Java现在依然是企业领域内的王者。
他在谷歌的时候,巧妙的把搜索和广告结合起来,找到了变现路径。
现在大家都知道,
搜索业务简直就是印钞机
。
施密特这么精明的老狐狸,都投了他看好的所有AI公司,包括法国的Mistral。
从施密特的讲话中,还是能看出几点有用的东西的。
其中一点,就是整个硅谷、甚至整个美国科技界,都在豪赌人工智能这件事情。
马斯克构建了
10万
张卡的超算中心,扎克伯格可能有
30-60万
张卡。
他们几百亿美金地猛砸,就是希望通过AI与别的国家,比如中国,
拉开十年以上的差距
。
一个系统分为道法术器。
做事情,就像搭积木一样,你要先搞定基本的积木,才能根据积木搭出一个大厦。
像施密特这种赚到大钱的,根本就不关心怎么做AI视频,而是关注最基本的积木。
在基本的积木中,施密特认为
3件事情比较重要
。
第一点就是“长文本”。
长文本,你可以理解成大脑的“记忆”能力。
记忆是推理的基础,因为你记得的东西越多,才能做好推理。
这个长文本,就像人类大脑的
长时记忆
一样,决定了AI的理解和推理能力。
长文本这块,Kimi做的就比较好,主攻这个方向。
美国很难说在这方面与中国拉开差距。
同时,还有一些技术,可以替代长文本,比如说RAG,就是检索增强技术。
这个就等于说,你记不住,可以翻书,通过检索来增强理解能力。
其实我们前面说过的“欧神大模型”,就是采用的RAG技术。
效果不错。
只是现在很多资料还没有添加,资料添加的越多,就越聪明。
事实上,我们社群有几个小伙伴,用这个技术为企业的文档进行定制搜索,已经拿下好几个项目,赚到钱了。
二、第二块积木
很多人不了解的人,以为我们就是搞一些画画什么的。
不是的。
我们当然也搞大模型的,其中就有一个架设了各种开源大模型的板块。
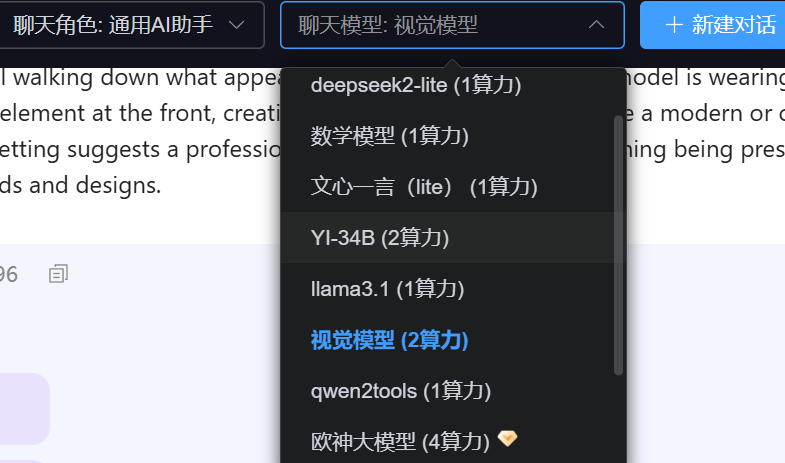
这个里面,一些知名的开源模型都部署了,供大家研究。
比如清华智谱的GLM大模型、李开复的YI大模型、阿里的通义千问、闭源的文心一言等等。
除了闭源的模型,我们
都是教大家本地架设的
。
开源大模型这种事情,你自己在电脑上
架设1-2次
,把基本的技能学会了,你也就不想再尝试了。
因为这个里面有无数的坑,你也不想再折腾了,觉得浪费时间和精力,甚至硬盘都被各种模型占满了。
就像装机一样,你就装
1-2次就把这块搞懂了
。
如果不是为了工作,后面就不想再折腾了。
但是开源模型又不断地出来,你也想测试、研究一些新能力。
这个时候,就不如用我们这个板块,节省自己架设的精力和时间。
我们通常都是第一时间上架各种新的模型,现在已经下架很多了。
当然,也有视觉模型,就是你发一张图片,模型就帮你识别图片里面有什么。
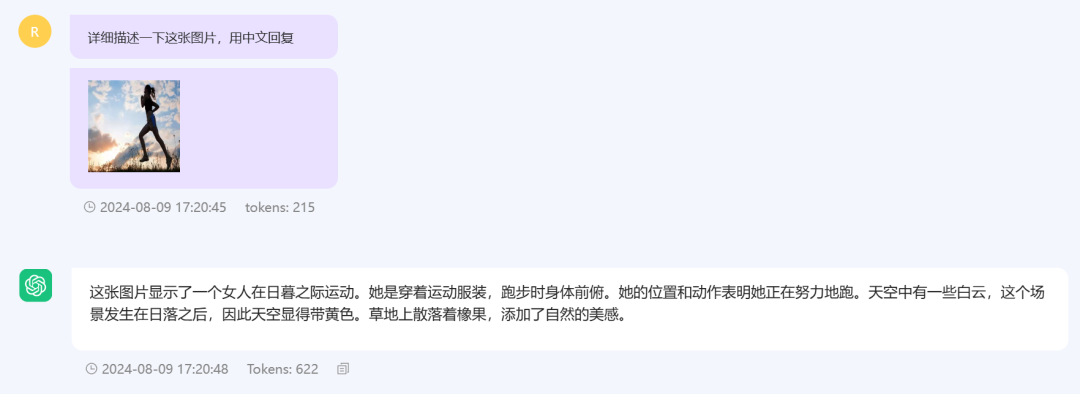
施密特提到的第二点,就是文本到行动(Text to Action)
很多人以为AI只能写写画画,那是对AI完全不了解。
当人类看见一只老虎出现在面前的时候,请问,老虎在人脑中的形象,是真实的老虎吗?
不是的。
人脑中的形象,其实是
人脑模拟出来的一支老虎
。
这只老虎和真实的老虎,还是有点区别的。
人脑之中,其实有一个模拟的小世界,是对现实的投射。
已经有很多视觉错觉的例子证明这其中的区别。
比如下面这张图,根本就不是一张动图,但是你在盯着看的时候,就觉得是动图。

这个就是大脑产生的错觉。
所谓的AI“写写画画”,只是AI目前在模拟这个世界而已。
只有AI能成功的模拟这个世界,然后才能产生成功的行动。
文本产生文本,这个就是大模型,也是chatgpt的主要功能。
文本产生图像,这个就是文生图模型,比如mj、sd等等。
文本产生声音,这个就是文生音频模型,目前suno做的比较好。
文本产生视频,目前有sora、luma、runway,国内有快手的可图、清华智谱的清影等等。
这些,都是对世界某个维度的一种模拟。
现在俄乌战场上,一架几千块的无人机,就可以干掉一辆几千万的坦克。
但是这个主要还是人在控制无人机。
文本一旦可以产生行动,大模型就可以直接控制物理世界了。
比如说,用大模型控制无人机、坦克、飞机、大炮,当然还有家用设备等等。
文本产生行动,最简单的方式,就是让大模型调用工具。
大模型本身就是训练的产物,里面是没有实时信息的。
比如说,你让大模型告诉你今天哪个城市的天气,大模型是没办法的。
因为天气是气象台实时获得后,分发给各个平台的。
但是看看我们这个平台的演示,武汉的天气和海口的天气是实时获得的。
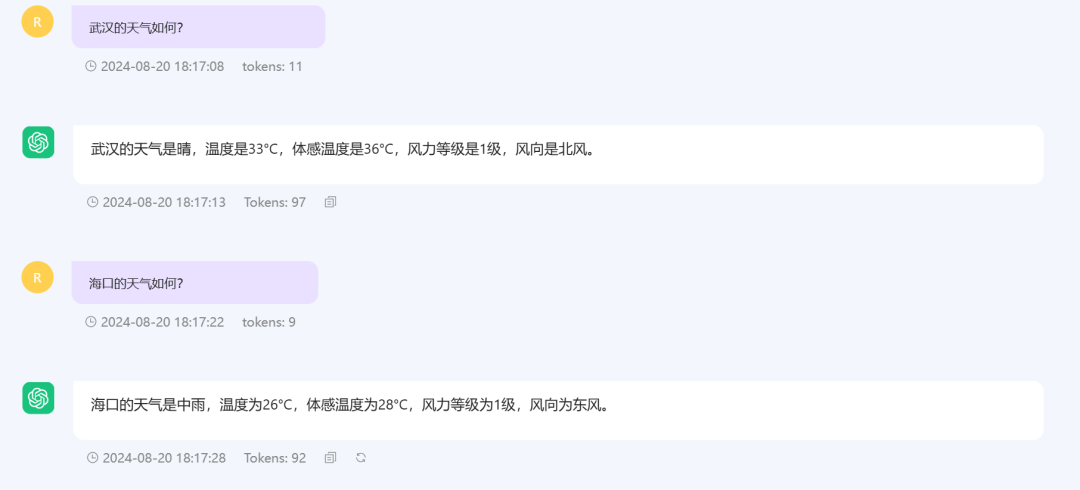
可以说,非常准确。
当你问大模型哪个城市的天气的时候,大模型就判断这个需要行动,然后通过接口去获得某个城市的天气。
这个我们已经在本地实现了,成功的让大模型产生了行动。
如果不是让大模型获得天气,而是向坦克开火呢?
这个威力就巨大了。
当然,让大模型产生代码,让代码再产生行动,就更复杂了。
比如说,我们让大模型写一段代码,画一个心型。
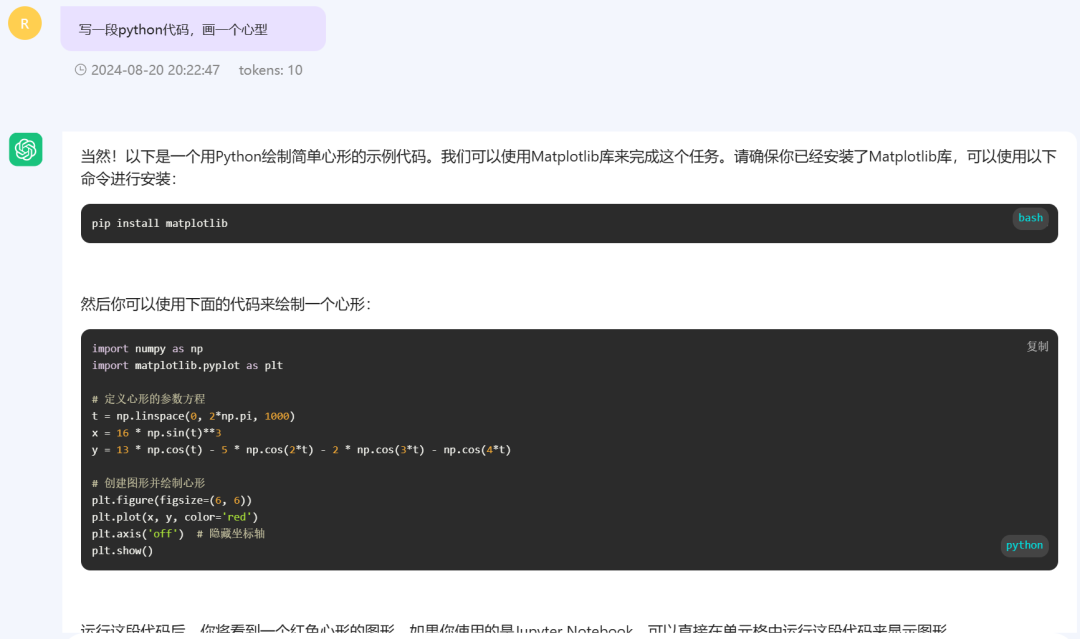
然后,一直不改的执行这段代码:

谁说AI不能写代码的?
只是写复杂的代码,还需要时间。
三、智能体
第三点,施密特认为是智能体(Agent)
所谓的“智能体”,简单的说,就是把一个推理分为很多步骤。
一个大问题,分为很多小问题。
每个小问题的解决,都可以让大模型或者其它工具来解决。
最后,整个问题就解决了。
这个是一个挺好的思路。
通过这种方式,可以解决非常复杂的问题。
比如,我们问,武汉和海口,哪个城市的天气更热?
这个问题看起来简单,其实可以分解为3步:
第一步:获得武汉的天气,得到武汉的温度。
第二步:获得海口的天气,得到海口当前的温度。
第三步,比较武汉和海口的温度,得出最后的答案,并回答。
这个就是一个小的“智能体”,可以说非常准确。

请注意,在这段对话中,我们并没有让大模型做第一步,做第二步,然后做第三步。
具体要怎么做,是大模型自己判断,分解推理步骤,然后执行。
这个在这波AI出现之前,是没法做到的。
这里只是
3步
推理。
如果一些复杂的问题,可能需要十几步,几十步,甚至上百步的推理。
这个时候,就需要分解成不同的智能体去执行任务,最后获得一个结果。
你可能只是问了一句话,但是大模型可能在后面进行了几百步的推理。
如果AI可以进行这么长的推理,那就具有相当高的智能了。
当然,不止这些,我们还上线了









