

出品 | AI科技大本营(ID:rgznai100)
你能说出至少两种机器学习中的
Boosting
吗?
Boosting 已经存在了很多年,然而直到最近它们才成为机器学习社区的主流。那么,为什么这些 Boosting 如此流行呢?
Boosting 的流行的主要原因之一是机器学习竞赛。
Boosting
为机器学习模型赋予超能力来提高其预测准确性。快速浏览一下Kaggle竞赛和DataHack黑客马拉松就知道了—— Boosting 非常受欢迎!
简而言之,Boosting 通常要比逻辑回归和决策树之类的简单模型优越。
实际上,DataHack平台上的大多数顶级产品都是使用一种 Boosting 或多种 Boosting 组合实现的。
在本文中,作者将介绍四种流行的
Boosting
,你可以在下一个机器学习黑客马拉松或项目中使用它们。

Boosting快速入门(什么是Boosting?
)
你已经建立了线性回归模型,该模型可以使验证数据集的准确性达到77%。接下来,你决定通过在同一数据集上建立k近邻算法(KNN)模型和决策树模型来扩展你的数据集。这些模型在验证集上的准确率分别为62%和89%。
显然,这三个模型的工作方式完全不同。例如,线性回归模型尝试捕获数据中的线性关系,而决策树模型尝试捕获数据中的非线性。
使用这些所有模型的组合而不是使用这些模型中的任何一个做出最终的预测怎么样?
我正在考虑这些模型的平均预测。这样,我们将能从数据中捕获更多信息。
这主要是集成学习背后的想法。 那么
B
oos
t
ing
出现在哪里呢?
B
oos
t
ing
是使用集成学习概念的技术之一。
B
oos
t
ing
结合了多个简单模型(也称为弱学习者或基本估计量)来生成最终输出。
我们将在本文中介绍一些重要的
B
oos
t
ing
。

-
梯度提升机(GBM)
-
极端梯度提升机(XGBM)
-
轻量梯度提升机(LightGBM)
-
分类提升(CatBoost)
梯度提升机(GBM)结合了来自多个决策树的预测来生成最终预测。注意,梯度提升机中的所有弱学习者都是决策树。
但是,如果我们使用相同的算法,那么使用一百个决策树比使用单个决策树好吗?不同的决策树如何从数据中捕获不同的信号/信息呢?
这就是窍门––每个决策树中的节点采用不同的功能子集来选择最佳拆分。这意味着各个树并不完全相同,因此它们能够从数据中捕获不同的信号。
另外,每棵新树都考虑到先前树所犯的错误。因此,每个连续的决策树都是基于先前树的错误。这就是按顺序构建梯度
B
oos
t
ing
中树的方式。
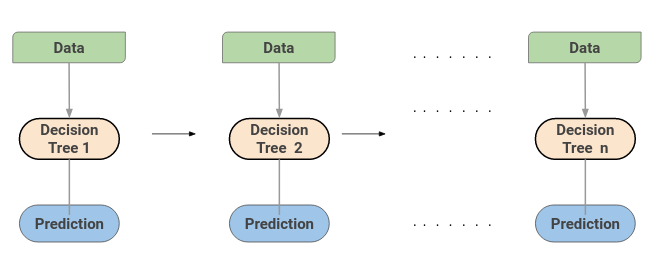
极端梯度提升机(XGBoost)是另一种流行的
B
oos
t
ing
。实际上,XGBoost只是GBM算法的改进版!XGBoost的工作过程与GBM相同。XGBoost中的树是按顺序构建的尝试用于更正先前树的错误。
1)最重要的一点是XGBM实现了并行预处理(在节点级别),这使其比GBM更快。
2)XGBoost还包括各种正则化技术,可减少过度拟合并改善整体表现。你可以通过设置XGBoost算法的超参数来选择正则化技术。
此外,如果使用的是XGBM算法,则不必担心会在数据集中插入缺失值。
XGBM模型可以自行处理缺失值。
在训练过程中,模型将学习缺失值是在右节点还是左节点中。
由于其速度和效率,LightGBM
B
oos
t
ing
如今变得越来越流行。LightGBM能够轻松处理大量数据。但是请注意,该算法在少数数据点上的性能不佳。
LightGBM中的树具有叶向生长的,而不是水平生长的。在第一次分割之后,下一次分割仅在损失较大的叶节点上进行。
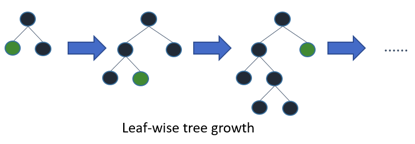
第一次分割后,左侧节点的损耗较高,因此被选择用于下一个分割。现在,我们有三个叶节点,而中间叶节点的损耗最高。LightGBM算法的按叶分割使它能够处理大型数据集。
为了加快训练过程,
LightGBM使用基于直方图的方法来选择最佳分割
。对于任何连续变量而不是使用各个值,这些变量将被分成仓或桶。这样训练过程更快,并降低了内存开销。
顾名思义,CatBoost是一种处理数据中的分类变量的
B
oos
t
ing
。大多数机器学习算法无法处理数据中的字符串或类别。因此,将分类变量转换为数值是一个重要的预处理步骤。
CatBoost可以在内部处理数据中的分类变量。使用有关特征组合的各种统计信息,将这些变量转换为数值变量。
如果你想了解如何将这些类别转换为数字,请阅读以下文章:
https://catboost.ai/docs/concepts/algorithm-main-stages_cat-to-numberic.html#algorithm-main-stages_cat-to-numberic)
CatBoost被广泛使用的另一个原因是,它可以很好地处理默认的超参数集。因此,作为用户,我们不必花费大量时间来调整超参数。

在本文中,我们介绍了集成学习的基础知识,并研究了4种 Boosting 。有兴趣学习其他集成学习方法吗?你应该查看以下文章:
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/?utm_source=blog&utm_medium=4-boosting-algorithms-machine-learning
你还使用过其他哪些
B
oos
t
ing
?你使用这些
B
oos
t
ing
取得了成功吗?欢迎在下面的评论中与我们分享你的想法和经验。
原文:
https://www.analyticsvidhya.com/blog/2020/02/4-boosting-algorithms-machine-learning/
(*
本文由AI科技大本营翻译,转载请微信联系1092722531










