本文为友情转发唐杰总投稿,供读者参考学习,不完全代表编者观点。
100G Ethernet => 2.6M IOPS(4K) !!!
(1)
各位都记得
2016
年
7
月,
NVMe
组织发布
NVMeoF
(那个时候应该是写成
NVMf, NVMeoF
的名字是
2017
年初大家才通过的正式缩写)的标准的时候,大家都很激动,
RDMA+NVMe
,都是新技术呀。本人也写了一个系列来讲
NVMeoF
对于存储,以及数据中心的改变。当时也说过了
Xilinx
作为
FPGA
芯片厂商在这个方面的投入。
现在,是时候做一个总结和回顾了。给大家讲一下,目前
Xilinx
的
NVMeoF IP
的状况。
如果大家有机会去美国丹佛参加
11
月初的
SC17
,请不要忘了去
Xilinx
,还有菊厂的台子上看看。
NVMeoF
的诞生之初的目的就是把
NVMe
的存储拉远,让它在性能上和本地的
NVMe
盘没有缺别。这样可以实现存储架构的解耦合,方便计算和存储分离的实现,实现集中化,
从而简化存储的管理。
Xilinx
在今年很火的
FMS
上准备了这个
DEMO
,但是因为大会太火了,整个展览场地关闭。没有机会给大家见识。
Xilinx
目前实现的
DEMO
的情况是这样的:
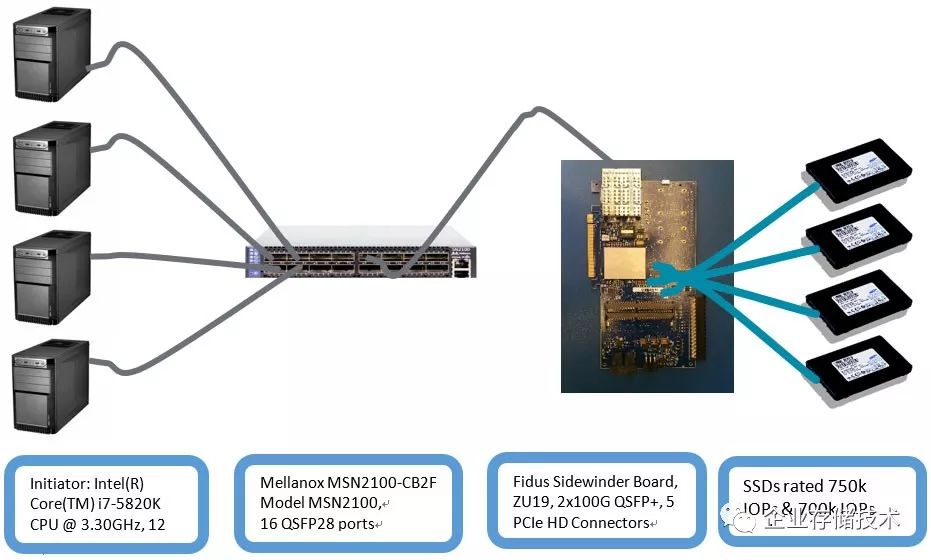
Host是4个标准的X86
PC,主频都是3G以上的CPU,每个上面有一张Mellanox CX-4 100G的网卡,连接在Mellanox
N2100的100G交换机上。OS 是标准的RedHat RHEL 7.2 +Linux kernel
4.9。另外一边是一个FPGA的开发板,上面有一个100G也连在交换机上,板子上有4个PCIE接口,分别直连了4个Samsung1725a的SSD。
目前的release的性能(随机读)如下:
|
Block Size
|
IOPS
(
K
)
|
BW
(
MB/s
)
|
|
4K
|
639+694+663+664=2660
|
10640
|
|
8K
|
345+347+346+346=1384
|
11072
|
|
16K
|
176+176+173+178=703
|
11248
|
关注
NVMeoF
的专业人士应该知道,目前这个单口
100G
的
2.6M
实测性能是可能看到过最高的了,
如果有不服,本人可以带家伙去怼。
J
这个
DEMO
从一开始的
1.2M
一路走来,其中有无数次咖喱味的电话会议和各种惊喜和失败,真心不易。
大家都知道全闪阵列的路其实不是很顺。做全闪的先烈小提琴早已破产,
IBM
的
Flash system
不温不火,
Solidfire, nimble,tegile, whiptall
都已从良,只有一个新出来的
Purestorage
还在撑着。
大家这么不容易,除了
Samsung
和
Micron
高达
40%
的盈利增长以外,也是有技术原因的。记得上次,有一个大神骄傲地宣布,我家的
Power8
可以支持
NVMe
了,
当时差点没吐出来,
NVMe
的标准从
2007
年开始制定,
那个时候叫
NVMHCI
,(
现在已经是
Intel Fellow
的
Amber
还是一个
softwareengineer
),也快十年了,现在才支持,算是后知后觉了吧。
其实不然,看看现在的存储,全面支持
NVMe
的存储还是非常少的,大部分人还在用
SASSSD
或者加个双口扩展的
SATA
,大部分存储厂商还是走着从
IDE/SATA
,
SCSI/SAS
这样的路,要知道,基于
SCSI
的存储系统在过去的
15
年中积累很难放弃的。大家的做法基本上是:
后面用传统的
SASJBOF
安装标准的
SAS/SATASSD
,前面用
X86
的存储机头做高端功能,使用大量的
DDR
在机头上做各种缓存。这样,只要前面的
LSMTree
的实现做的好,后面的压力就不大。因此
SASSSD
完全可以。
但是,
但是,但是,
DRAM
产家出来捣乱了,
1T
的内存,很美丽,也很贵。大家都记得这张图:
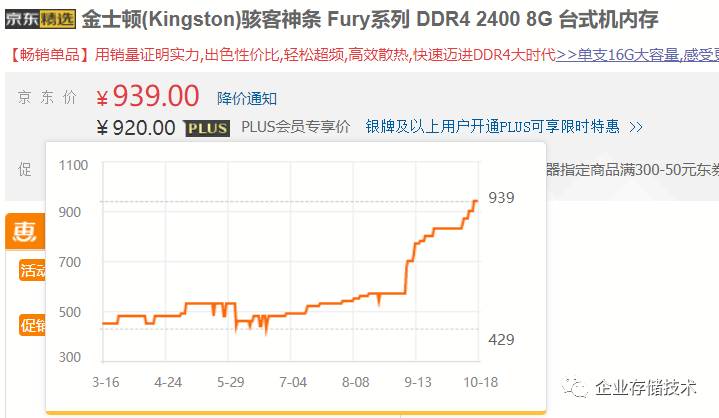
怎么破???
100G Ethernet => 2.6M IOPS(4K) !!! (2)
说到内存,这个是大家都绕不过去的话题,和做企业存储的厂家聊天的时候,说起了现在的
NVMe SSD
的
Raid
性能太差,不管是博通的三模式,还是
Intel
的
VMD
,
在做稍微复杂的
Raid5/6
的时候,性能都很锉;
人家立马说我的
Raid5
性能刚刚的,当时心里一紧,难道自己这么快被拍在沙滩上了(本人在
LSI
做了至少两年的
SSDRaid
的性能优化,实在是对不起大部分
Raid
的用户,那东西的
Raid5
写放大忒大了)?
人家接着说,我机头上有
512G
的内存!!!
博通和
Intel
的内存都是
1-2G
。
这就是存储系统一路追随
Intel
的现状,大家等着
Intel
扩内存控制器,内存厂家上大容量
DRAM
,什么东西都放
DRAM
。直到现在,内存厂家开始集体收割。
我在
CNCC2017
的数据中心存储论坛上看到了阿里云盘古
2.0
的系统架构师吴结生的一些方向性思考,深以为然。
数据通路和控制通路的分离,
这个应该是存储系统“戒”内存的出路。在过去从
GSM
,到
3G
,
4G
,以及未来
5G
的通讯业中,他们就大致遵循了这个原则,数据通路尽可能使用硬件,控制通路在各种
CPU
上。
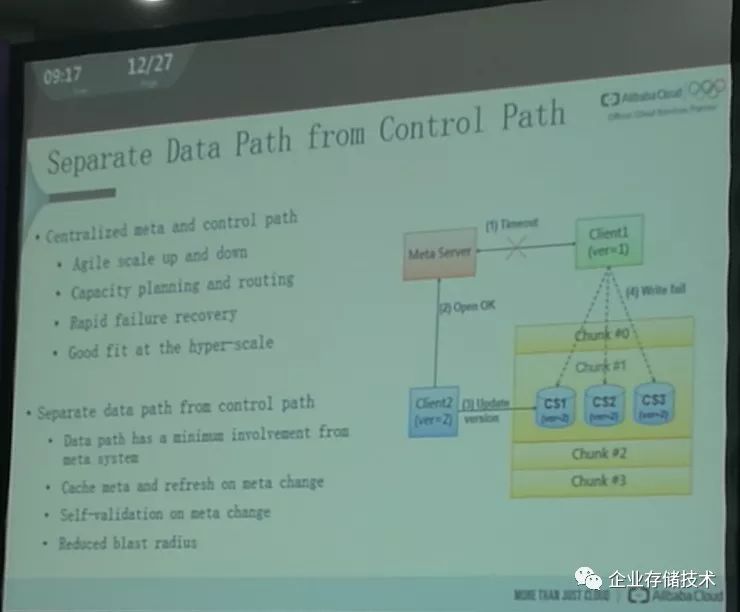
作为存储系统,主要目的是以低成本的方式给自己的客户尽可能提供存储资源。在
NVMeoF
的时代,前面是
RDMA
的网络,后面是
NVMe
的
PCIE
的网络,这个是很大
topic
。数据中心的大王
Intel
之前做过一个产品,
FlexPipe
,希望在一个片子上集成
Ethernet
和
PCIE
。这个是
Intel
的
RSA
架构的核心思想,通过集成机架内两种主要的
Fabric
来实现对
Rack
架构的解构以及优化。
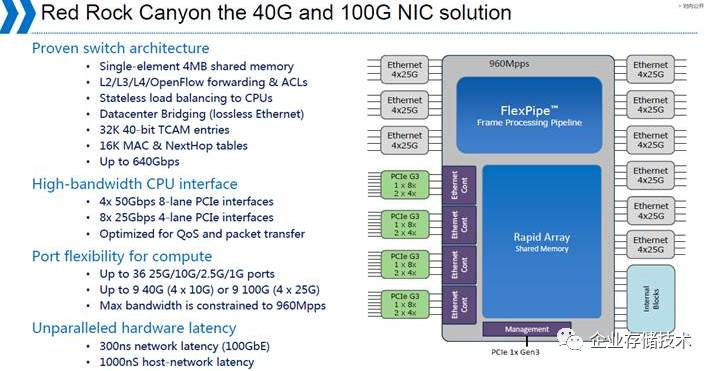
大家可以看到,这个芯片的计划很宏伟,最后也是无奈放弃,这个也可能是
Intel
在
25G Ethernet
市场上没有作为的原因。
在
NVMeoF
的时代,当大家再次面临这个需求的时候,也再次想到了使用硬件加速的方案,和上次相比,这次的需求更清晰。
Xilinx
在一开始做
NVMeoF
加速的时候,首先想到也是
offload
数据搬移,尽可能使数据通路不用通过
CPU
。将
NVMe SSD
连接在
FPGA
上,通过
PCIESwitch
和
RDMA
的网卡利用
PCIE
的
P2P
功能进行通讯。
在这个架构中,数据直接从
NVMe
出发被
push
到
RDMA
的
QPs
中,
NVMe
的
CQ/SQ
以及数据传输的
Buffer
都在
FPGA
上的
Block RAM
中,数据不用和传统的
X86
架构一样,需要把数据从
NVMe
上搬移到主机的
DRAM
中,然后再通过
RDMA
的
QPs
发送。
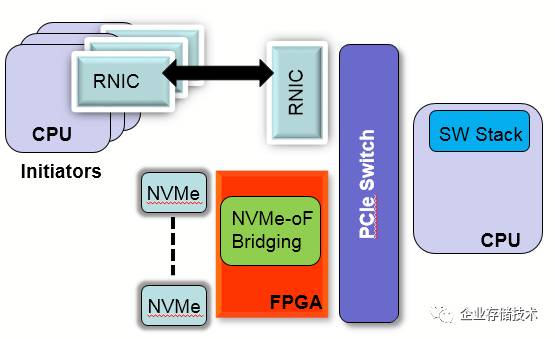
这个架构里面,我们遇到几个问题:
1.
P2P
的性能问题,
100G
的
RNIC
的
PCIE
接口是
Gen3 X 16
,
PCIE SW
的
P2P
的性能是有上限的。
2.
客户不买单,这个系统的东西太多,虽然数据链路在
FPGA
上,主机不需要太多内存(可是,内存在
2016
年上半年还没有上涨)。因此成本和收益不明显。
3.
大部分客户的想法还是
Samsung
一样,我大不了加
CPU
和内存,
反正用全闪的人都不差钱。
Samsung
为了达到
2.25M
的
IOPS
,使用了
quad-socketXeon E7-8890 v4 server , populated with 512GB DDR4 memory
。【
1
】
反正内存都是自家,可劲造。
Xilinx
下一步怎么走,的确是一个问题?
【1】
www.samsung.com/us/labs/pdfs/nvmf-disaggregation-preprint.pdf
100G Ethernet => 2.6M IOPS(4K) !!! (3)
和大家一样,当
NVMeoF
的标准出来之后,我们也在考虑如何快速帮助客户推出性价比靠谱的产品。和大部分潜在用户讨论之后,发现使用标准的
RDMA
网卡这条路可能有问题,因为
25G
的大户,
Mellanox
的网卡已经号称支持
NVMeoF
的协议卸载(其实,我到现在都没明白,
Mellanox
如何做到在
NVMeoF
协议没有推出之前都能在
ASIC
上做协议卸载)。
摆在眼前的选择不多,也很明显,必须要在
FPGA
做
Intel
做了几十年的事情——集成。
FPGA
的好处就在这里体现了,我们可以方便地实现各种
I/O
的接口,并在内部通过
AXIBUS
进行低成本的互联。
使用集成大法,使用
FPGA
的
100G
的
MAC
做了一个支持
RoCEv2
的
100G RDMA Ethernet interface
,使用
FPGA
上的硬核(
ARM A-53
)
,
或者软核(
MicroBlaze
)做控制链路。
在
NVMe
后端,使用
PCIE
硬核
+
软核的方式可以支持多达
8
个的
NVMe SSD
。
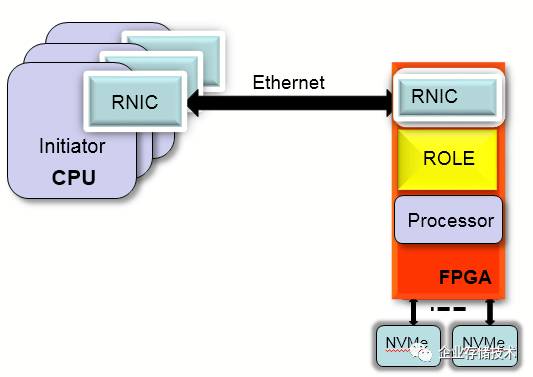
从系统框图上,可以看到整个方案就是一个单芯片解决方案。可以说是把一个
X86
的存储机头在
FPGA
里进行了实现。
当然,和任何创新一样,都不是一帆风顺的。使用
FPGA
做
RDMA
的网卡并不多见,
ARM
的生态,特别是对于数据中心至关重要的
PCIE
的生态也不健全,毕竟
ARM
上支持一个
PCIE RC
以及多个
PCIE rootport
都是新课题。
在
FPGA
中实现
NVMeoF
的优势也是比较明显的:
1.
NVMeoF
对于
RDMA
的
verbs
的要求很低,只用实现部分的命令,同时
NVMeoF
所有的
I/O
都是从
Target
发起,因此只用实现部分功能即可。

2.
FPGA
中有大量的
BlockRAM,
在通讯业中使用
BlockRAM
构建多级的
FIFO
来实现数据管道,这
NVMeoF
中,可以构建面向
NVMe
的
CQs/SQs
,
RDMA
网卡的
QPs
。利用
FPGA
的片上内存,可以实现
clock
级别的数据传输。使用了
cutthrough
的
dataflow
,不用使用大量的
DDR
来做数据缓存。
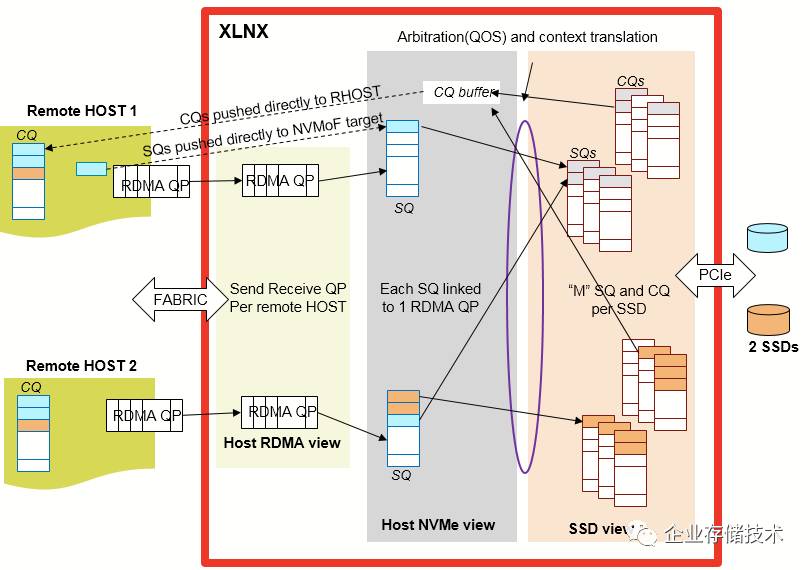
3.
因为
AI
兴起了异构计算这个概念,
FPGA
厂商也从善如流,推出了包含
ARM
硬核的
ZYNQ
系列产品,在这里
ARM
可以做控制链路,
不参与数据的传输。使用
ARM
,也方便了我们的软件开发,目前
ARM
上的软件都是从
Linux
的
upstream
上移植过来,除了支持
Xilinx
的
Petalinux
以外,也会支持类似
RHEL
的
Data Center
操作系统。在性能测试过程中,
Xilinx
的
A-53
的
ARM core
很淡定。
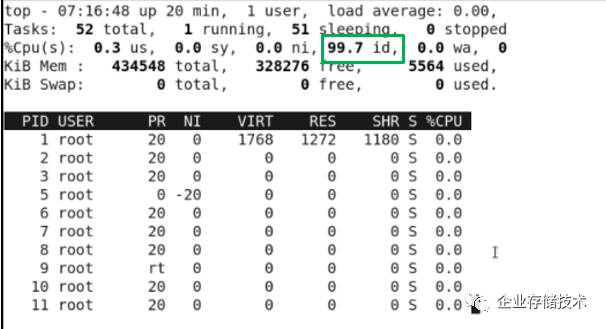
经历了种种考虑之后,
Xilinx
开始行动了,于是有了这个板子【
1
】,作为
Xilinx
在数据中心的
I/O
加速板,
实现了
ARM
在控制链路,数据链路在
FPGA
的实现。
插播广告,这个平台同样可以做对象存储的接口,实现
KV store
,请移步【
2
】。

【1】
http://sidewinder.fidus.com/
【2】
https://www.missinglinkelectronics.com/index.php/menu-products/key-value-store-accelerator
扩展阅读:《
NVMe over Ethernet:又一家FPGA互连闪存的Apeiron
》
100G Ethernet => 2.6M IOPS (4K) !!! (4)
和大部分技术一样,通往罗马的路不止一条。我们来看看目前市场的竞争态势。
NVMeoF
作为新型存储介质的互联协议,在一开始就不同的厂商使用不同的方案。在我去年的
NVMeoF
系列中,讨论了
NVMeoF
支持的多种网络传输协议,目前来看,基本上都聚焦在了
ROCEV2
上。目前在全球的
Hyper-Scale
数据中心,
Microsoft
已经实现了规模部署。
在过去的两三年中,发生在大型数据中心的网络侧一个重大的事件就是
25G Ethernet
的出现和部署。
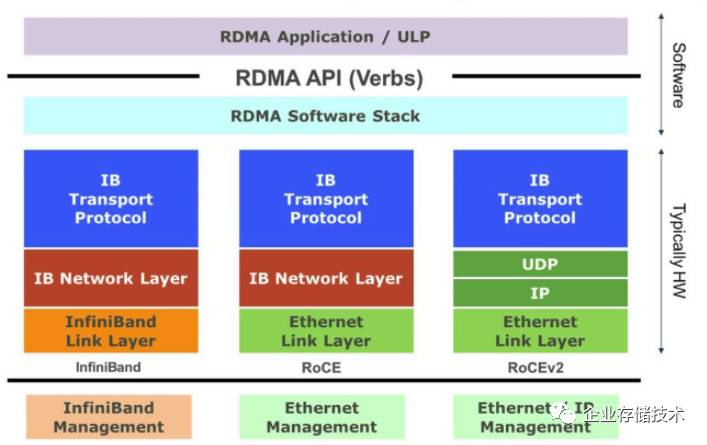
在大部分的
Hyper-Scale
数据中心中都部署了
25G
,因为
25G
目前最大的供应上
Mellanox
可以支持
RDMA
,因此将
RDMA
变成了数据中心的硬性需求。和前面讲的一样,因为有了微软的大规模部署,因此
RoCEv2
目前是最有竞争力的网络协议之一,它能够在
Ethernet
的数据链路层上提供低延时,低
CPU
利用率的网络传输。
但是,
RDMA
并不是所有的故事。
Intel
作为一直没有
RDMA
的网卡厂家,走上了
CPUPolling
的这条路,于是有了
DPDK
,
SPDK
,
TCP on DPDK
等等。使用大页内存和
CPU
的
Polling
,从而在网络上
bypass OS
的
kernel
,在用户态实现和用户的应用的对接。在
25G
的
RDMA
时代,阿里云最近发布的神龙服务器也是一个代表。
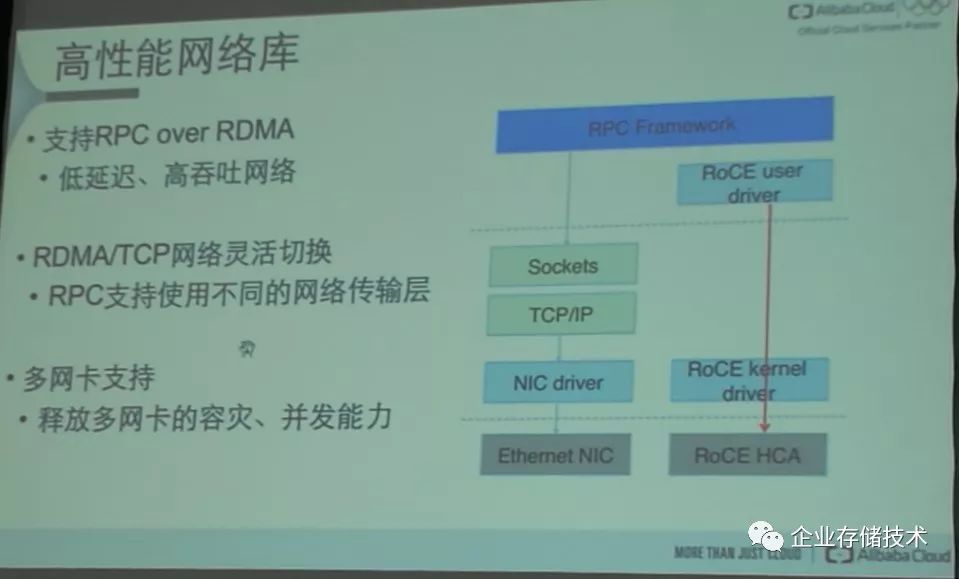
对于
xPDK
家族的未来,可以看到很好的延续了
Intel
的
X86
传统,通过
CPU
和
DRAM
的升级来像升级
PC
一样升级服务器的
I/O
系统。在用户态实现
I/O
的功能,从而避免
KernelI/O
堆栈带来的延时。但是因为
I/O
路径,以及目前
CPU
的
NUMA
架构的原因,
xPDK
之类的方案的延时有明显的下降,但是还在要比硬件加速方案高一些。
对于
NVMeoF
来讲,目前除了
FPGA
方案之外,还有两个不同的方向:
1.
Intel
的
SPDK
,以及基于
X86 CPU
的
Polling
方案。
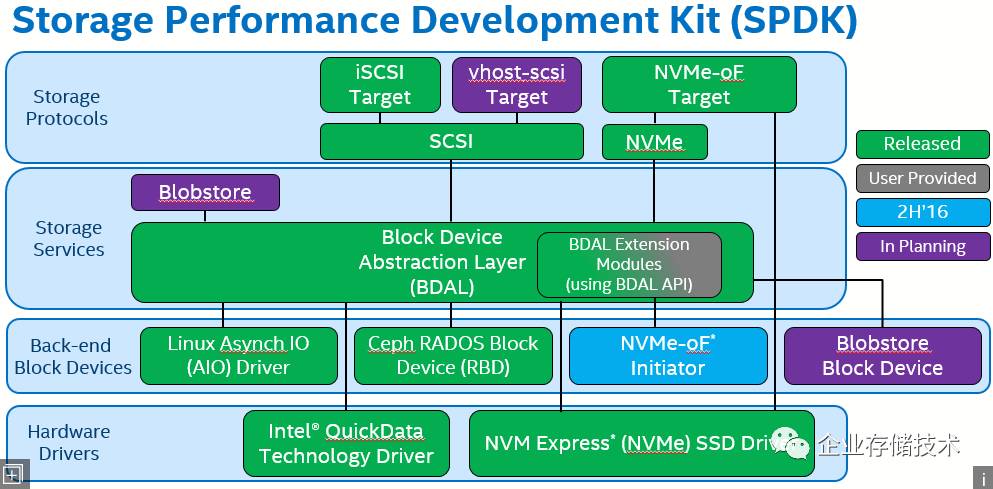
通过
SPDK
的框架,大家可以看到,
Intel
计划在
CPUPolling
的基础上使用用户态的存储服务,为了更好的支持
Flash
存储介质,并增加了对于硬件压缩的支持(
Intel QAT
)。
2.
Mellanox
,
Broadcom
,
Marvell
等芯片公司的
ASIC
方案。
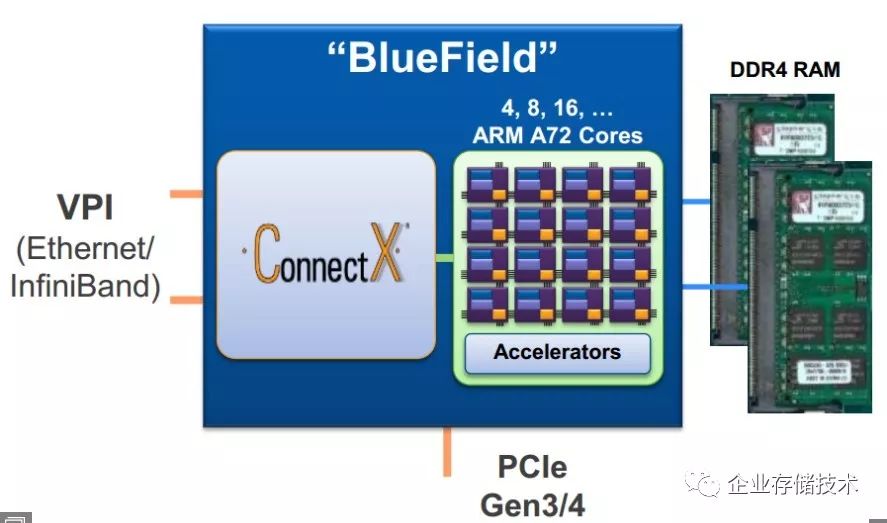
这个方向的厂商基本上都是采用众核
+NIC
的集成方案,在众核上使用多个内存通道,甚至可以在
ARM core
上实现内部的
SPDK
方案(如果
Intel
支持的话)。
扩展阅读:《
单芯片方案能否加速NVMe over Fabric普及?
》
目前三种方案的对比如下,
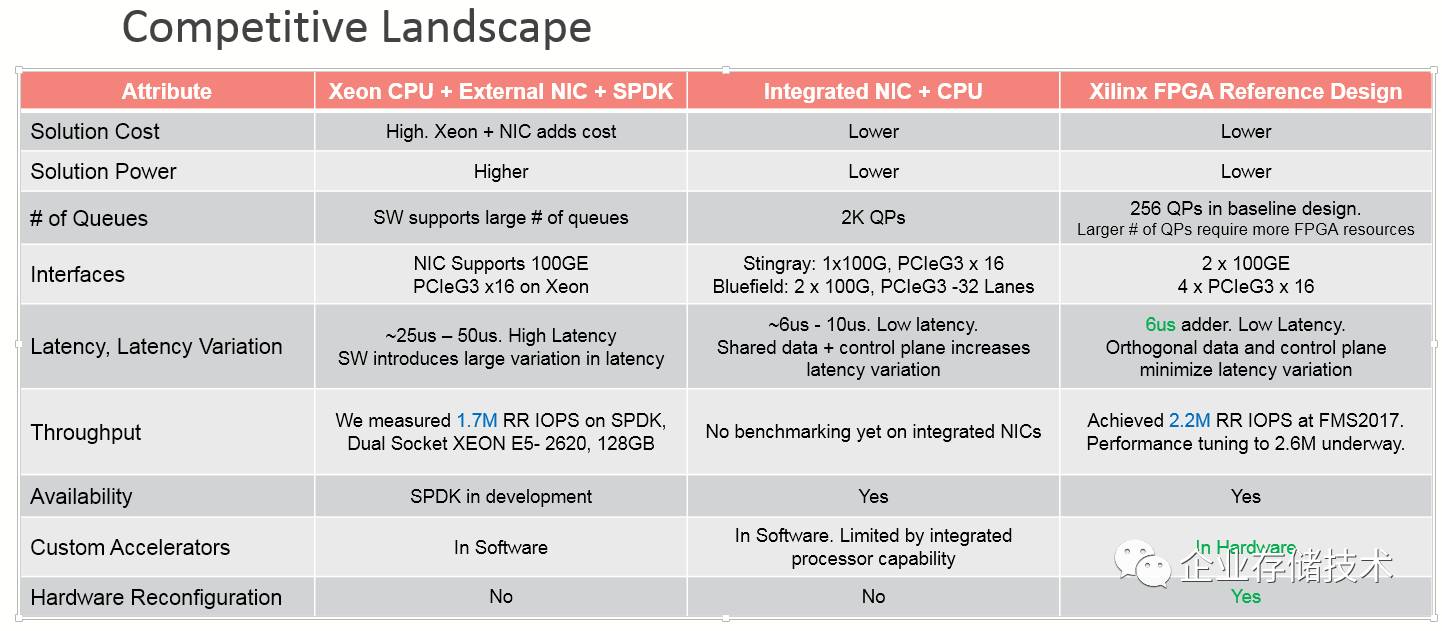
100G Ethernet => 2.6M IOPS(4K) !!! (5)
我们在开篇的第一部分中提及了目前的存储厂商全闪产品的架构,基本还是
X86
存储的机头
+SAS SSD+JBOD
扩展。在
2016
年的时候,也有一些存储厂商,包含
OCP
的
Facebook
都推出过一些
NVMe
的存储盘阵,但是基本上都没有规模部署,其中除了成本较高以外,还存在一个重要的技术原因,
PCIE
的扩展性。
在大部分全闪的存储系统中,大家都采用
X86
存储机头服务器,通过
SAScable
进行级联
JBOD
,无论是使用
SAS HDD
,或者
SAS SSD
,大家通过传统的
SAS switch
进行存储资源的
scaleout
,这个是目前性价比最高,也是最健壮的一种扩展方式。
当存储厂商开始部署
NVMe SSD
的时候,他们使用了
PCIEswitch
来替代
SAS Switch
,使用
PCIE
的
HBA
来替换
SAS HBA
,不知道有多少读者见过
PCIE
的
HBA card
。这个扩展卡和传统的
HBA
不同,直接连接在
CPU
里面的
Root Port
上。

这种使用方式,连国内
PLX PCIE switch
最大的用户都认为,
PCIEswitch
的使用成本太高,而且系统的稳定性挑战比较大,因为
PCIE switch
环境下的
error
的隔离非常重要,否则就有可能和
TeraData
的集群一样面临可靠性的问题。
随着
NVMe oF
的出现,使用
100GEthernet
来代替
PCIE
成为互联接口变成可能,在传统的使用磁盘阵列进行扩展的场景下,
100G
带来的可用性优势明显。因此,在
2017
年
7
月,
pure storage
推出了他的下一代设计,基于
NVMeoF
的存储扩展框
FlashArray //X
。【
1
】
扩展阅读:《
NVMeF的另一种用法:连接AFA控制器和JBOF
》
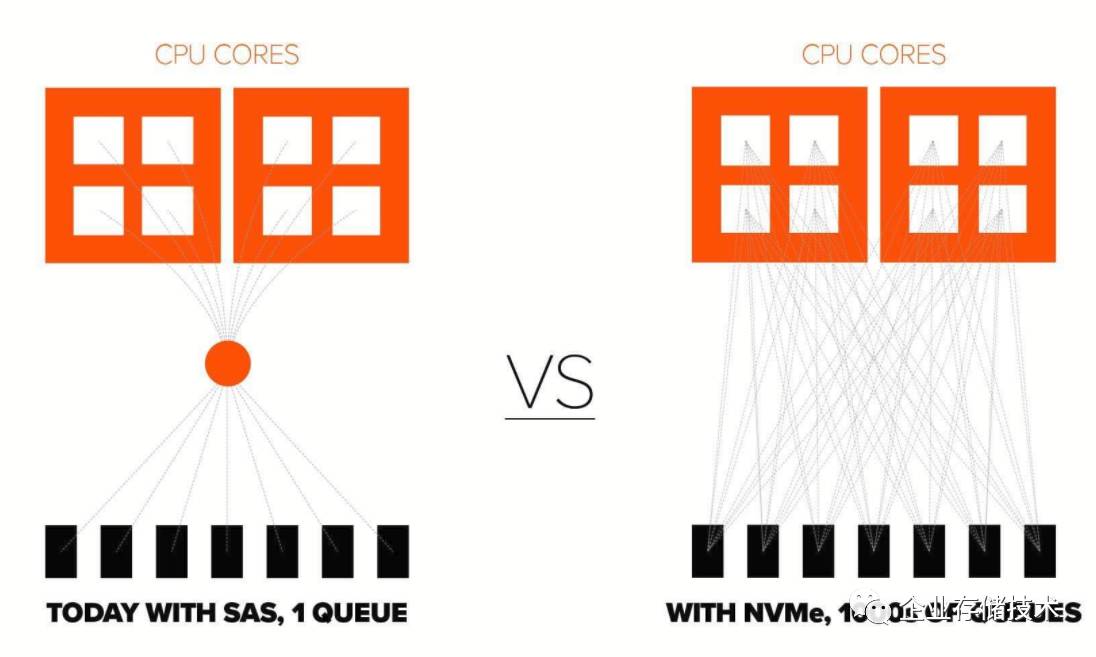
因此,可以预见,未来的企业存储的架构会使用
100GEthernet
进行扩展并提供服务。
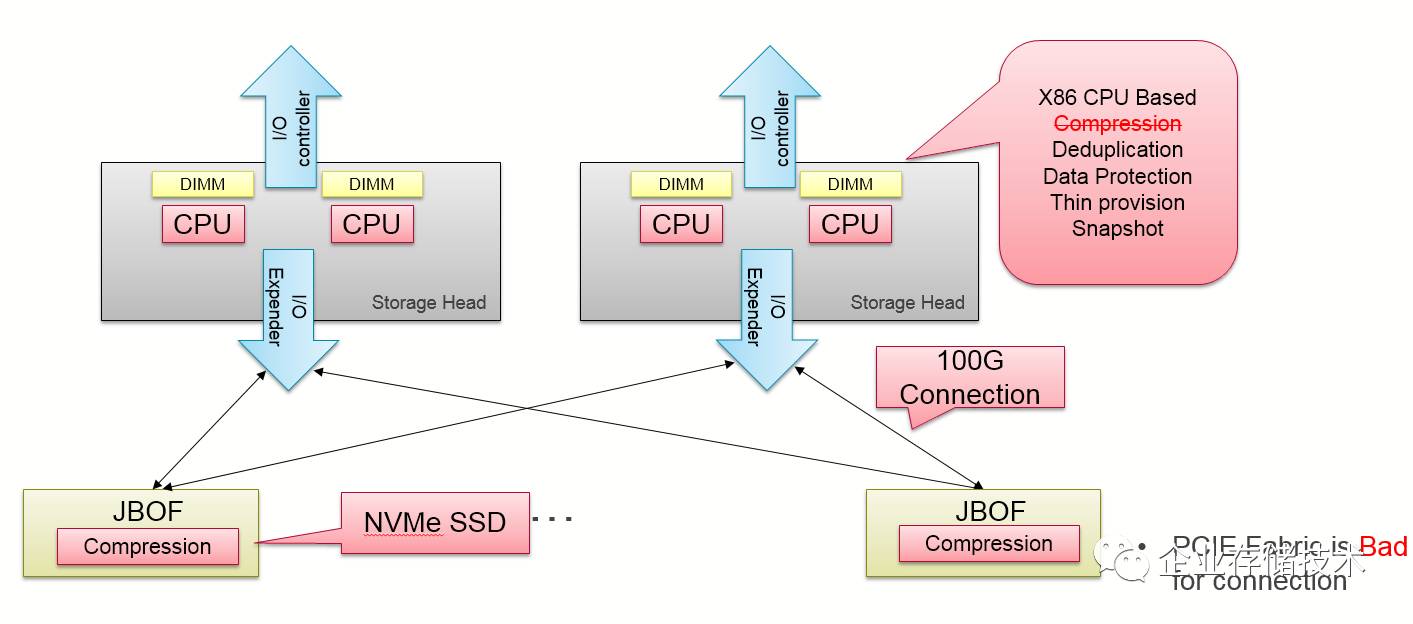
同时,因为全闪阵列带来的两个必须的功能,压缩和去重,从而是
X86
的
CPU
在对外提供服务的同时有了更大的
workload
,不止一个存储厂商在考虑使用硬件进行压缩的实现。
对于未来的存储系统,
相信大家会沿着
NVMe
取代
SCSI
协议的路上越走越宽,还是用
Alibaba
盘古
2.0
的系统架构师的一个展望来结束这个系列吧。
“
Microsecond-ScaleEra”

【1】
https://blog.purestorage.com/extending-nvme-leadership-introducing-directflash-shelf-previewing-nvmef/
100G Ethernet => 2.6M IOPS(
后记
)
每年一度的
SNIA
的
SDC
是存储厂家的盛会,同时也是未来一年的存储设备发展的风向标。相对于
FMS
这样的会,
SDC
的广告成分要少一些,毕竟现在踏踏实实做存储的厂家已经不多了,大家都是自己人,不忽悠。
Samsung
从做面粉到做面包【
1
】
和之前的
NVMeoF
系列提过的一样,
Samsung
公布了他们
NVMeoF
测试系统的更加具体的规格和性能指标。这个在之前的论文中有提。出人意外的是,人家也意识到这个时代已经是,
“
通用已死,应用为王
”
,
人家附上了
RocksDB
和
Mysql
的应用级别的测试数据,与时俱进呀。
在应用级别的测试,也清楚得显示,
NVMeoF
完败
iSCSI,
性能和延时基本和本地的
DAS
持平。在他们结论中,
NVMeSSD
和
NVMeoF
的结合是
flash
存储系统解耦的最佳实践。
SPDK
的赞歌和不和谐的声音
和很多
Hyper-Scale
主导的会议不同,
Intel
没有让小弟站台,自己直接出马。
Intel
关于
SPDK
的
session
有
3
个。
两个是个
Ceph
相关【
2
】【
3
】
,
一个是和
NVMeoF
相关。
Intel
在
Ceph
上的投资,作为中国存储届的看客都应该知道
Xsky
,因此就不多说。对于
NVMeoF
的方案【
4
】,建议大家到
spdk.io
上实操。
关于
SPDK
的不和谐声音,居然是从我十分敬仰的人那里出来的,
Stephen Bates
,
当年
Microsemi
收购
PMC
之后,一度可能成为
PMC CTO
的人。这位老兄也是国产
NVMeSSD memlabze
的老朋友。他的
session
主要是在推
p2pmem PCIE P2P
【
5
】
在
Linux
上实现。他的一页胶片也是非常打动我心:
”SPDK reduces latency, but at what cost ?” xPDK
,我个人总觉得是个临时方案,毕竟
100%
全速运转的
CPU
真心不环保。特意放上这张图来怼
xPDK

在
Stephen
的另一个
session
中他也做了一个
NVMeoF
的展示,就是用
NVMe SSD
,
Mellanox RNIC
,
COTS PCIEFPGA
和
Intel CPU
展示了
Xilinx
目前的类似的方案,大概和
2016
年初,
Xilinx
的方案类似(见本系列之
2
)。这里面还有一个小小的请求,就是
NVMe SSD
控制器中最好实现非易失的
CMB
,来实现
PCIE
的
P2P
功能。
JBOF
的思考
和上篇的讨论一样,
PCIE
接口的
JBOF
的确不受待见。
Kalary
【
6
】,这个做众核的网络处理器的公司,也在讨论
40G/80G
的
JBOF
方案(因为是
ASIC
,
25G/100G
没
ready
,但是产品应该在路上)。
Newisys
【
7
】和
Kazan
合作的
JBOF
也是最近几年的明星。
Kazan
使用
FPGA
方案做
NVMeoF
方案,已经顺利拿到投资了。
JBOF
使用
PCIE
接口的确成本和代价过高。
100G
应该是大家公认的接口了。
100G RDMA
的当红厂家
Mellanox
【
8
】也是当仁不让提出了后
Biuefeild
的方案。在目前
Bluefeild
的方案中,数据流程必须走
CPU
的
DDR
。通过使用
SSD
的
CMB
,就是可以实现不过
HostMemory
的数据通路。
因此,是使用
NVMe SSD
控制器中的
CMB
,还是在
NVMe SSD
前面放一个
FPGA
,使用其中的
DRAM
来做
CMB
的功能,大家自己选择吧。
KVS on Flash
强势出击
Samsung
再次展示了他们的
KV SSD
【
9
】,
因此
Intel
毫不示弱,也推出了他们的
Hybrid
架构
HLKVDS
【
10
】,
和在
FMS
上用
NGSFF
对抗
ruler
一样,数据中心
Flash
市场的两大巨头,
正在
KVS
上布局,
RocksDB
真心热呀。
Intel
的一个讨论
index
的结构的
slide
真心不错。【
11
】。
3DXP
和
pmem
因为只有
Intel
一家,人家正在孤独求败,一个人的舞台,自己无聊,看客也无聊呀。因此不提也罢。
扩展阅读:《
SPDK实战、QoS延时验证:Intel Optane P4800X评测(5)
》
和
FMS
不一样,这个会上中国企业不多,呼唤中国的
SDS
企业呀。当然,如果能用
FPGA
的话,就更好了,那个谁谁谁,你懂的。。。
【1】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Storage_Architecture/Balakrishnan_Vijay_Low-Overhead_Flash_Disaggregation_via_NVMe-over-Fabrics.pdf
【2】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Storage_Architecture/Kong_LayWai_An_Effective_and_Efficient_Performance_Optimization_Method_by_Design_%26_Experiment.pdf
【3】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Storage_Architecture/Yang_Zie_Accelerate_block_service_built_on_Ceph_via_SPDK.pdf
【4】
https://www.snia.org/sites/default/files/SDC/2017/presentations/NVMe/Liu_Luse_Sudarikov_Yang_Accelerated_NVMe_over_Fabrics_Target_and_vHost_via_SPDK.pdf
【5】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Solid_State_Stor_NVM_PM_NVDIMM/Bates_Stephen_p2pmem_Enabling_PCIe_Peer-2-Peer_in_Linux.pdf
【6】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Storage_Architecture/Couvert_Patrice_Solving_NVMePCIe_Issues_with_NVMe-oF_with_a_Smart_IO_Processor.pdf
【7】
https://www.snia.org/sites/default/files/SDC/2017/presentations/General_Session/Newisys.pdf
【8】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Solid_State_Stor_NVM_PM_NVDIMM/Idan_BursteinEthernetStorageFabricsUsingRDMAwithFastNVMe-oFStorage.pdf
【9】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Object_Object_Drive_Stor/Ki_Yang_Seok_Key_Value_SSD_Explained_Concept_Device_System_and_Standard.pdf
【10】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Solid_State_Stor_NVM_PM_NVDIMM/Porter_Brien_A_New_Key-value_Data_Store_For_Heterogeneous_Storage_Architecture.pdf
【11】
https://www.snia.org/sites/default/files/SDC/2017/presentations/Storage_Architecture/Verma_Vishal_Gohad_Tushar_Workload_Analysis_of_Key-Value_Stores_on_Non-Volatile_Media.pdf
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
HL_Storage

长按二维码可直接识别关注
历史文章汇总
:
http://www.10tiao.com/author/index?authorId=691



