选自blog.insightdatascience
作者:
Javed Qadrud-Din
机器之心编译
参与:
Edison Ke、刘晓坤
来自 Insight 的 Javed Qadrud-Din 开源了一种通用的实体嵌入算法,相比谷歌的 word2vec 模型能实现更广泛实体(包括名人、商家、用户等)的嵌入、更高的准确率以及少 4 个数量级的数据需求量。
GitHub 链接:https://github.com/javedqadruddin/person2vec
Javed Qadrud-Din 先前曾在 IBM 公司的 Watson 团队担任业务架构师。他在 Insight 开发了一种新方法,使得企业能够将用户、客户和其他实体有效地表示,以便更好地理解、预测和服务他们。
企业通常需要了解、组织和预测他们的用户和合作伙伴。例如,预测哪些用户将离开平台(流失预警),或者识别不同类型的广告伙伴(集群)。这一任务的挑战性在于要用一种简洁而有意义的方式来表现这些实体,然后要将它们输入一个机器学习分类器,或者用其他方法进行分析。
灵感来自 NLP
最近,自然语言处理(NLP)领域最重要的进展之一是来自谷歌的一组研究人员(Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean)创建了 word2vec,这是一种将单词表示为连续向量的技术,这种连续向量称为「嵌入」(embeddings)。
他们在 1000 亿个单词(已开源)上训练出的嵌入,成功地捕捉到了它们所代表的单词的大部分语义含义。例如,你可以将「国王」的嵌入,减去「男人」的嵌入,再加上「女人」的嵌入,这些操作的结果会很接近「女王」的嵌入——这个结果说明谷歌团队设法编码人类文字含义的能力已经到了几乎令人毛骨悚然的程度。
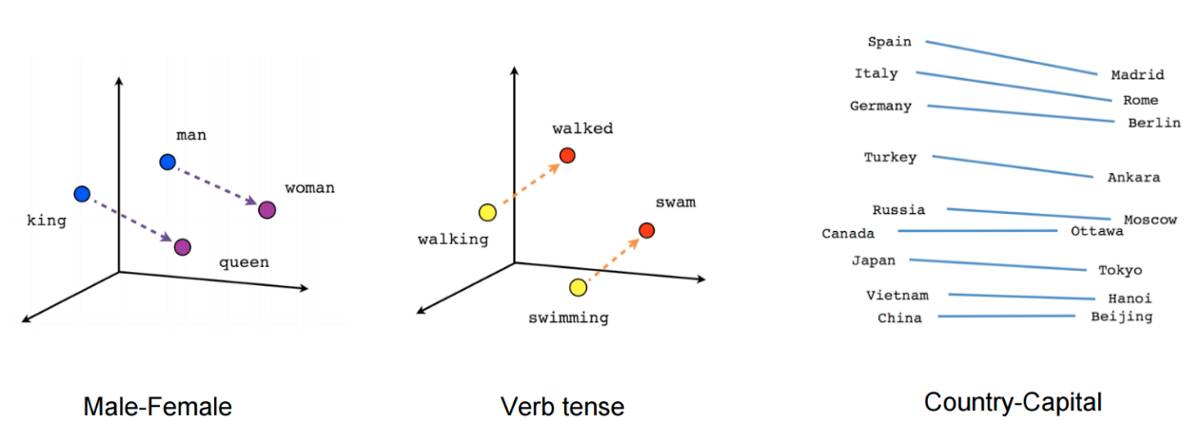
一些词嵌入的例子(Mikolov et. al.)
从那以后,word2vec 一直是自然语言处理的基本组成,为许多基于文本的应用程序(如分类、集群和翻译)提供了一个简单而高效的基础模块。我在 Insight 的时候有一个疑问是,类似于词汇内嵌的技术如何应用于其他类型的数据,比如人或企业。
关于嵌入
让我们首先来想想「嵌入」究竟是什么。在物理上,一个嵌入只是表示某个实体的数字列表(即一个向量)。对 word2vec 来说,这些实体就是英文单词。每一个单词拥有一个自己的数字列表。
通过训练任务过程中的梯度下降进行不断调整,这些数字列表被优化为它们所代表的实体的有用表示。如果训练任务要求记住有关对应实体的一般信息,那么嵌入将会最终吸收这些一般信息。
单词的嵌入
以 word2vec 为例,训练任务涉及提取一个单词(称为单词 A),并在一个巨大的文本语料库(来自谷歌新闻中的一千亿单词)中预测另一个单词(单词 B)出现在单词 A 的前后 10 个单词范围的窗口中的概率。
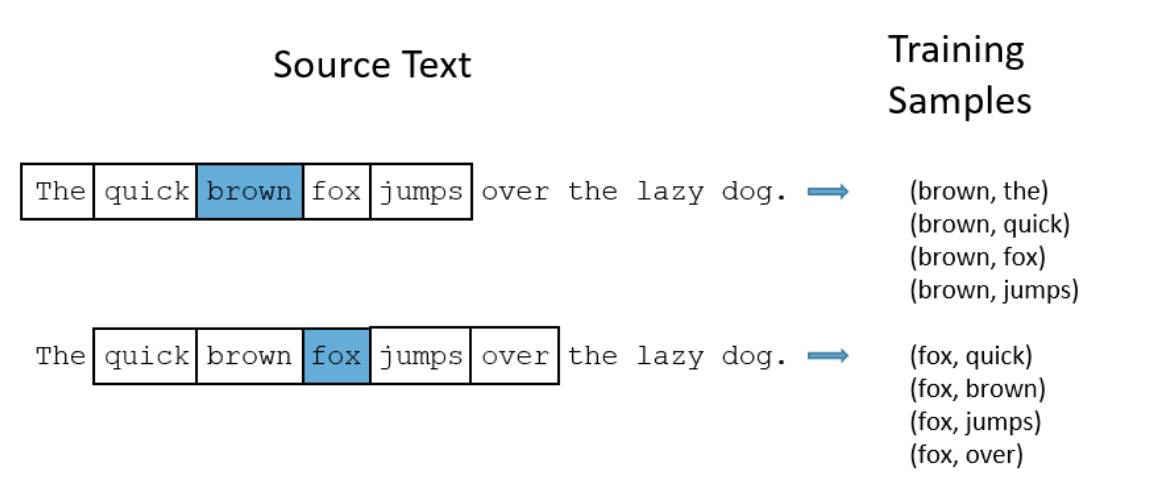
每一个单词在训练过程中都需要重复成千上万次预测,对应的单词 B 既包括通常一同出现的那些,也包括从不会出现在相同的语境中的那些(这叫做负采样技术)。
这个任务要求每个单词的嵌入编码与这个单词共同出现的其他单词的信息。与类似的单词一起出现的单词最终会有类似的嵌入。例如,「聪明(smart)」这个词和「有智慧(intelligent)」这个词经常可以互换使用,所以通常在一个大型语料库中,与这两个单词一起出现的那些单词集合是非常相似的。因此,「聪明」和「有智慧」的嵌入会非常相似。
用这个任务创建的嵌入被强制编码了很多关于这个单词的一般信息,所以在不相关的任务中,它们仍然可以用来代表对应的单词。谷歌 word2vec 嵌入广泛用于自然语言处理的各种应用程序,如情绪分析和文本分类。
还有其他团队使用不同的训练策略设计的单词嵌入。其中最流行的是 CloVe 和 CoVe。
任何东西的嵌入
单词向量是多种 NLP 任务的必要工具。但是,对于企业通常最关心的实体类型来说,预先训练的词向量并不存在。对于像「红色」和「香蕉」这样的单词,Google 已经为我们提供了预训练好的 word2vec 嵌入,但是并没有为我们提供诸如一个社交网络、本地企业或是其他没在 Google 新闻语料库中频繁出现的实体的嵌入。因为 word2vec 是基于 Google 新闻语料库进行训练的。
企业关心的是他们的客户、他们的雇员、他们的供应商,以及其他没有预先训练的嵌入的实体。一旦经过训练,实体的矢量化表示就可以用以输入大量机器学习模型。例如,他们可以用在预测用户可能会点击哪些广告的模型上,可以用在预测哪些大学申请者很可能以优异的成绩毕业的模型上,或者用在预测哪个政客有可能赢得选举的模型上。
实体嵌入使我们能够利用与这些实体相关联的自然语言文本来完成这些类型的任务,而这类文本往往是企业手中一直保存着的。例如,我们可以通过一个用户写的帖子,一个大学申请人写的个人陈述,或者人们关于一个政治家的推特和博客帖子来生成实体嵌入。





