(点击上方公众号,可快速关注)
英文:lucidchart,翻译:伯乐在线 - 王浩
如有好文章投稿,请点击 → 这里了解详情
我们公司有个面向服务的架构。其中一个服务是字体服务,字体体系和 unicode 编码范围(unicode range)提供字体数据,为用户上传的字体验证权限。我们没想到这个字体服务会有很高的负载1(负载是指线程消耗和 CPU 等待的平均值)。但是去年我们注意到字体服务出人意料地出现高负载,尤其是晚上我们没什么流量的时候。幸运的是,我们发现了这一问题的根本原因,并大幅提升了字体服务的性能和系统整体的稳定性。以下内容是我们的优化过程。
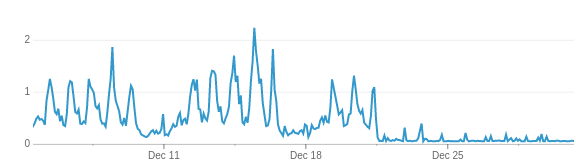 图1:修改前后系统复制(12 月 21 日发布修复版本)
图1:修改前后系统复制(12 月 21 日发布修复版本)
用火焰图调试
我一个同事从 Netflix 公司的 Brendan Gregg 那里发现并部署了一个小巧的火焰图工具。这个工具可以把多个性能检测工具的数据结合起来,生成一张本地方法和 JVM 方法资源使用情况的图象。图里每一个矩形都代表一个栈帧,矩形的宽度代表资源的使用情况,如 CPU 时间,y 轴代表调用栈。你可以简单地通过找出比较宽的矩形来定位出问题所在。这个工具对于调试字体服务的性能是非常宝贵的。
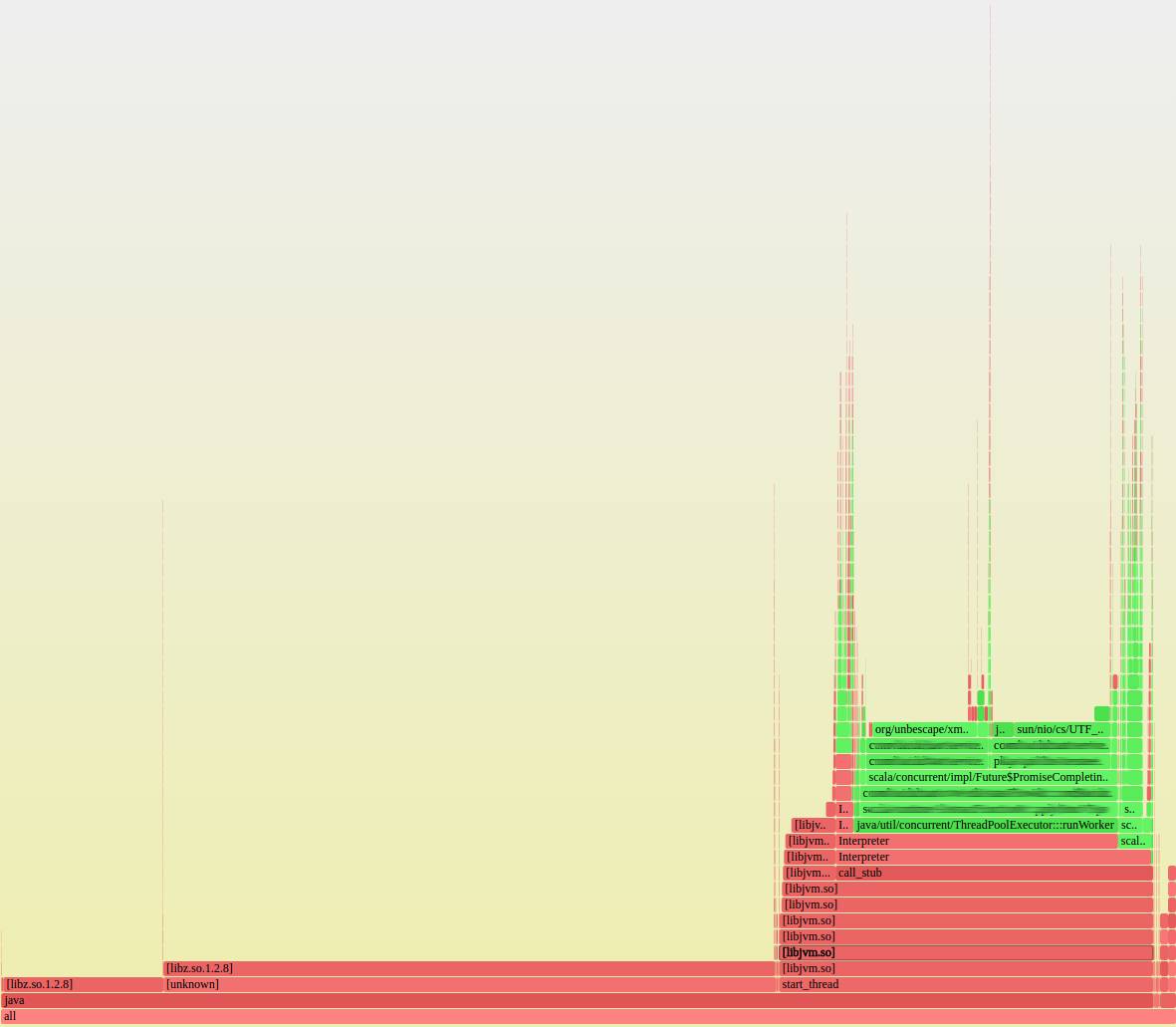
图2:字体服务器高负载情况下的一张火焰图
我们收集了几张字体服务高负载状态下的火焰图。下面展示了其中一张,图里有一处 JVM 部分几乎到顶。我们很快注意到这些图的规律。绝大部分时间都是消耗在 libz.so(用于 gzip 压缩和解压)上,而 JVM 里的绝大部分时间都是消耗在 XML 转义和 UTF-8 编码上。
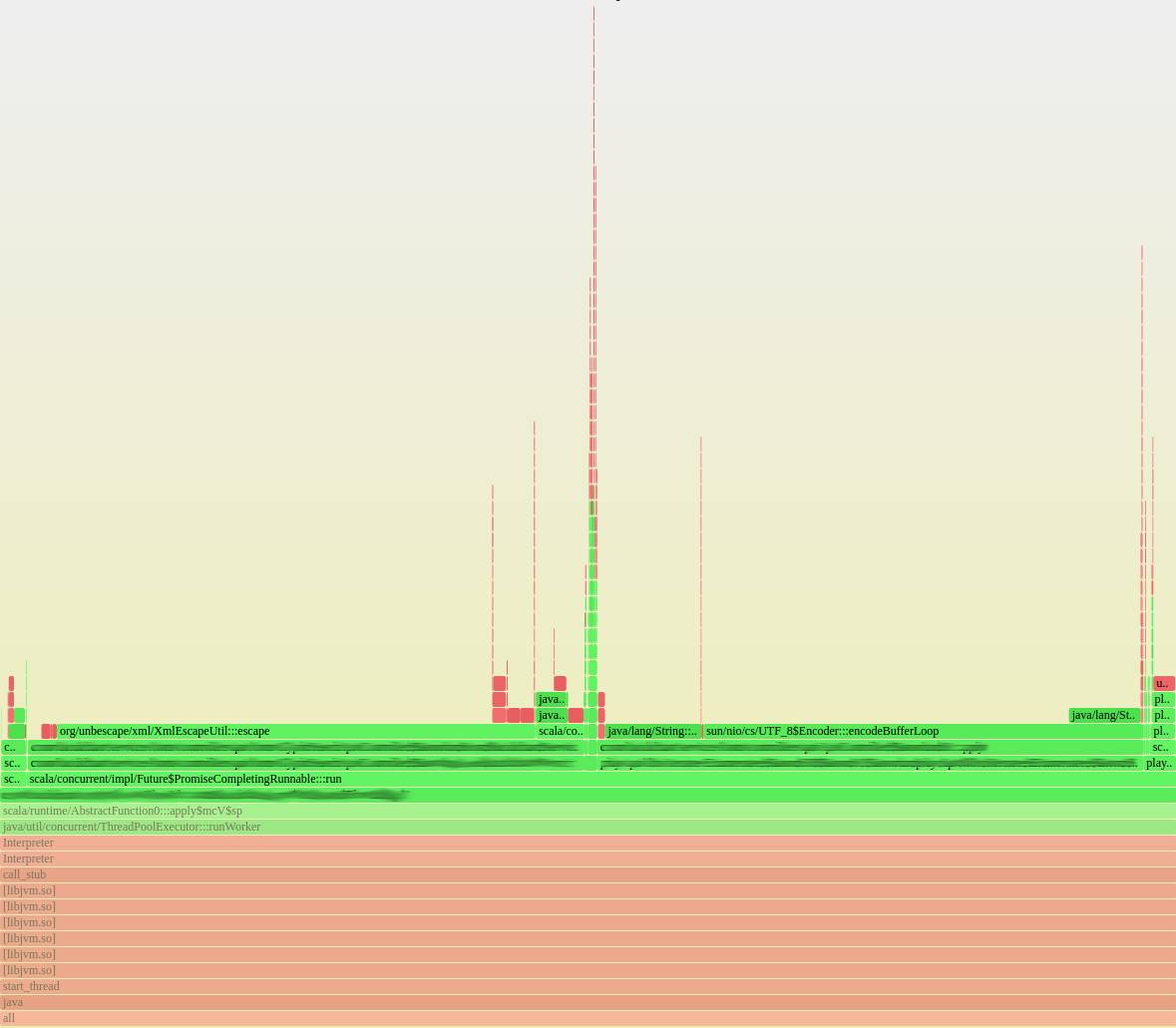
图3:在 JVM 部分放大的火焰图
为什么这么慢
首先,介绍一点关于我们字体服务如何工作的背景。我们将字体数据保存在 Amazon S3 容器中,每一种字体的每一 unicode 编码范围(unicode range)是一个独立的对象。其他服务会为字体体系、一系列 unicode 编码范围(unicode range)或者用户来请求字体数据。字体服务会下载用户请求的字体体系中特定 unicode 编码范围(unicode range)的数据,并返回包含这所有数据的 XML。
这一功能非常简单,并没有什么明显密集计算的东西。然而,我们遇到了高负载。我们在火焰图的帮助下发现 libz、XML 转义和 UTF8 编码占用了 CPU 大量资源。但是为什么我们花了这么多时间在编码和压缩上呢?记得我刚才说的,晚上负载最高吗?我们的晚上(美国山区标准时)在亚洲是白天。每当晚上我们本地没什么流量的时候,大量其他地区的用户正在用亚洲语言的 unicode 编码范围(unicode range),比如中文、日语和韩语。事实上,相比起来这些类别的字体数据是非常庞大的。这些数据通过 gzip 解压、UTF-8 解码然后 XML 转义、UTF-8 编码最后 gzip 压缩。对于体积很小的基本拉丁文类别,这一过程没什么。然而,CJK 类别比基本拉丁文类别大了两个数量级(1MB 对比 60KB)。对于这些体积大的字体类别,这所有的转换都使得 CPU 吃不消。Gzip 压缩和解压相对很耗资源,XML 转义也没有那么快。
怎样加速
字体服务响应的内容本质上只是来自 S3 的原始数据。字体服务的确做了其他重要的工作,比如权限验证,查找字体关键字。但是没有理由必须让字体服务从 S3 转发字体数据。我们的解决方案非常简单粗暴,直接返回一系列包含字体数据的 S3 对象的链接,而不是通过字体服务下载然后重新编码字体数据。
这一修改几乎将字体服务器的负载降为 0(见图1)。客户端服务器也察觉不到任何影响。尽管我们第一次尝试非常成功,但我也应该记住,我们部署的同时增加了功能发布控制,它可以让我们在 100% 启用前,先启用一定比例的请求来测试它能够正常工作。
结论
通过对生产环境服务器的监控,我们能够定位并删除服务器上没必要的功能。下面是我们这次经历中几个关键的步骤:
用火焰图等性能检测工具定位那些霸占 CPU 的功能方法。
压缩和其他编码也会非常耗资源。
如果客户端能够直接获取到数据,那么直接发给它一个连接而非转发数据会提升整体的性能。(声明:这并不是灵丹妙药,有些情况下会对客户端性能造成损失,因为它必须要做二次请求)。
#1: 负载是指线程消耗和 CPU 等待的平均值。
看完本文有收获?请转发分享给更多人
关注「数据库开发」,提升 DB 技能











