我们是一家做生鲜电商的公司,从系统搭建初期,我们就采用微服务的架构,基于DevOps体系来不断提高我们的交付的质量和效率, 随着业务和团队规模的发展,服务逐渐进行拆分,服务之间的交互越来越复杂,目前整个微服务已经近几十个应用模块, 整体架构上包括负载均衡、API网关、基于Dubbo的微服务模块、缓存、队列、数据库等,目前整个集群的资源利用率也没有一个合理的规划评估,虚拟机上部署多个应用服务隔离性也存在问题,考虑到越来越多门店以及第三方流量的接入,需要考虑系统的快速的伸缩能力,而基于统一资源管理的Docker容器技术在这些方面有一些天然的优势,并且和微服务架构、DevOps体系完美衔接。
经过调研和对比,最终我们采用Mesos作为底层资源的管理和调度,Marathon作为Docker执行的框架,配合ZooKeeper、Consul、Nginx作为服务注册发现。目前已经有部分的核心业务已经平稳的运行在基于Docker容器的Mesos资源管理平台上。
部署架构

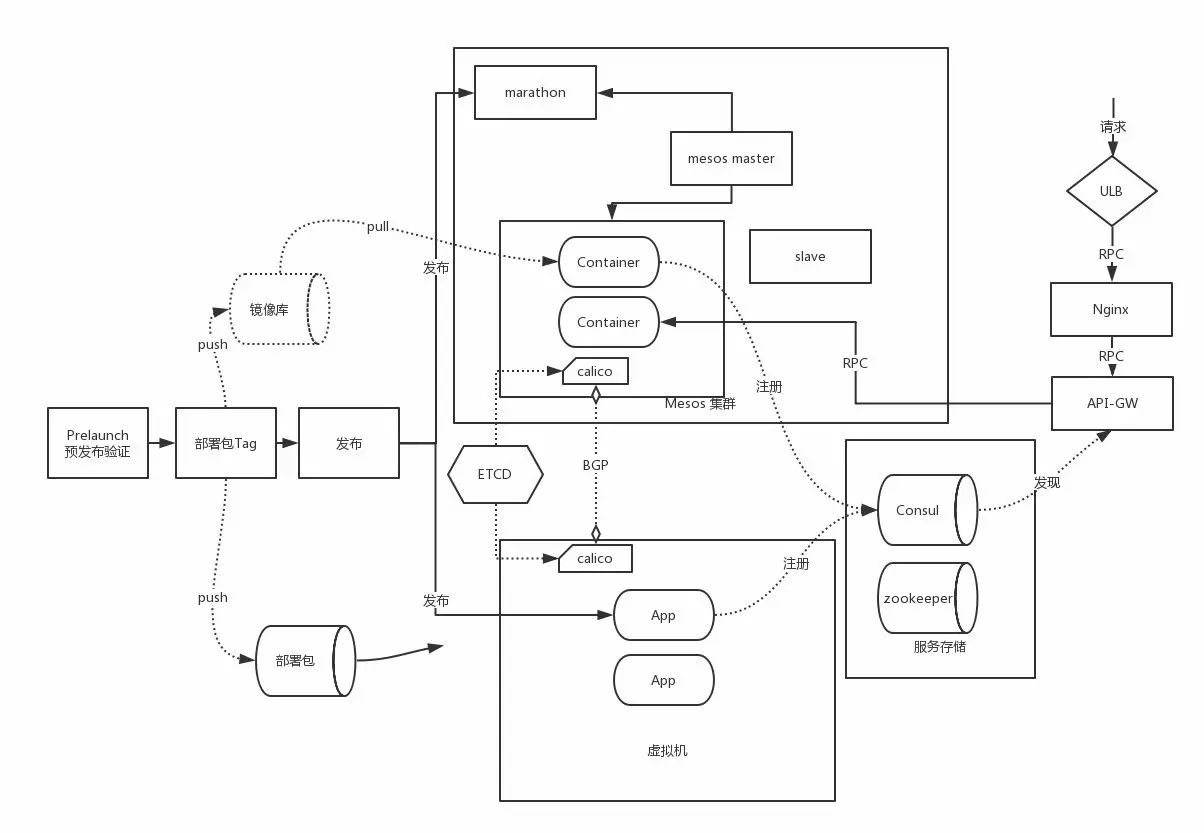
在发布流程中,在发布上线之前的环节是预发布,预发布环境验证完成后进行打包,生成Docker镜像和基于虚拟机部署的应用部署包,push到各自对应的仓库中,并打Tag。
生产环境发布过程中,同时发布到Mesos集群和原有的虚拟机集群上,两套集群网络是打通的。
在网络架构选型时,会考虑一下几个原则:
一容器一IP
多主机容器互联,主机和容器互联
网络隔离、细粒度的ACL
性能损耗低
docker bridge使用默认的docker0网桥,容器有独立的网络命名空间,跨主机的容器通信需要做端口NAT映射;Host的方式采用和宿主机一样的网络命名空间,网络无法做隔离,等等这些方式有非常多的端口争用限制,效率也较低。
Docker Overlay的方式,可以解决跨主机的通信,现有二层或三层网络之上再构建起来一个独立的网络,这个网络通常会有自己独立的IP地址空间、交换或者路由的实现。
Docker在1.9中libnetwork团队提供了multi-host网络功能,能完成Overlay网络,主要有隧道和路由两种方式, 隧道原理是对基础的网络协议进行封包,代表是Flannel。
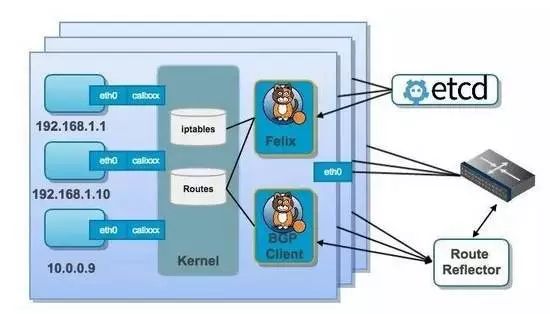
另外一种是在宿主机中实现路由配置实现跨宿主机的容器之间的通信,比如Calico。
Calico是基于大三层的BGP协议路由方案,没有使用封包的隧道,没有NAT,性能的损耗很小,支持安全隔离防护,支持很细致的ACL控制,对混合云亲和度比较高。经过综合对比考虑,我们采用calico来实现跨宿主机的网络通讯。
安装好ETCD集群,通过负载均衡VIP方式(LVS+keepalived)来访问ETCD集群。
ETCD_AUTHORITY=10.10.195.193:2379
export ETCD_AUTHORITY
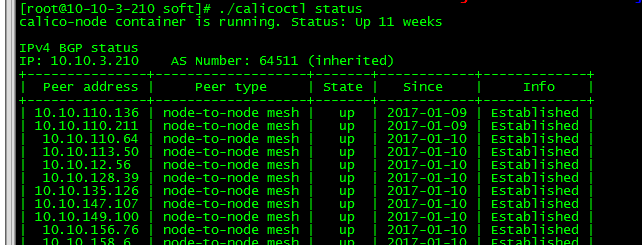
构建Calico网络集群,增加当前节点到集群中,Calico 节点启动后会查询 Etcd,和其他 Calico 节点使用 BGP 协议建立连接。
./calicoctl node –libnetwork –ip=10.10.3.210
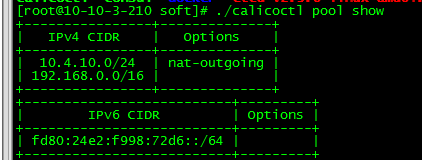
增加可用的地址池ip pool
./calicoctl pool add 10.4.10.0/24 –nat-outgoing
./calicoctl pool show
创建网络,通过Calico IPAM插件(Driver(包括IPAM)负责一个Network的管理,包括资源分配和回收),-d指定驱动类型为Calico,创建一个online_net的driver为Calico的网络:
docker network create -d calico –ipam-driver calico –subnet=10.4.10.0/24 online_net
启动容器,网络指定刚才创建的online_net,容器启动时,劫持相关 Docker API,进行网络初始化。 查询 Etcd 自动分配一个可用 IP,创建一对veth接口用于容器和主机间通讯,设置好容器内的 IP 后,打开 IP 转发,在主机路由表添加指向此接口的路由,宿主机10.10.3.210的路由表:

宿主机10.10.50.145的路由表:


容器包发送包的路由过程如上图,宿主机10.10.3.210上的容器IP 10.4.10.64通过路由表发送数据包给另外一个宿主机10.10.50.145的容器10.4.10.55。
对于有状态的数据库,缓存等还是用物理机(虚拟机),来的应用集群用的是虚拟机,Docker容器集群需要和它们打通,做服务和数据的访问交互。那么只需要在物理机(虚拟机)上把当前节点加入容器网络集群即可:
ETCD_AUTHORITY=10.10.195.193:2379
export ETCD_AUTHORITY
./calicoctl node –ip=10.10.16.201
API网关提供统一的API访问入口,分为两层,第一层提供统一的路由、流控、安全鉴权、WAF、灰度功能发布等功能,第二层是Web应用层,通过调用Dubbo服务来实现服务的编排,对外提供网关的编排服务功能,屏蔽业务服务接口的变更;为了能够快速无缝的实现web层快速接入和扩容,我们用Consul作为服务注册中心实现Web服务的自动注册和发现。
对于Web服务注册,我们自己实现了Register,调用Consul的API进行注册,并通过TTL机制,定期进行心跳汇报应用的健康状态。
对于Web服务的发现,我们基于Netflix Zuul进行了扩展和改造,路由方面整合Consul的发现机制,并增加了基于域名进行路由的方式,对路由的配置功能进行了增强,实现配置的动态reload功能。API网关启动定时任务,通过Consul API获取Web服务实例的健康状态,更新本地的路由缓存,实现动态路由功能。
平台的微服务框架是基于Dubbo RPC实现的,而Dubbo依赖ZooKeeper做服务的发现和注册。
Consul在Mesos Docker集群的部署方案:
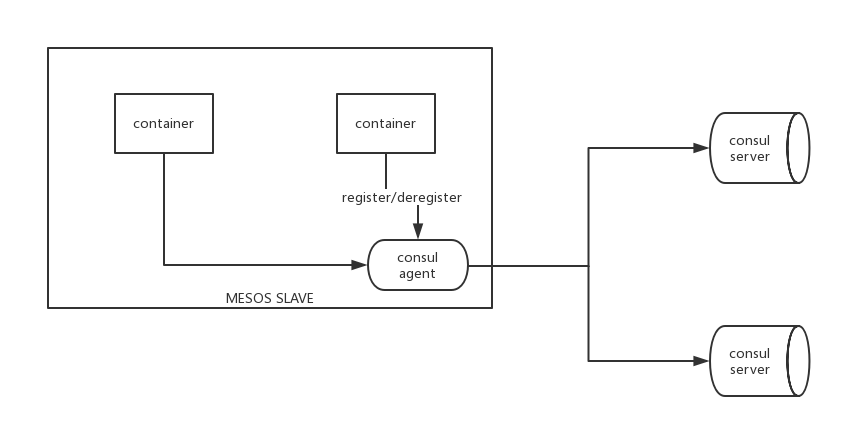
不建议把Consul Agent都和Container应用打包成一个镜像,因此Consul Agent部署在每个Mesos Slave宿主机上,那么Container如何获取宿主机的IP地址来进行服务的注册和注销,容器启动过程中,默认情况下,会把当前宿主机IP作为环境变量传递到Container中,这样容器应用的Register模块就可以获取Consul代理的IP,调用Consul的API进行服务的注册和卸载。
在日常应用发布中,需要保障发布过程对在线业务没有影响,做到无缝滚动的发布,那么在停止应用时应通知到路由,进行流量切换。
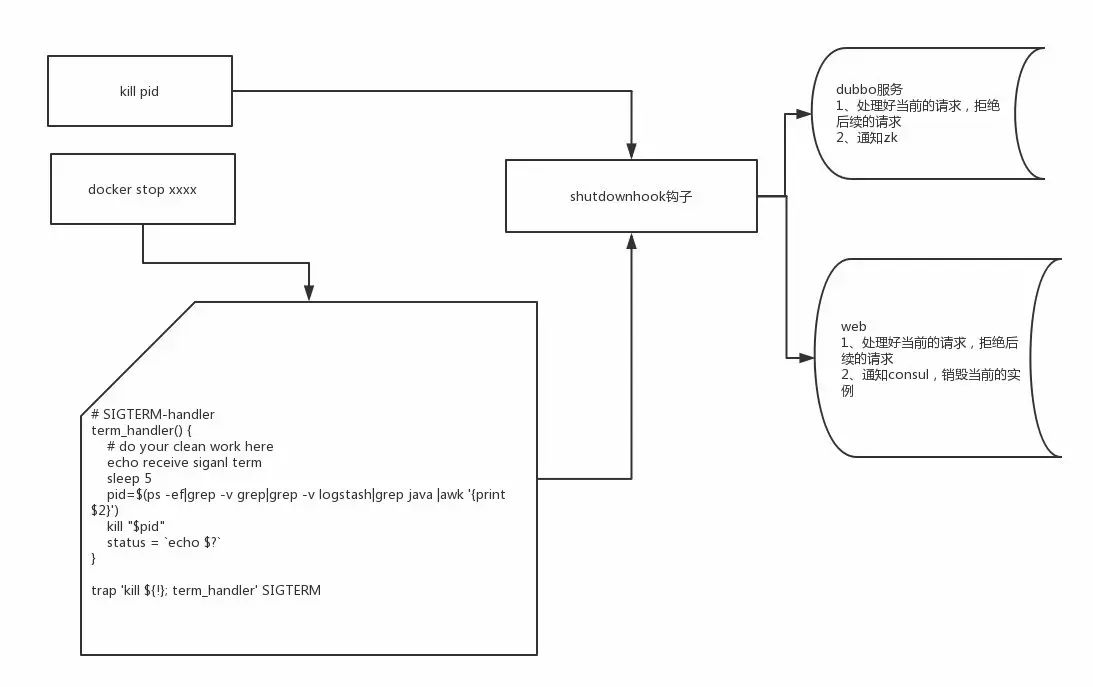
docker stop命令在执行的时候,会先向容器中PID为1的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认的10秒,会继续发送SIGKILL的系统信号强行kill掉进程。这样我们可以让程序在接收到SIGTERM信号后,有一定的时间处理、保存程序执行现场,优雅的退出程序,我们在应用的启动脚本中实现一段脚本来实现信号的接受和处理, 接收到信号后,找到应用的PID,做应用进程的平滑kill。见上面图中的脚本。
Marathon为运行中的应用提供了灵活的重启策略。当应用只有一个实例在运行,这时候重启的话,默认情况下Marathon会新起一个实例,在新实例重启完成之后,才会停掉原有实例,从而实现平滑的重启,满足应用无缝滚动发布的要求。
当然,可以通过Marathon提供的参数来设置自己想要的重启策略:
“upgradeStrategy”:{ “minimumHealthCapacity”: N1, “maximumOverCapacity”: N2 }
如何判断新的实例是否启动完成可以提供服务,或者当前容器的应用实例是否健康,是否实例已经不可用了需要恢复,Marathon提供了healthchecks健康监测模块
"healthChecks": [{
"protocol": "COMMAND",
"command":{
"value":"sh /data/soft/healthcheck.sh app 10.10.195.193"
},
"gracePeriodSeconds": 90,
"intervalSeconds": 60,
"timeoutSeconds": 50,
"maxConsecutiveFailures": 3
}]
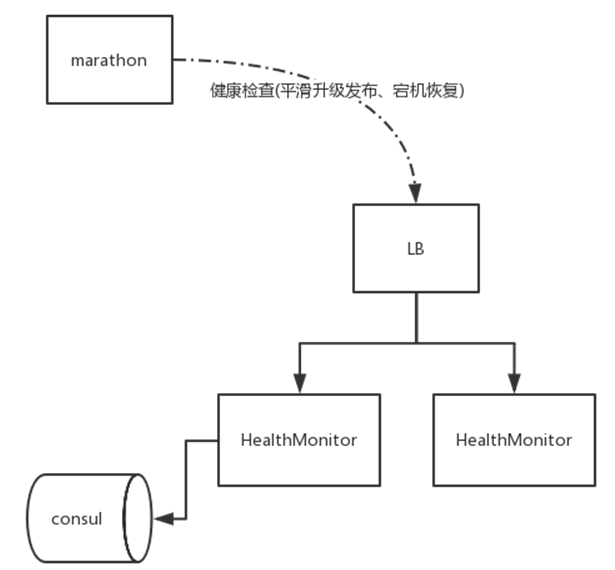
healthcheck.sh通过负载均衡调用HealthMonitor来获取应用实例的监控状态, HealthMonitor是我们的健康检查中心,可以获取应用实例的整个拓扑信息。
下图是我们的整体平台监控的体系架构。
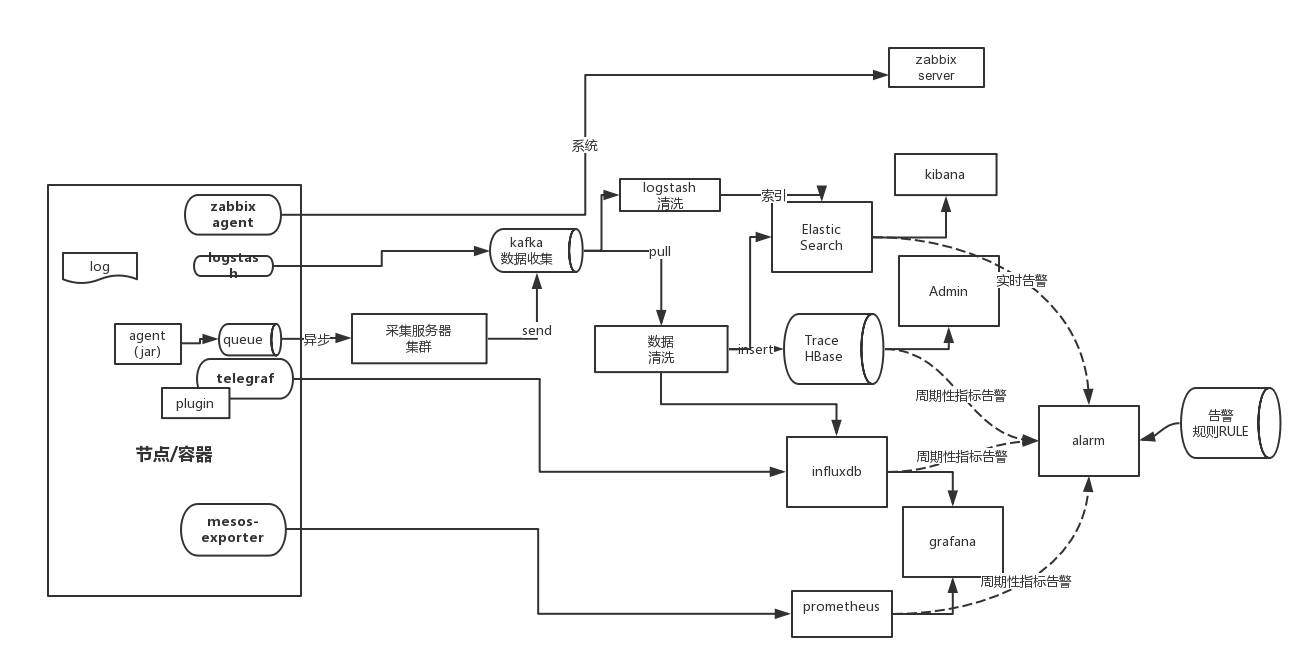
监控平台涵盖了系统各个层面的指标体系,这块后续单独列章节详细介绍。
对于容器的监控,由于我们是采用Mesos Docker的容器资源管理的架构,因此采用mesos-exporter+Prometheus+Grafana的监控方案,mesos-exporter的特点是可以采集 task 的监控数据,可以从task的角度来了解资源的使用情况,而不是一个一个没有关联关系的容器。mesos-exporter导出Mesos集群的监控数据到Prometheus,Prometheus是一套监控报警、时序数据库组合,提供了非常强大存储和多维度的查询,数据的展现统一采用Grafana。
作者微信:yangbt_6225080





