 「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
论文作者 | 丁延卓、刘洋、栾焕博、孙茂松(清华大学)
特约记者 | 吴郦军(中山大学)
如果有一个功能神奇的“黑箱子”,你想不想打开它,好好研究一番?神经机器翻译就是这么一个“黑盒”,只要给它一句中文,就能将对应的英文顺利地翻译出来,如何才能一探其中的究竟呢?清华大学的丁延卓同学、刘洋老师、栾焕博老师和孙茂松老师在今年 ACL2017 上的工作就将这其中的奥秘“画给你看”。
近年来,深度学习快速发展,神经机器翻译(Neural Machine Translation)方法已经取得了比传统的统计机器翻译(Statistical Machine Translation)更为准确的翻译结果。可是,深度学习这样的复杂而又庞大的网络模型,就像一个摸不清的“黑箱子”,网络中只有浮点数的传递,到底背后包含着怎样的语义、逻辑,一直困扰着研究人员对于神经机器翻译的深入理解和分析。因此,如果能够将网络可视化,找到网络中神经元之间的相关关系,将极大帮助人们探究神经机器翻译中出现的各类错误,同时也能帮助指导如何调试更好的模型。
而就在今年的 ACL2017 上,清华大学的丁延卓同学、刘洋老师、栾焕博老师和孙茂松老师发表了论文“Visualizing and Understanding Neural Machine Translation”,借鉴视觉领域中的研究,首次将计算机视觉中 layer-wise relevance propagation(LRP)的方法引入到神经机器翻译中,为注意力机制(attention mechanism)的编码-解码(encoder-decoder)神经机器翻译模型提供了可视化以及可解释性的可能。通过分析层与层之间的相关性,将这些关系“画”了出来。“据我们所知,目前还没有工作是在神经机器翻译模型的可视化上。”作者告诉我们,现有的注意力机制被限制在只能证明源语言(source language)和目标语言(target language)之间存在关系,却不能提供更多的信息来帮助了解目标语言的词语是如何一步一步生成的;而相关性分析则能够帮助理解这个过程,并且能够分析任意神经元之间的关系。
Layer-wise relevance propagation(LRP)的方法到底是什么呢?其实就是一个计算相关性,并将相关性逐层向后传播的过程。首先将网络模型看成一个拓扑图结构,在计算一个节点 a 和输入的节点之间的相关性时,将 a 点的数值作为相关性,并且计算与 a 点相连的上一层节点在生成 a 点时所占的权重,将 a 的相关性逐层向后传播,直到输入层。作者用下图的例子告诉了我们:
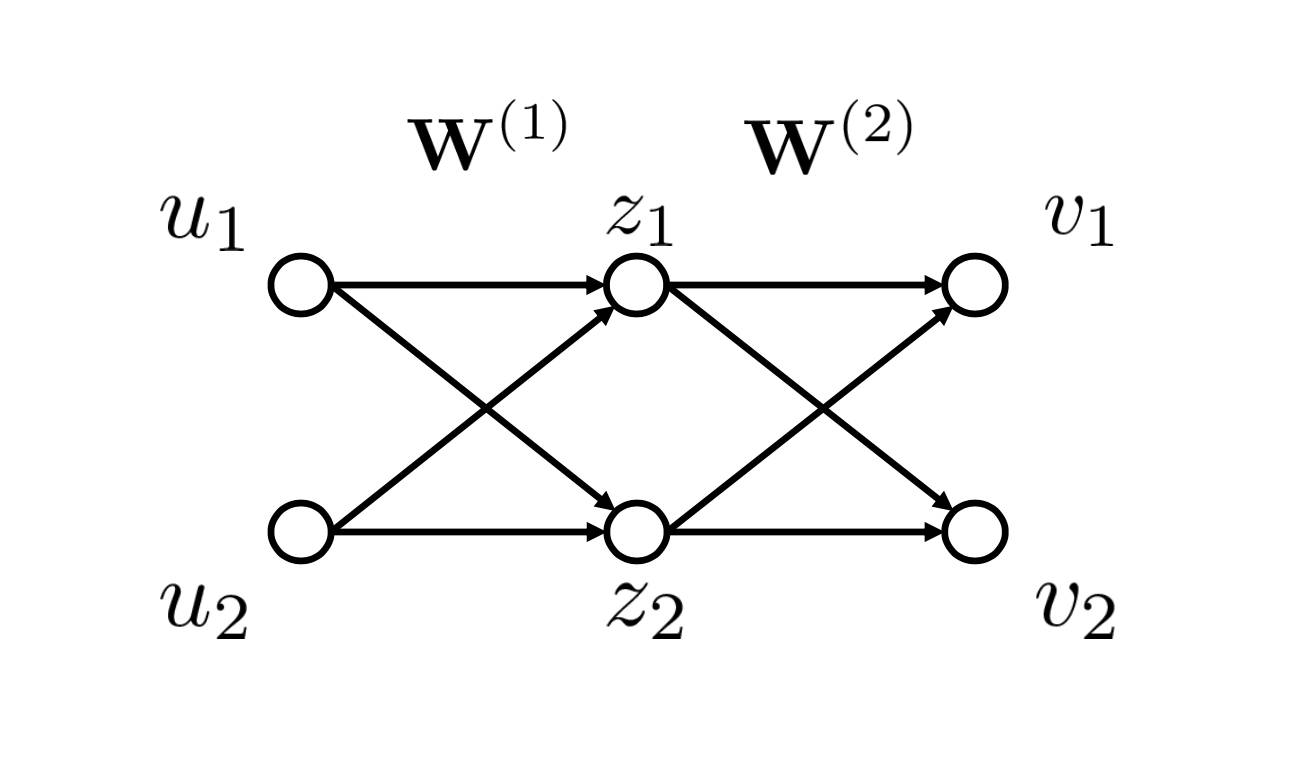
▲ 图1:Layer-wise Relevance Propagation 示例
如果要计算 v1 和 u1 之间的相关性,首先计算 v1 和 z1, z2 之间的相关性,再将 v1 和z1, z2 的相关性传递到 u1, 从而求得 v1 和 u1 之间的相关性。
通过这样的计算,我们最终能“画”出怎样的相关性呢?让我们来几个例子(颜色越深表示相关性越强):
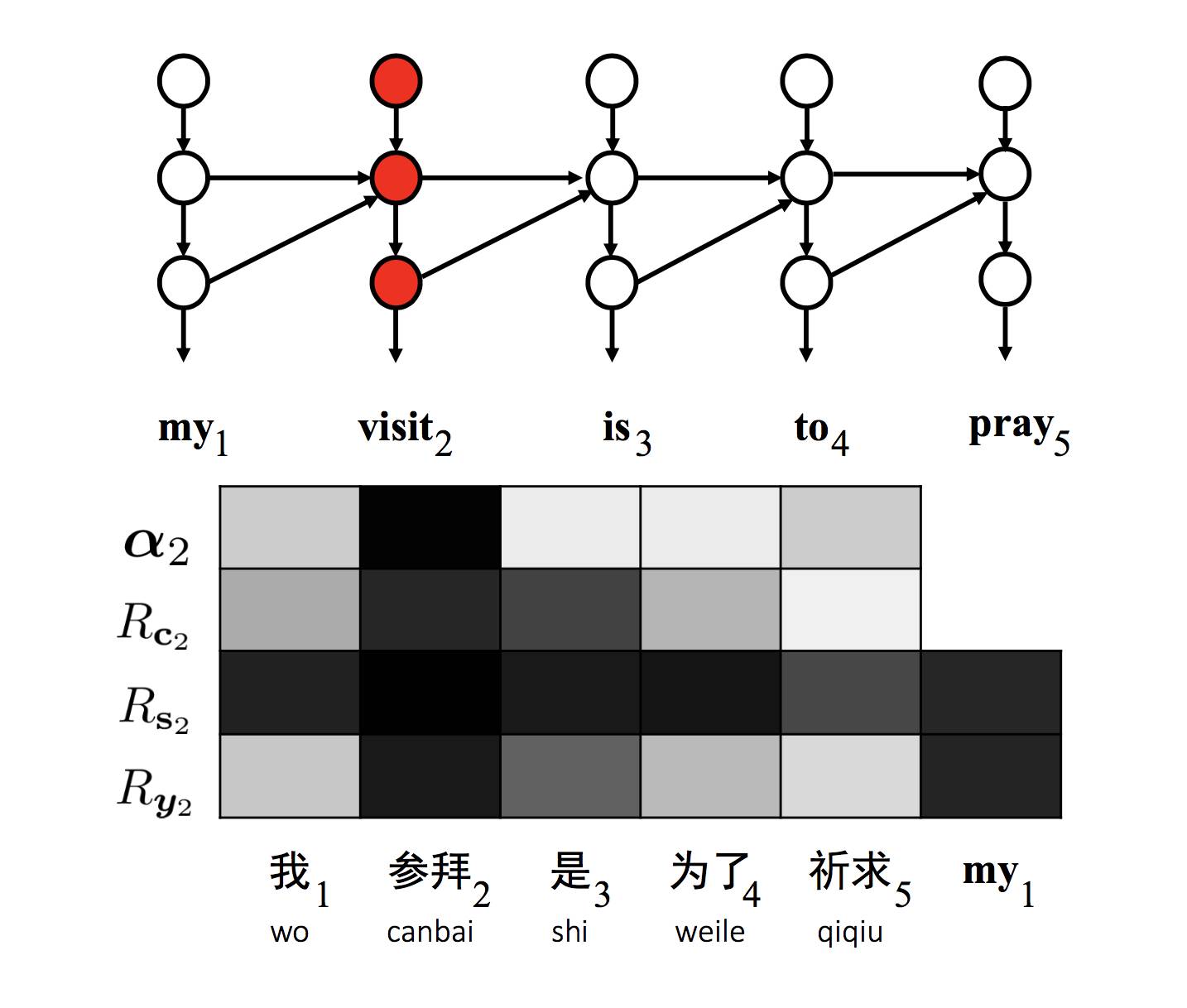
▲ 图2:目标语言单词"visit"对应的隐变量可视化图
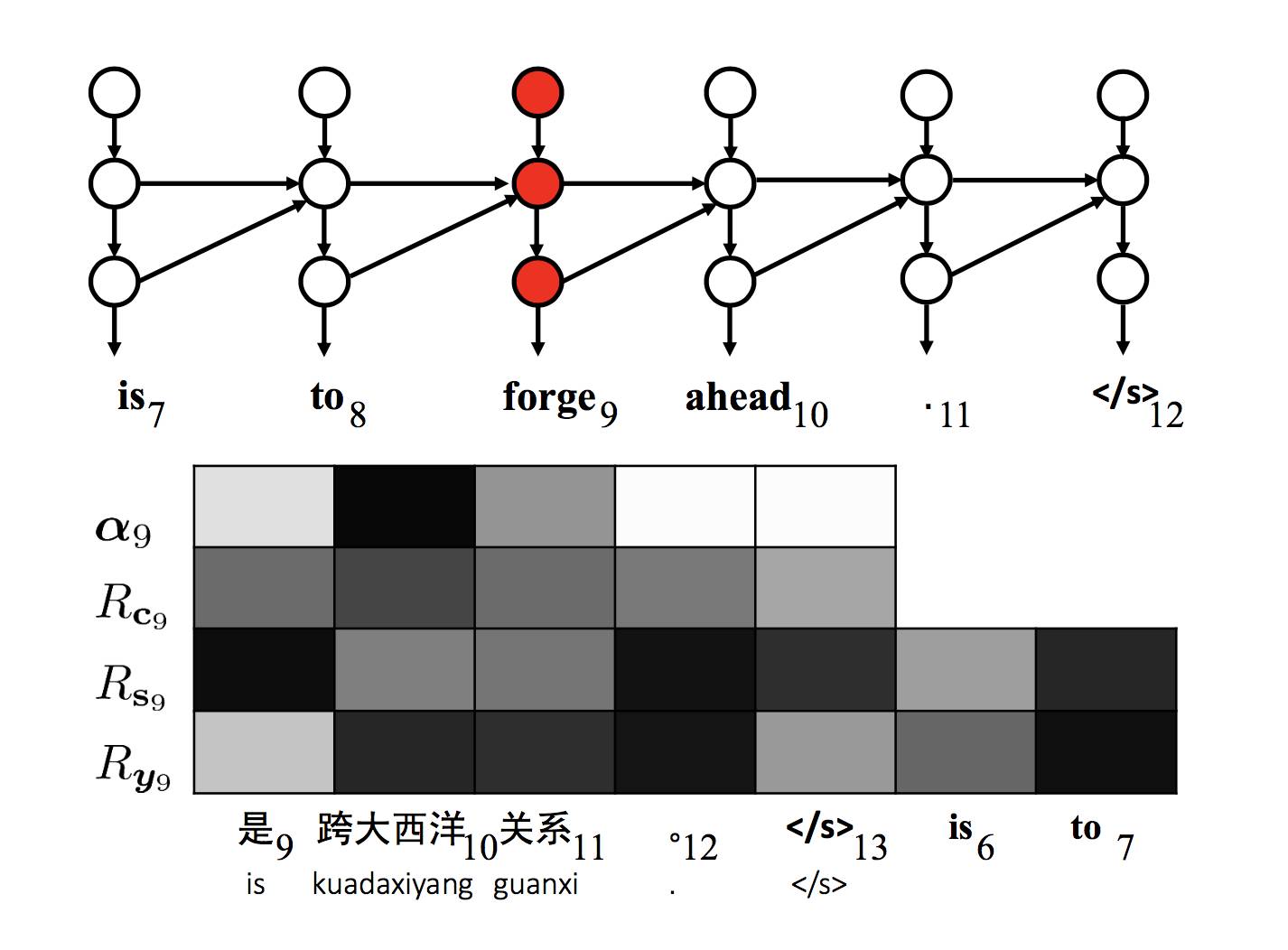
▲ 图3:错误分析:不相关词语"forge"与源句子完全不相关
图 2 是在翻译“我参拜是为了祈求”时中间的隐层 c2, s2 以及输出层 y2 和输入句子词语之间的相关性,可以看到“visit”这个词语正确的和“参拜”以及“my”的相关性更为强烈,因而正确的翻译出了词语“visit”;而图 3 则表明“forge”(锻造)这个词语的隐层 c9, s9 和输入的词语都没有正确的相关性并且跳跃,而在生成时 y9 也没有和输入有正确的相关性。
“通过对翻译中出现的不同错误的相关性的可视化的观察,我们的方法能够帮助模型进行改造和更好的调试。”作者告诉我们,在将 LRP 的方法引入时其实也遇到了一些难点,比如图像领域只是输入图像像素点,而机器翻译中则是一串词语,每个词语都对应着一个长度或百或千的向量,对于计算相关性造成了困难;同时模型复杂,包含各种不同的计算算子。而通过仔细地设计计算方法以及 GPU 的利用,也将困难一个个克服了。
“未来,我们希望将方法用于更多不同的神经机器翻译模型中,另外也希望构建基于相关性分析的更好的神经机器翻译模型。”对于未来的研究工作,他们也更为期待。
欢迎点击「阅读原文」查看论文:
Visualizing and Understanding Neural Machine Translation
关于中国中文信息学会青工委
中国中文信息学会青年工作委员会是中国中文信息学会的下属学术组织,专门面向全国中文信息处理领域的青年学者和学生开展工作。

关于PaperWeekly
PaperWeekly是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事AI领域,欢迎在公众号后台点击
「交流群」
,小助手将把你带入PaperWeekly的交流群里。






