AI芯片作为产业核心,也是技术要求和附加值最高的环节,在AI产业链中的产业价值和战略地位远远大于应用层创新。腾讯发布的《中美两国人工智能产业发展全面解读》报告显示,基础层的处理器/芯片企业数量来看,中国有14家,美国33家。本文将对这一领域产业生态做一个简单梳理。

AI芯片分类
Training
环节
通常需要通过大量的数据输入,或采取增强学习等非监督学习方法,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据和复杂的深度神经网络结构,运算量巨大,需要庞大的计算规模,对于处理器的计算能力、精度、可扩展性等性能要求很高。目前在训练环节主要使用
NVIDIA
的
GPU
集群来完成,
Google
自主研发的
ASIC
芯片
TPU2.0
也支持训练环节的深度网络加速。
Inference
环节
指利用训练好的模型,使用新的数据去“推理”出各种结论,如视频监控设备通过后台的深度神经网络模型,判断一张抓拍到的人脸是否属于黑名单。虽然
Inference
的计算量相比
Training
少很多,但仍然涉及大量的矩阵运算。在推理环节,
GPU
、
FPGA
和
ASIC
都有很多应用价值。
在深度学习的
Training
阶段,由于对数据量及运算量需求巨大,单一处理器几乎不可能独立完成一个模型的训练过程,因此,
Training
环节目前只能在云端实现,在设备端做
Training
目前还不是很明确的需求
。
在Inference阶段,由于目前训练出来的深度神经网络模型大多仍非常复杂,其推理过程仍然是计算密集型和存储密集型的,若部署到资源有限的终端用户设备上难度很大,因此,云端推理目前在人工智能应用中需求更为明显。GPU、FPGA、ASIC(Google TPU1.0/2.0)等都已应用于云端Inference环境。在设备端Inference领域,由于智能终端数量庞大且需求差异较大,如ADAS、VR等设备对实时性要求很高,推理过程不能交由云端完成,要求终端设备本身需要具备足够的推理计算能力,因此一些低功耗、低延迟、低成本的专用芯片也会有很大的市场需求。
按照上述两种分类,我们得出AI芯片分类象限如下图所示。

除了按照功能场景划分外,
AI
芯片从技术架构发展来看,大致也可以分为四个类型:
-
通用类芯片,代表如GPU、FPGA;
-
基于FPGA的半定制化芯片,代表如深鉴科技DPU、百度XPU等;
-
全定制化ASIC芯片,代表如TPU、寒武纪 Cambricon-1A等;
-
类脑计算芯片,代表如IBM TrueNorth、westwell、高通Zeroth等。

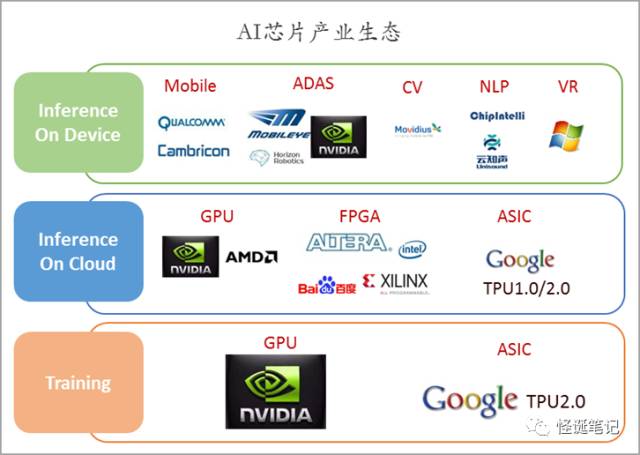
AI芯片产业生态
从上述分类象限来看,目前
AI
芯片的市场需求主要是三类:
-
面向于各大人工智能企业及实验室研发阶段的
Training
需求
(主要是云端,设备端
Training
需求尚不明确);
-
Inference On Cloud
,
Face++
、出门问问、
Siri
等主流人工智能应用均通过云端提供服务;
-
Inference On Device
,面向智能手机、智能摄像头、机器人
/
无人机、自动驾驶、
VR
等设备的设备端推理市场,需要高度定制化、低功耗的
AI
芯片产品。如华为麒麟
970
搭载了“神经网络处理单元(
NPU
,实际为寒武纪的
IP)
”、苹果
A11
搭载了“神经网络引擎(
Neural Engine)
”。
(一)Training训练
2007
年以前,人工智能研究受限于当时算法、数据等因素,对于芯片并没有特别强烈的需求,通用的
CPU
芯片即可提供足够的计算能力。
Andrew Ng
和
Jeff Dean
打造的
Google Brain
项目,使用包含
16000
个
CPU
核的并行计算平台,训练超过
10
亿个神经元的深度神经网络。但
CPU
的串行结构并不适用于深度学习所需的海量数据运算需求,用
CPU
做深度学习训练效率很低,在早期使用深度学习算法进行语音识别的模型中,拥有
429
个神经元的输入层,整个网络拥有
156M
个参数,训练时间超过
75
天。
与CPU少量的逻辑运算单元相比,GPU整个就是一个庞大的计算矩阵,GPU具有数以千计的计算核心、可实现10-100倍应用吞吐量,而且它还支持对深度学习至关重要的并行计算能力,可以比传统处理器更加快速,大大加快了训练过程。
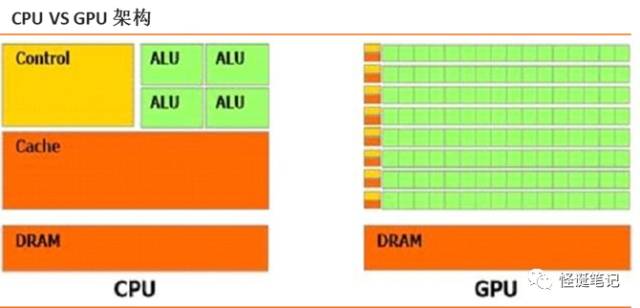
从上图对比来看,在内部结构上,
CPU
中
70%
晶体管都是用来构建
Cache(
高速缓冲存储器)和一部分控制单元,负责逻辑运算的部分(
ALU
模块)并不多,指令执行是一条接一条的串行过程。
GPU
由并行计算单元和控制单元以及存储单元构成,拥有大量的核(多达几千个)和大量的高速内存,擅长做类似图像处理的并行计算,以矩阵的分布式形式来实现计算。同
CPU
不同的是,
GPU
的计算单元明显增多,特别适合大规模并行计算。

在人工智能的通用计算
GPU
市场,
NVIDIA
现在一家独大。
2010
年
NVIDIA
就开始布局人工智能产品,
2014
年发布了新一代
PASCAL GPU
芯片架构,这是
NVIDIA
的第五代
GPU
架构,也是首个为深度学习而设计的
GPU
,它支持所有主流的深度学习计算框架。
2016
年上半年,
NVIDIA
又针对神经网络训练过程推出了
基于
PASCAL
架构的
TESLA P100
芯片以及相应的超级计算机
DGX-1
。
DGX-1
包含
TESLA P100 GPU
加速器,采用
NVLINK
互联技术,软件堆栈包含主要深度学习框架、深度学习
SDK
、
DIGITS GPU
训练系统、驱动程序和
CUDA
,能够快速设计深度神经网络
(DNN)
,拥有
高达
170TFLOPS
的半精度浮点运算能力
,相当于
250
台传统服务器,可以将深度学习的训练速度加快
75
倍,将
CPU
性能提升
56
倍。

Training
市场目前能与
NVIDIA
竞争的就是
Google
。今年
5
月份
Google
发布了
TPU 2.0
,
TPU
(
TensorProcessing Unit)
是
Google
研发的一款针对深度学习加速的
ASIC
芯片,第一代
TPU
仅能用于推理,而目前发布的
TPU 2.0
既可以用于训练神经网络,又可以用于推理。据介绍,
TPU2.0
包括了四个芯片,每秒可处理
180
万亿次浮点运算。
Google
还找到一种方法,使用新的计算机网络将
64
个
TPU
组合到一起,升级为所谓的
TPU Pods
,可提供大约
11500
万亿次浮点运算能力
。
Google
表示,公司新的深度学习翻译模型如果在
32
块性能最好的
GPU
上训练,需要一整天的时间,而八分之一个
TPU Pod
就能在
6
个小时内完成同样的任务。目前
Google
并不直接出售
TPU
芯片,而是结合其开源深度学习框架
TensorFlow
为
AI
开发者提供
TPU
云加速的服务,以此发展
TPU2
的应用和生态,比如
TPU2
同时发布的
TensorFlow Research Cloud (TFRC)
。
上述两家以外,传统
CPU/GPU
厂家
Intel
和
AMD
也在努力进入这
Training
市场,如
Intel
推出的
Xeon Phi+Nervana
方案
,
AMD
的下一代
VEGA
架构
GPU
芯片
等,但从目前市场进展来看很难对
NVIDIA
构成威胁。初创公司中,
Graphcore
的
IPU
处理器(
IntelligenceProcessing Unit)
据介绍也
同时支持
Training
和
Inference
。该
IPU
采用同构多核架构,有超过
1000
个独立的处理器;支持
All-to-All
的核间通信,采用
BulkSynchronous Parallel
的同步计算模型;采用大量片上
Memory
,不直接连接
DRAM
。
总之,对于云端的
Training(
也包括
Inference)
系统来说,业界比较一致的观点是竞争的核心不是在单一芯片的层面,而是整个软硬件生态的搭建。
NVIDIA
的
CUDA+GPU
、
Google
的
TensorFlow+TPU2.0
,巨头的竞争也才刚刚开始。
(二)Inference On Cloud云端推理
相对于
Training
市场上
NVIDIA
的一家独大,
Inference
市场竞争则更为分散。若像业界所说的深度学习市场占比(
Training
占
5%
,
Inference
占
95%)
,
Inference
市场竞争必然会更为激烈。
在云端推理环节,虽然
GPU
仍有应用,但并不是最优选择,更多的是采用异构计算方案(
CPU/GPU +FPGA/ASIC)
来完成云端推理任务。
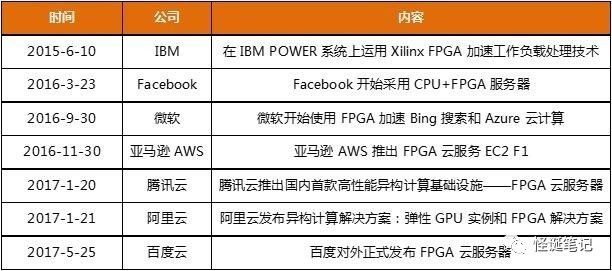
FPGA
领域,四大厂商(
Xilinx/Altera/Lattice/Microsemi)
中的
Xilinx
和
Altera
(被
Intel
收购)在云端加速领域优势明显。
Altera
在
2015
年
12
月被
Intel
收购,随后推出了
Xeon+FPGA
的云端方案,同时与
Azure
、腾讯云、阿里云等均有合作;
Xilinx
则与
IBM
、百度云、
AWS
、腾讯云合作较深入,另外
Xilinx
还战略投资了国内
AI
芯片初创公司深鉴科技。目前来看,云端加速领域其他
FPGA
厂商与
Xilinx
和
Altera
还有很大差距。
ASIC
领域,应用于云端推理的商用
AI
芯片目前主要是
Google
的
TPU1.0/2.0
。其中,
TPU1.0
仅用于
Datacenter Inference
应用。它的核心是由
65,536
个
8-bit MAC
组成的矩阵乘法单元,峰值可以达到
92 TeraOps/second(TOPS)
。有一个很大的片上存储器,一共
28 MiB
。它可以支持
MLP
,
CNN
和
LSTM
这些常见的神经网络,并且支持
TensorFLow
框架。它的平均性能(
TOPS)
可以达到
CPU
和
GPU
的
15
到
30
倍,能耗效率(
TOPS/W)
能到
30
到
80
倍。如果使用
GPU
的
DDR5 memory
,这两个数值可以达到大约
GPU
的
70
倍和
CPU
的
200
倍。
TPU 2.0
既用于训练,也用于推理,上一节已经做过介绍。
国内
AI
芯片公司
寒武纪
科技据报道也在自主研发云端高性能
AI
芯片,目前与科大讯飞、曙光等均有合作,但目前还没有详细的产品介绍。
(三)Inference On Device设备端推理
设备端推理的应用场景更为多样化,智能手机、
ADAS
、智能摄像头、语音交互、
VR/AR
等设备需求各异,需要更为定制化、低功耗、低成本的嵌入式解决方案,这就给了创业公司更多机会,市场竞争生态也会更加多样化。

1)智能手机
华为
9
月初发布的
麒麟
970 AI
芯片
就搭载了
神经网络处理器
NPU(
寒武纪
IP)
。麒麟
970
采用了
TSMC 10nm
工艺制程,拥有
55
亿个晶体管,功耗相比上一代芯片降低
20%
。
CPU
架构方面为
4
核
A73+4
核
A53
组成
8
核心,能耗同比上一代芯片得到
20%
的提升;
GPU
方面采用了
12
核
Mali G72 MP12GPU
,在图形处理以及能效两项关键指标方面分别提升
20%
和
50%
;
NPU
采用
HiAI
移动计算架构,在
FP16
下提供的运算性能可以达到
1.92 TFLOPs
,相比四个
Cortex-A73
核心,处理同样的
AI
任务,有大约
50
倍能效和
25
倍性能优势。
苹果最新发布的
A11
仿生芯片
也搭载了神经网络单元。据介绍,
A11
仿生芯片有
43
亿个晶体管,采用
TSMC 10
纳米
FinFET
工艺制程。
CPU
采用了六核心设计,由
2
个高性能核心与
4
个高能效核心组成。相比
A10 Fusion
,其中两个性能核心的速度提升了
25%
,四个能效核心的速度提升了
70%
;
GPU
采用了苹果自主设计的三核心
GPU
图形处理单元,图形处理速度与上一代相比最高提升可达
30%
之多;神经网络引擎
NPU
采用双核设计,每秒运算次数最高可达
6000
亿次,主要用于胜任机器学习任务,能够识别人物、地点和物体等,能够分担
CPU
和
GPU
的任务,大幅提升芯片的运算效率。
另外,
高通
从
2014
年开始也公开了
NPU
的研发,并且在最新两代骁龙
8xx
芯片上都有所体现,例如骁龙
835
就集成了“骁龙神经处理引擎软件框架”,提供对定制神经网络层的支持,
OEM
厂商和软件开发商都可以基于此打造自己的神经网络单元。
ARM
在今年所发布的
Cortex-A75
和
Cortex-A55
中也融入了自家的
AI
神经网络
DynamIQ
技术,据介绍,
DynamIQ
技术在未来
3-5
年内可实现比当前设备高
50
倍的
AI
性能,可将特定硬件加速器的反应速度提升
10
倍。总体来看,智能手机未来
AI
芯片的生态基本可以断定仍会掌握在传统
SoC
商手中。

2)
自动驾驶
NVIDIA
去年发布自动驾驶开发平台
DRIVE PX2
,基于
16nm FinFET
工艺,功耗高达
250W
,采用水冷散热设计;支持
12
路摄像头输入、激光定位、雷达和超声波传感器;
CPU
采用两颗新一代
NVIDIA Tegra
处理器,当中包括了
8
个
A57
核心和
4
个
Denver
核心;
GPU
采用新一代
Pascal
架构,单精度计算能力达到
8TFlops
,超越
TITAN X
,有后者
10
倍以上的深度学习计算能力。
Intel
收购的
Mobileye
、高通收购的
NXP
、
英飞凌、
瑞萨
等汽车电子巨头也提供
ADAS
芯片和算法。初创公司中,
地平线
的
深度学习处理器(










