Python 语言是数据科学中最常见、最受欢迎的工具之一。近日,Data Incubator 发布了一篇题为《15 个排名最佳的数据科学 Python 包》(Ranked: 15 Python Packages for Data Science)的报告,报告作者对数据科学有价值的 15 个 Python 包进行了一个排名,旨在以一种简单易懂的列表或排名形式帮助数据科学家排序并分析与其专业相关的大量主题。机器之心对报告全文进行了编译,下载报告 PDF 请点击文末「阅读原文」。
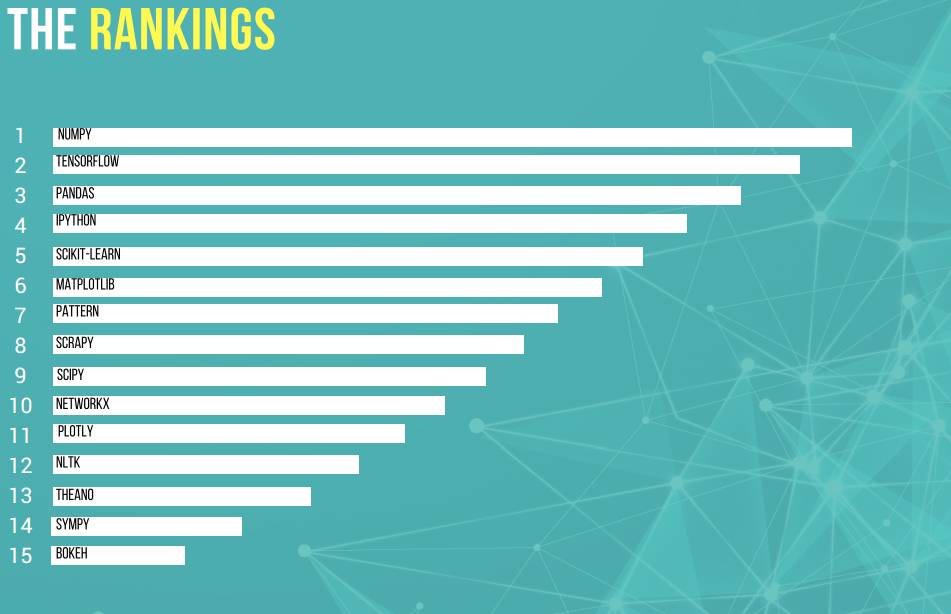
排名
Python 和 R 语言是数据科学中最常见、最受欢迎的工具之一。而且因为 Python 的简单易用,相对其他语言,我们可以使用更少的代码就能表达大多数概念。
这也就正是为什么我们希望通过给出最受欢迎的 Python 包排名而帮助数据科学家入门,或帮助对哪些 Python 包使用广泛有一个了解。
以下就是 Python 包的排名,该排名基于软件包在 Github 的活跃度和 Stack Overflow 活跃度,其指标为 PyPI(Python 库的索引)下载量。
该表单展示了标准分,其中 1 代表高于平均值(均值为 0)一个标准差。例如,numpy 在 Stack Overflow activity 中标准分为 2,其表明高于平均值 2 个标准差,而 TensorFlow 就更接近于均值。
对于这一排位表,研究者专注于使用一些标准进行排序,包括机器学习包的排序列表(exhaust list)和三个客观指标:总下载量、Github 收藏数和 Stack Overflow 问题数量。
然而,可扩展的机器学习包 TensorFlow(起源于谷歌)比其他库在 Github 上要活跃地多(基于收藏和分享数)。更通用的机器学习模块 scikit-learn 在 Github 排名第 2,整体排名第 5。
numpy 和 pandas(高性能数据结构和数据分析包)在 Github 上的得分只在中等,但是在其它两个类别中得分很高。交互式解释器 ipython 整体排名第 4,而 jupyter project(非常流行的 Python 代码展示方式)整体排名第 19(未进入排名)。
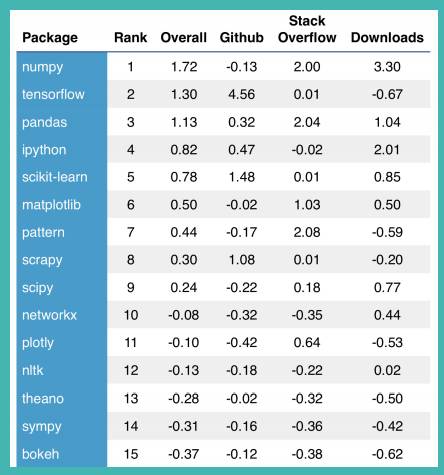
所有数据截止到 2017 年 1 月 19 日。
见解
Github 活跃度 vs Stack Overflow 活跃度
与顶级软件包的 Stack Overflow 问题数量和下载量相比,Github 的活跃度似乎存在反相关性。例如,相比于 TensorFlow 和 scikit-learn、numpy 和 pandas 有很多 Stack Overflow 问题,但是 TensorFlow 和 scikit-learn 在 Github 上具有优势。由于 numpy 和 pandas 是两个「实用」包,也许实际上有更多的人在使用它们(并且需要帮助)。
在所有核心库中,numpy 是最受欢迎的(击败了 pandas 和 scipy)。numpy 遥遥领先排名第 1,pandas 第 3,ipython 第 4,scipy(一个用于数学、科学和工程学的开源软件生态系统)第 9。
在神经网络中,TensorFlow 的表现要优于 Theano
另外一个深度学习包,Theano,在排名中落后 TensorFlow 很多。精心打造的交互式 TensorFlow Playground 可能是 TensorFlow 领先的原因之一。
matplotlib 是最受欢迎的图形库
matplotlib(2D 绘图库)预料之中地成为了最受欢迎的图形包,但是排名之中同样包括 plotly(可以轻松在线发布的交互式、出版级别的图表)和 bokeh(面向现代网页浏览器的交互式可视化库)。ggpy(R 的流行的 ggplot2 包的 Python 端口)的整体排名是 18,但是其数据较不可靠,正如下一节所述。
局限
如同任何分析一样,排名的决定是在分析过程中做出的。所有的源代码和数据都在我们的 Github 上。
机器学习包的完整列表有若干个来源;由于不可用的下载或者 Github 数据,少量包未参与排名。
它们是:basemap(与 matplotlib 映射)、d3py(像 D3 一样的绘图)、jupyter-notebook、mlpy(基于 scipy 和 numpy 的机器学习)、 pylearn2(机器学习,基于 theano)、pytables(大表格)和 shogun(机器学习)。和已排名的包相比,它们在所有方面都低于平均水平。
重要的是,Anaconda 分发捆绑了这些包中的很多,并且这并没有被考虑。
此外,坦白讲,一些存在更长时间的包将有更高的指标,因此会有更高的排名。这不会因为任何方式而调整。
排名数据展示的一些注意事项:
-
ggplot 的 python 端口最近重命名为 ggpy,我们使用 ggpy 作为所有度量(除了下载量,其使用的为 ggplot)。
-
ipython notebook 现在称为 jupyter notebook。Stack overflow 自动将 ipython-notebook 更正为 jupyter notebook,所以研究者结合了其他两个来源的 jupyter notebook 结果。但 jupyter notebook 并没有下载数,所以其并不会出现在最终的排名中。不过研究者分别对 ipython 和 jupyter 进行了研究。
-
Pattern 包在 Stack Overflow 问题指标上已经有很高的得分,因为「pattern」是一个常见词。因为这个词没有标注数据,所以 Stack Overflow 自动将请求「[pattern]」纠正为一些不相关的词。
-
Stack Overflow 的 plotly 数据可能会增长,因为其是 R 和 Python 包。
资源
源代码可在 Data Incubator 的 Github 上获得:https://github.com/thedataincubator/data-science-blogs/
如果你有意了解更多,可考虑查阅以下资源:
-
Python 包完整排名: https://github.com/thedataincubator/datascience-blogs/blob/master/output/python-ranks-withna.csv
-
Tensorflow Playground:http://playground.tensorflow.org/
-
原排名数据(Raw ranking data): https://github.com/thedataincubator/datascience-blogs/blob/master/output/python-data-wide.csv










