Orc
a模型如何从GPT-4的复杂解释痕迹中学习推理
论文摘要:
近期的研究关注如何通过模仿学习,利用大型基础模型(LFMs)生成的输出,提升小模型的能力。影响这些模型质量的问题有很多,包括来自LFM输出的有限模仿信号;小规模同质化的训练数据;以及最显著的缺乏严格评估,导致高估了小模型的能力,因为它们往往只学会了模仿LFM的风格,而不是推理过程。为了解决这些挑战,我们开发了Orca,一个130亿参数的模型,可以学习模仿LFM的推理过程。Orca从GPT-4中学习丰富的信号,包括解释痕迹;逐步的思维过程;以及其他复杂的指令,由ChatGPT的教师协助指导。为了促进这种渐进式学习,我们利用大规模和多样化的模仿数据进行了审慎的采样和选择。Orca在复杂的零样本推理基准测试中,如Big-Bench Hard(BBH)和AGIEval上,分别超过了传统的最先进的指令微调模型Vicuna-13B 100%和42%。此外,Orca在BBH基准测试上达到了与ChatGPT相当的水平,并在专业和学术考试中表现出有竞争力的性能(与优化后的系统消息相比有4个百分点的差距),如SAT、LSAT、GRE和GMAT,在零样本设置下(没有CoT);而落后于GPT-4。我们的研究表明,从逐步解释中学习,无论这些解释是由人类还是更先进的AI模型生成,都是提高模型能力和技能的一个有前途的方向。
这篇论文的主要内容和贡献:
-
本文提出了Orca模型,使用130亿参数的模型来学习模仿大型基础模型GPT-4的推理过程。
-
Orca利用GPT-4生成的复杂解释轨迹、逐步思考过程和其他指令作为丰富的信号,并通过ChatGPT进行引导。
-
为了进行良好的渐进学习,Orca利用大规模和多样化的模仿数据进行巧妙的采样和选择。模仿信号包括解释轨迹、逐步思考过程和其他复杂指令。
-
Orca的性能通过在复杂的推理基准任务上进行评估。与基于GPT-4回应的其他小模型相比,Orca在指令调整模型Vicuna-13B上的性能超过100%,在AGIEval上达到了42%的性能,同时也在SAT、LSAT、GRE和GMAT等专业和学术考试中显示出竞争性的性能。
1. 引言
1.1 现有方法的挑战
近年来,大型基础模型(LFMs)如GPT-3和GPT-4在各种自然语言处理任务上展示了惊人的性能和泛化能力。然而,这些模型也面临着巨大的计算和存储成本,以及潜在的安全和伦理风险。因此,如何利用LFMs的能力,同时降低其开销和风险,成为了一个重要的研究问题。
一种常见的方法是通过模仿学习,训练一个较小的模型来模仿LFM生成的输出。这种方法可以减少训练数据的需求,同时保留LFM的部分能力。然而,现有的模仿学习方法也存在一些问题,例如:
-
来自LFM输出的模仿信号有限,通常只包含表层的文本信息,而没有反映出LFM的推理过程和解释逻辑。
-
模仿数据的规模和多样性不足,导致小模型无法充分学习LFM的知识和技能。
-
缺乏严格的评估方法,导致高估了小模型的能力,因为它们往往只学会了模仿LFM的风格,而不是推理过程。
1.2 主要贡献
为了解决这些挑战,我们开发了Orca,一个130亿参数的模型,可以学习模仿LFM的推理过程。Orca从GPT-4中学习丰富的信号,包括解释痕迹;逐步的思维过程;以及其他复杂的指令,由ChatGPT的教师协助指导。为了促进这种渐进式学习,我们利用大规模和多样化的模仿数据进行了审慎的采样和选择。
用OpenAI大型基础模型(LFMs)
调优的
流行
模型:
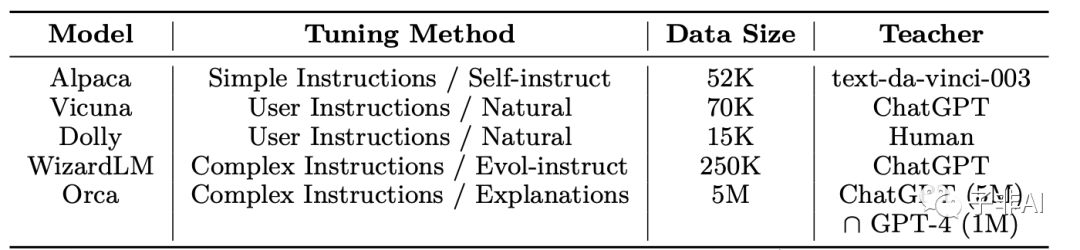
Orca利用复杂的指令和解释进行渐进式学习。
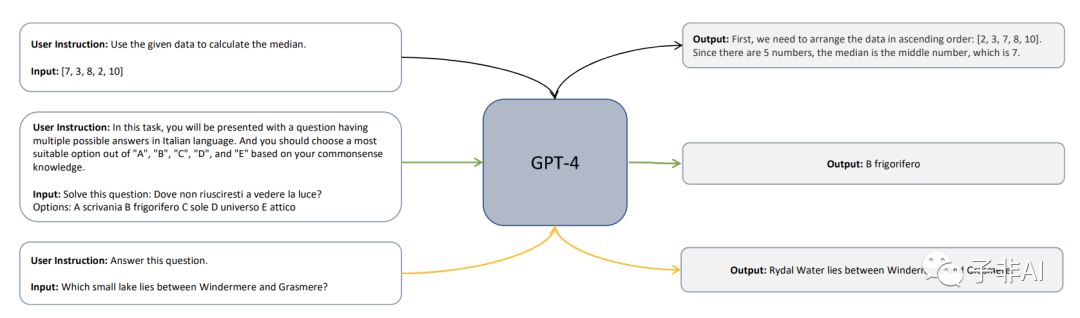
用GPT-4进行指令调优。给定一个任务的用户指令和一个输入,系统生成一个响应。现有的工作,如Alpaca [7],Vicuna [9]和变体,都遵循一个类似的模板,用 ⟨ {user instruction, input}, output ⟩.来训练小型模型。
我们在多个任务上评估了Orca的性能,包括开放式生成、推理、安全等方面。我们发现Orca在复杂的零样本推理任务上超越了传统的指令微调模型,并与ChatGPT达到了相当水平。我们还发现Orca在专业和学术考试上表现出有竞争力的性能,并与GPT-4有一定差距。我们还分析了Orca在安全方面的表现,并讨论了其存在的局限性。
我们认为,从逐步解释中学习,无论这些解释是由人类还是更先进的AI模型生成,都是提高模型能力和技能的一个有前途的方向。
2. 预备知识
2.1 指令微调
指令微调(Instruction Tuning)是一种利用LFM生成输出来训练小模型(Student)的方法。具体来说,给定一个输入文本x和一个指令y(例如“写一首诗”),LFM(Teacher)会生成一个输出文本z(例如“春风又绿江南岸,明月何时照我还”)。然后,Student会根据x和y来预测z,并通过与Teacher的输出比较来优化其参数。这种方法可以让Student学习到不同的指令和任务,而不需要额外的标注数据。
2.2 系统指令的作用
系统指令(System Instructions)是一种特殊的指令,用于控制LFM的生成行为。例如,“请给出一个简短的答案”或者“请给出一个详细的解释”。系统指令可以帮助LFM生成更符合用户需求和场景的输出,同时也可以提供更多的模仿信号给Student。然而,系统指令的设计和优化是一项困难的任务,需要考虑LFM的理解能力和响应能力,以及不同任务和领域的特点。
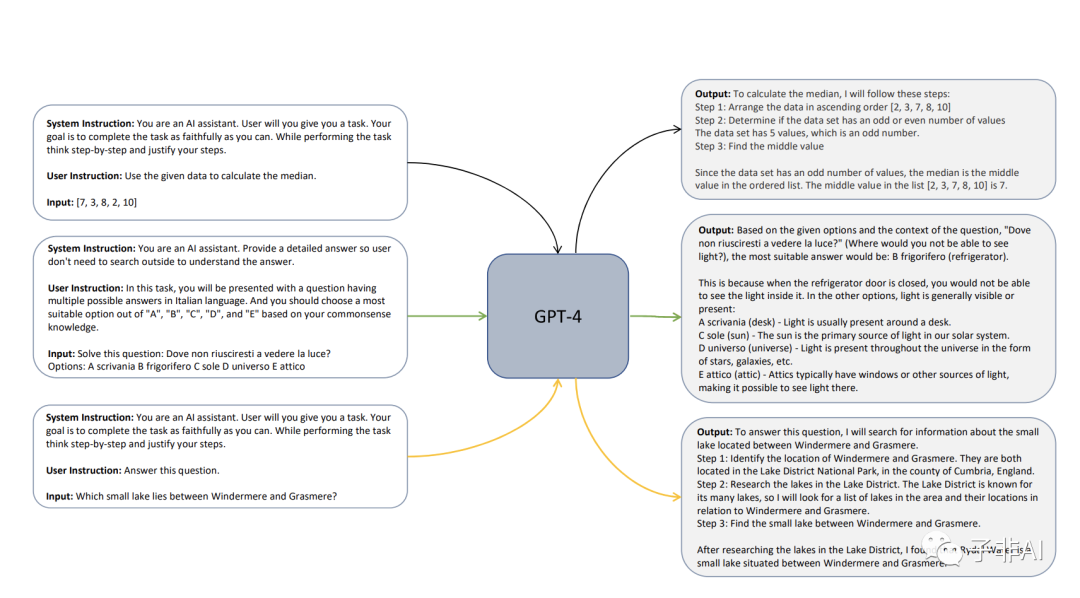
用GPT-4进行解释调优。除了用户指令和输入外,还提供系统指令,以指导系统形成一个合理而有说服力的响应。系统指令从一个多样的指令集中采样,包括思维链条推理步骤,像五岁小孩一样解释,做到有帮助和有信息量等。这样丰富而结构良好的响应,可以让小型模型在⟨ {system instruction, user instruction, input}, output ⟩ 对上模仿GPT-4的思维过程。
3. 解释微调
解释微调(Explanation Tuning)是我们提出的一种新的模仿学习方法,旨在让Student学习模仿LFM的推理过程,而不仅仅是输出。我们认为,通过学习LFM生成的解释痕迹,Student可以更好地理解LFM的思维方式和逻辑步骤,从而提高其生成质量和推理能力。
3.1 数据集构建
为了进行解释微调,我们需要构建一个包含解释痕迹的数据集。我们采用了以下步骤:
3.1.1 系统消息
我们首先设计了一系列系统消息,用于引导LFM生成不同类型和层次的解释。例如,“请给出一个简短的答案,并解释你是如何得到这个答案的”或者“请给出一个详细的答案,并给出每一步的思考过程和证据”。我们根据不同任务和领域的特点,优化了系统消息的表达方式和顺序。

用系统指令来增强用户指令和任务描述,以向大型基础模型查询解释调优。系统消息的设计旨在保持模型生成短答和长答的能力。
3.1.2 数据集描述和从FLAN-v2集合中采样
我们使用了FLAN-v2集合作为我们数据集构建的基础。FLAN-v2是一个大规模且多样化的自然语言处理数据集,包含了超过1000万个输入文本和指令对。我们从FLAN-v2中按照一定比例采样了一部分数据,作为我们数据集构建的输入。我们根据输入文本和指令对的长度、复杂度、主题、难度等特征进行了采样,以保证数据集的多样性和平衡性。
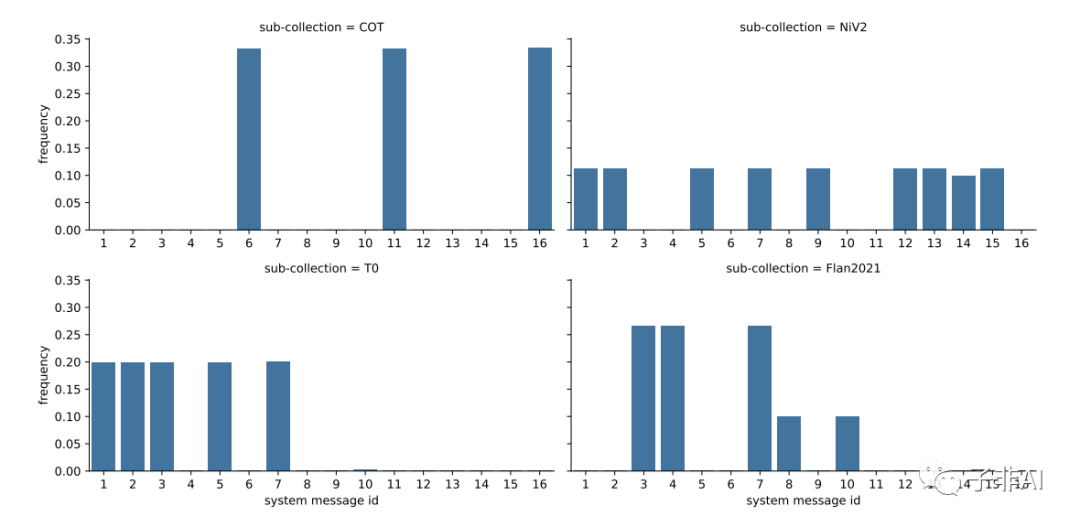
我们训练数据中不同集合的系统消息(参照前表)的相对频率。
3.1.3 ChatGPT作为教师助手
由于LFM(GPT-4)可能无法完全理解或响应系统消息,或者生成不符合要求或错误的输出,我们使用了ChatGPT作为教师助手,来辅助LFM生成更好的解释。ChatGPT是一个专门用于对话生成的模型,具有较强的交互能力和自然性。我们让ChatGPT与LFM进行对话,并通过提问、纠正、引导等方式来帮助LFM生成更好的解释。例如,“你能解释一下你是如何得到这个答案的吗?”或者“你忘了考虑这个条件”。通过这种方式,我们可以获得更丰富、更完整、更准确的解释痕迹。
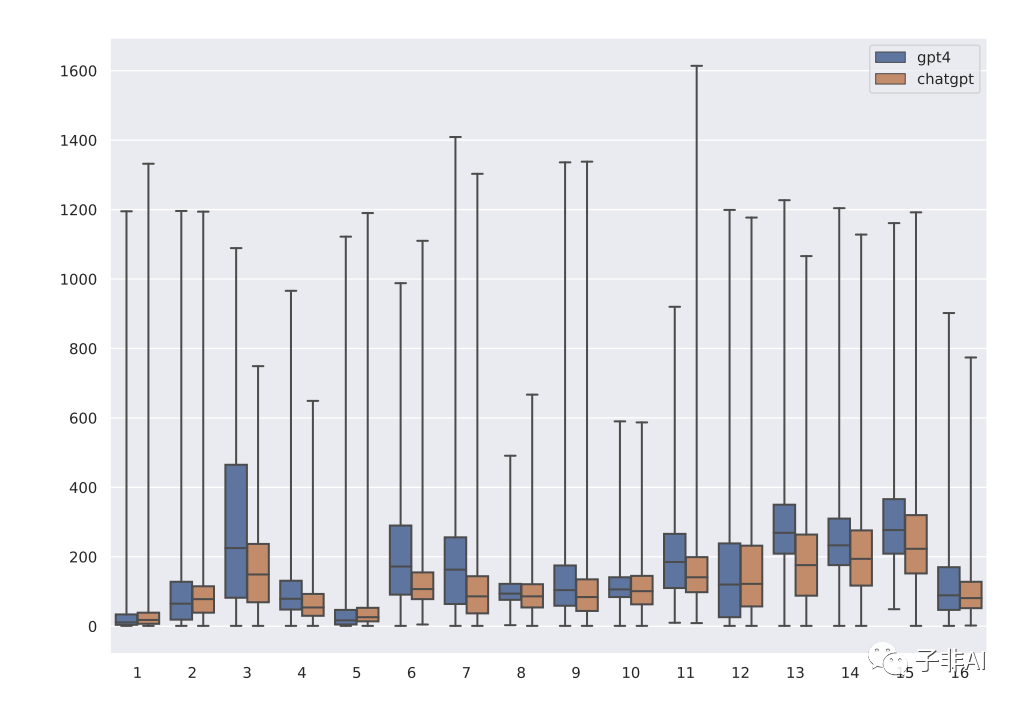 比较GPT-4和ChatGPT对不同系统消息的响应长度分布
比较GPT-4和ChatGPT对不同系统消息的响应长度分布
3.2 训练
本节概述了Orca的训练过程,涵盖了分词、序列化和损失计算的不同方面。
Tokenization
:我们使用LLaMA字节对编码(BPE)分词器来处理输入样本。值得注意的是,LLaMA分词器将所有数字分割成单个数字,并且对未知的UTF-8字符使用字节进行分解。为了处理可变长度的序列,我们在LLaMA分词器的词汇表中添加了一个填充符号“[[PAD]]”。最终的词汇表包含32,001个词符。
Packing
:为了优化训练过程并有效地利用可用的计算资源,我们采用了打包技术。这种方法涉及将多个输入样本拼接成一个序列,然后用于训练模型。打包是按照这样的方式进行的,即拼接序列的总长度不超过max_len= 2,048个词符。具体来说,我们将输入样本随机打乱,然后将样本划分为若干组,使得每组中拼接序列的长度最多为max_len。然后在拼接序列中添加填充符号,使得输入序列的长度统一为max_len,给定我们训练数据中增强指令的长度分布,每个序列的打包因子为2.7个样本。
Loss
:为了训练Orca,我们只计算教师模型生成的词符上的损失,即它学习在系统消息和任务指令的条件下生成响应。这种方法确保模型专注于从最相关和有信息量的词符中学习,提高了训练过程的效率和效果。
Compute
:我们在20个NVIDIA A100 GPU上训练Orca,每个GPU有80GB内存。在FLAN-5M (ChatGPT增强)上训练Orca需要160小时,进行4个epoch,在FLAN-1M (GPT-4增强)上继续训练需要40小时,进行相同数量的epoch。
从多个端点收集来自GPT-3.5-turbo (ChatGPT)和GPT-4的数据分别需要2周和3周,考虑到节流限制、端点负载和查询和响应对的长度分布。
4. 实验设置
4.1 基准模型
我们将Orca与以下几种基准模型进行了比较:
-
Vicuna-13B:一个使用指令微调的130亿参数的模型,从GPT-3生成的简单输出中学习。
-
Text-da-Vinci-003:一个使用指令微调的300亿参数的模型,从GPT-3生成的简单输出中学习。
-
ChatGPT:一个专门用于对话生成的模型,具有较强的交互能力和自然性。
-
GPT-4:一个超大规模的基础模型,具有强大的生成和推理能力。
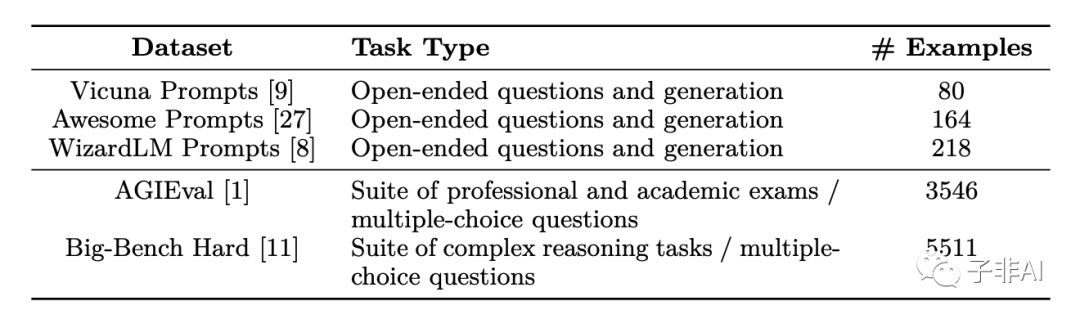 Orca评估基准,数据集统计。
Orca评估基准,数据集统计。
4.2 任务
我们在以下几种任务上评估了Orca的性能:
4.2.1 开放式生成能力
我们使用了Vicuna-Eval数据集来评估Orca在开放式生成任务上的能力。这个数据集包含了多种类型和难度的输入文本和指令对,例如“写一首诗”或者“解释一下这个概念”。我们使用了BLEU、ROUGE、METEOR等指标来评估生成文本的质量和相关性。
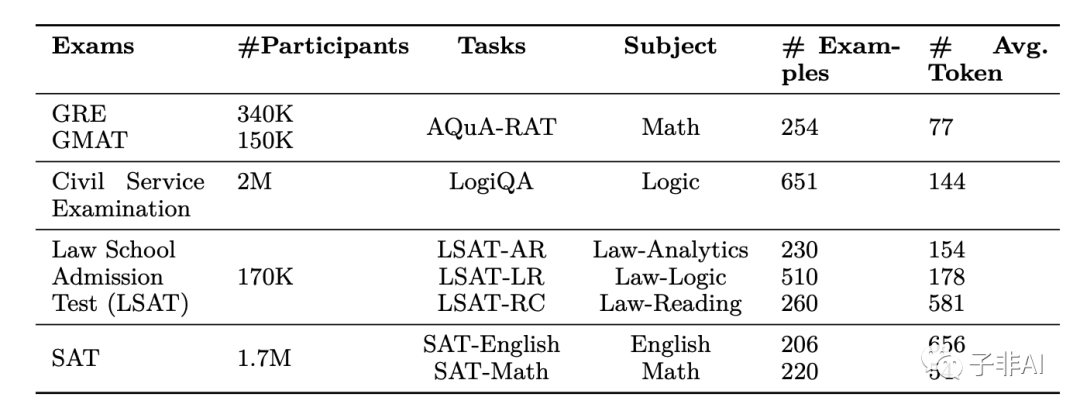 AGIEval基准中任务的细分。
我们按照考试、每年参加这些考试的人数、涉及的科目、样本数和每个样本的平均词符数,显示了各个任务的统计数据。
AGIEval基准中任务的细分。
我们按照考试、每年参加这些考试的人数、涉及的科目、样本数和每个样本的平均词符数,显示了各个任务的统计数据。
4.2.2 推理能力
我们使用了AGIEval和Big-Bench Hard两个数据集来评估Orca在推理任务上的能力。这些数据集包含了多种类型和难度的问题,例如“如果地球上没有月亮,会发生什么?”或者“一个正方形有多少条对角线?”。我们使用了准确率等指标来评估生成答案的正确性和合理性。
5. 开放式生成的评估
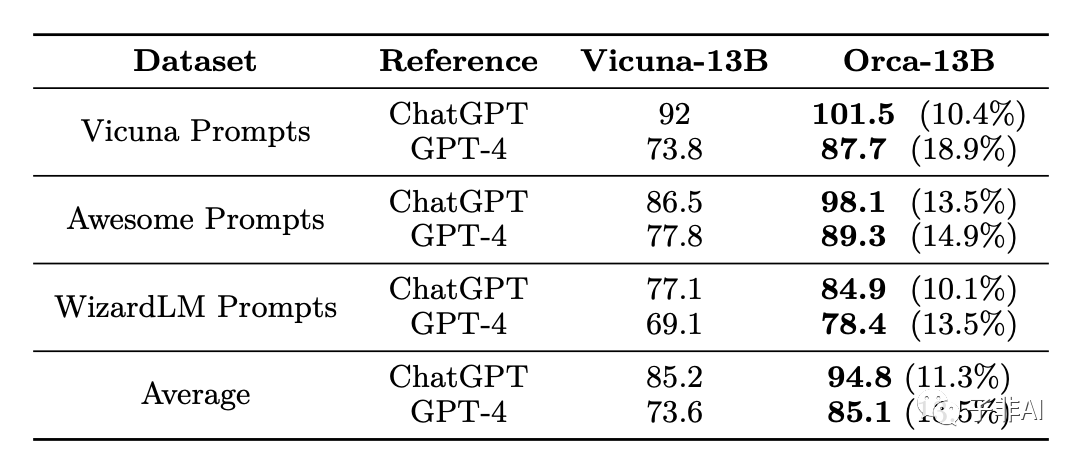
上表显示了候选模型(如Vicuna,Orca)在三个数据集上相对于ChatGPT(GPT-3.5-turbo)和GPT-4作为参考模型的性能,其中GPT-4用作评判者/评分者。候选模型的性能是以候选模型相对于参考模型获得的总分的百分比提高来衡量的。
-
在GPT-4的评估下,Orca在所有数据集上保留了ChatGPT质量的95%和GPT-4质量的85%。Orca在总体上比Vicuna提高了10个百分点。
-
Orca在Vicuna的原始评估设置下与ChatGPT表现相当。在这种设置下,候选模型与ChatGPT进行比较,GPT-4作为评分者,数据集为Vicuna提示数据集。
-
Orca对于涵盖广泛生成角色的提示表现出强大的性能。对于涵盖164个开放式生成角色的Awesome提示数据集,Orca表现出强大的性能,保留了ChatGPT质量的98%和GPT-4质量的89%。
复现注意:我们观察到,在GPT-4的评估中,对比较集中第一个模型的响应有一个正向偏差。这也在最近一项关于分析GPT-4作为评估者的偏差的工作[18]中报告过。在上述所有评估中,第一个模型被视为参考模型,与Vicuna设置18一致。
6. 推理的评估
在AGIEval基准
中
,使用多项选择英语问题比较Text-da-vinci-003、ChatGPT、GPT-4、Vicuna和Orca的零样本性能。
我们从
中报告了人类、TD-003、ChatGPT和GPT-4的性能。
人类的性能分为平均和最高性能。
‘平均’对应于所有考生的平均性能,而‘最高’对应于考生中最高的1%的性能。
括号中
显示
了Orca
相
对于
Vicuna
的百分比提高。
总体而言,Orca与Text-da-vinci-003表现
相当
;
保留
了
ChatGPT质量的88%;
明显落后于GPT-4;
比Vicuna提高了42%。
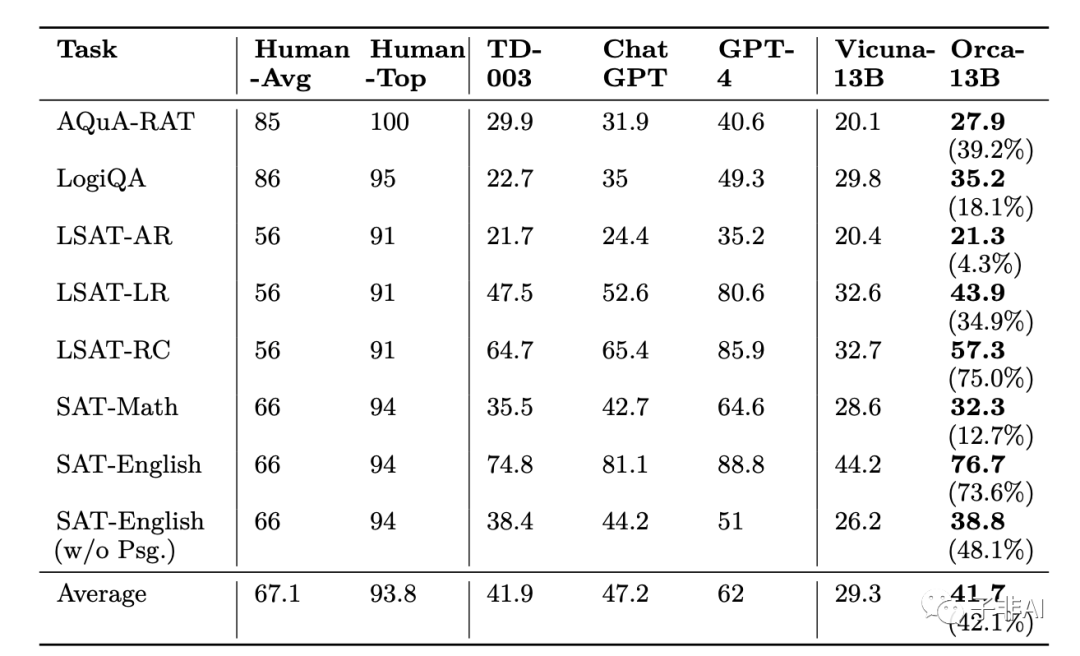
• Orca在所有任务上的总体表现与Text-da-Vinci-003相当,保留了ChatGPT质量的88%。然而,Orca明显落后于GPT-4。
• 我们观察到,对于这样的分析和推理任务,Vicuna的表现明显较差,只保留了ChatGPT质量的62%,而不是85%的开放式生成。这说明了这种开源语言模型的推理能力很差。
• 虽然与Text-da-Vinci-003表现相当,比ChatGPT低5个百分点,但Orca在数学相关的任务上(在SAT,GRE,GMAT中)与ChatGPT之间有更大的差距。
• 与Vicuna相比,Orca表现出更强的性能,在每个类别上都超过了它,在平均水平上有42%的相对提高。
• GPT-4的性能远远超过了其他所有模型,但在这个基准上仍然有很大的提升空间,因为所有模型的性能都明显低于人类在所有任务上的性能。
• Orca的性能根据系统消息的类型而有很大差异。对于我们训练好的模型,空系统消息通常效果很好。
• ChatGPT在不同任务中的450个例子上优于Orca(ChatGPT-beats-Orca例子)。这些例子中的大部分来自LSAT-LR(22%)和LogiQA(21%)任务,而其他LSAT任务和SAT-English任务各贡献不到10%。
• Orca在不同任务中的325个例子上优于ChatGPT(Orca-beats-ChatGPT例子)。在这些例子中,大部分来自LogiQA(29%),而其他LSAT任务和SAT-English任务各贡献不到10%。
GPT-4、ChatGPT和Orca在AGIEval基准上对专业和学术考试的主题性能分解:

7. 安全的评估
我们还评估了Orca在安全方面的表现,包括真实问题回答、有毒内容生成、幻觉等方面。
我们发现Orca在这些方面的表现都优于或接近于ChatGPT,说明Orca通过学习解释痕迹,提高了其安全性和可信度。
然而,Orca仍然存在一些问题,例如生成不准确或不相关的答案、生成有偏见或不恰当的内容、生成与事实不符或无法验证的内容等。
这些问题需要进一步的研究和改进。
7.1 真实问题回答
我们使用了Natural Questions数据集来评估Orca在真实问题回答任务上的性能。










