
来源:由半导体行业观察翻译整理自thenextplatform
,谢谢。
在Google I/O 2016的主题演讲进入尾声时,谷歌的CEO皮采提到了一项他们这段时间在AI和机器学习上取得的成果,一款叫做Tensor Processing Unit(张量处理单元)的处理器,简称TPU。在这个月看来,第一代的TPU处理器已经过时。
在今天凌晨举行的谷歌I/O 2017大会上,谷歌除了宣传了安卓8.0之外,更为重要的是着重谈到了人工智能,于是第二代TPU也就应运而生。TPU是谷歌自主研发的一种转为AI运算服务的高性能处理器,其第一代产品已经在AlphaGo这样的人工智能当中使用,主攻运算性能。
第二代TPU相比较于初代主要是加深了人工智能在学习和推理方面的能力,至于性能的话,全新的谷歌TPU可以达到180TFLOPs的浮点性能,和传统的GPU相比提升15倍,更是CPU浮点性能的30倍。
另外谷歌还推出了一款叫做TPU pod的运算阵列,最多可以包含64颗二代TPU,也就是说浮点性能可以达到惊人的11.5PFLOPS。
从名字上我们可以看出,TPU的灵感来源于Google开源深度学习框架TensorFlow,所以目前TPU还是只在Google内部使用的一种芯片。
TPU 诞生
2011年,Google 意识到他们遇到了问题。他们开始认真考虑使用深度学习网络了,这些网络运算需求高,令他们的计算资源变得紧张。Google 做了一笔计算,如果每位用户每天使用3分钟他们提供的基于深度学习语音识别模型的语音搜索服务,他们就必须把现有的数据中心扩大两倍。他们需要更强大、更高效的处理芯片。
他们需要什么样的芯片呢?中央处理器(CPU)能够非常高效地处理各种计算任务。但 CPU 的局限是一次只能处理相对来说很少量的任务。另一方面,图像处理单元(GPU) 在执行单个任务时效率较低,而且所能处理的任务范围更小。不过,GPU 的强大之处在于它们能够同时执行许多任务。例如,如果你需要乘3个浮点数,CPU 会强过 GPU;但如果你需要做100万次3个浮点数的乘法,那么 GPU 会碾压 CPU。
GPU 是理想的深度学习芯片,因为复杂的深度学习网络需要同时进行数百万次计算。Google 使用 Nvidia GPU,但这还不够,他们想要更快的速度。他们需要更高效的芯片。单个 GPU 耗能不会很大,但是如果 Google 的数百万台服务器日夜不停地运行,那么耗能会变成一个严重问题。
谷歌决定自己造更高效的芯片。
2016年5月,谷歌在I/O大会上首次公布了TPU(张量处理单元),并且称这款芯片已经在谷歌数据中心使用了一年之久,李世石大战 AlphaGo 时,TPU 也在应用之中,并且谷歌将 TPU 称之为 AlphaGo 击败李世石的“秘密武器”。
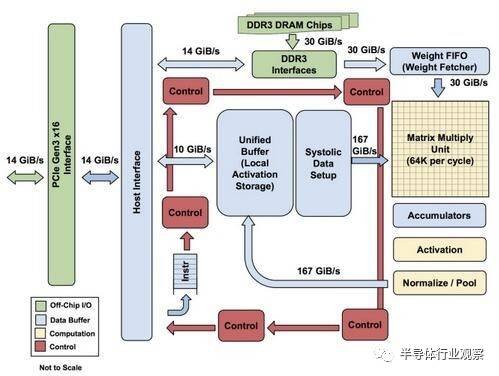
第一代TPU内部架构
该图显示了TPU上的内部结构,除了外挂的DDR3内存,左侧是主机界面。指令从主机发送到队列中(没有循环)。这些激活控制逻辑可以根据指令多次运行相同的指令。
TPU并非一款复杂的硬件,它看起来像是雷达应用的信号处理引擎,而不是标准的X86衍生架构。Jouppi说,尽管它有众多的矩阵乘法单元,但是它GPU更精于浮点单元的协处理。另外,需要注意的是,TPU没有任何存储的程序,它可以直接从主机发送指令。
TPU上的DRAM作为一个单元并行运行,因为需要获取更多的权重以馈送到矩阵乘法单元(算下来,吞吐量达到了64,000)。Jouppi并没有提到是他们是如何缩放(systolic)数据流的,但他表示,使用主机软件加速器都将成为瓶颈。
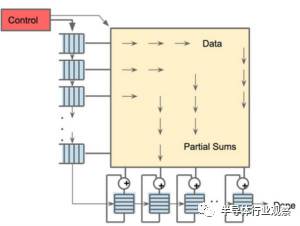
256×256阵列缩放数据流引擎,经过矩阵乘法积累后实现非线性输出
从第二张图片可以看出,TPU有两个内存单元,以及一个用于模型中参数的外部DDR3 DRAM。参数进来后,可从顶部加载到矩阵乘法单元中。同时,可以从左边加载激活(或从“神经元”输出)。那些以收缩的方式进入矩阵单元以产生矩阵乘法,它可以在每个周期中进行64,000次累加。
毋庸置疑,谷歌可能使用了一些新的技巧和技术来加快TPU的性能和效率。例如,使用高带宽内存或混合3D内存。然而,谷歌的问题在于保持分布式硬件的一致性。
能够进行数据
推理的第二代TPU
第一代的TPU只能用于深度学习的第一阶段,而新版则能让神经网络对数据做出推论。谷歌大脑研究团队主管Jeff Dean表示:“我预计我们将更多的使用这些TPU来进行人工智能培训,让我们的实验周期变得更加快速。”
“在设计第一代TPU产品的时候,我们已经建立了一个相对完善和出色的研发团队进行芯片的设计研发,这些研发人员也基本上都参与到了第二代TPU的研发工程中去。从研发的角度来看,第二代TPU相对于第一代来说,主要是从整体系统的角度,提升单芯片的性能,这比从无到有的设计第一代TPU芯片来说要简单许多。所以我们才能有更多的精力去思考如何提升芯片的性能,如何将芯片更好的整合到系统中去,使芯片发挥更大的作用。”Dean在演讲中表示。
未来,我们将继续跟进谷歌的进度,以进一步了解这一网络架构。但是在此之前,我们应当了解新一代TPU的架构、性能以及工作方式,明白TPU是如何进行超高性能计算的。在此次发布会上,谷歌并没有展示新一代TPU的芯片样片或者是更加详细的技术规格,但是我们依旧能够从目前所知的信息中对新一代TPU做出一些推测。

从此次公布的TPU图片来看,第二代TPU看上去有点像Cray XT或者是XC开发板。从图片上,我们不难发现,相互连接的几个芯片被焊接到了开发板上,同时保持了芯片之间以及芯片与外部的连接功能。整个板子上共有四个TPU芯片,正如我们之前所说,每一个单独的芯片都可以达到180TFLOPs的浮点性能。
在开发板的左右两侧各有四个对外的接口,但是在板子的左侧额外增加了两个接口,这一形式使得整个板子看上去略显突兀。。如果未来每一个TPU芯片都能够直接连接到存储器上,就如同AMD即将推出的“Vega”处理器可以直接连接GPU一样,这一布局就显得非常有趣。左侧多出的这两个接口在未来可以允许TPU芯片直接连接存储器,或者是直接连接到上行的高速网络上以进行更加复杂的运算。
以上这些都是我们基于图片的猜测,除非谷歌能够透露更多的芯片信息。每一个TPU芯片都有两个接口可以与外部的设备进行连接,左侧有两个额外的接口对外开发,可以允许开发者在此基础上设计更多的功能,添加更多的扩展,无论是连接本地存储设备还是连接网络,这些功能在理论上都是可行的。(实现这些功能,谷歌只需要在这些接口之间建立相对松散可行的内存共享协议即可。)
下图展示了多个TPU板一种可能的连接形式,谷歌表示,这一模型可以实现高达11.5千万亿次的机器学习计算能力。

这一结果是如何得出的呢。上面这种连接方式,从外形上来看,非常像开放的计算机架构,或者是其他的一些东西。纵向上来看,叠加了8个TPU板,横向上看,并列了4个TPU板。目前我们无法断定每一个开发板都是完整的TPU板或者是半个开发板,我们只能看到板子的一侧有6个接口,另一侧有2个接口。
值得注意的是,板子的中间采用了4个接口,而左右两侧采用了2个接口,并且在左右两侧也没有见到与TPU开发板类似的外壳。对此,一个比较合理的解释就是,左右两侧连接的是本地存储器接口,而不是TPU芯片接口。
即便如此,我们依旧能看到至少32个TPU二代母板在运行,这也意味着,有128个TPU芯片在同时运行。经过粗略的计算,整套系统的计算能力大概在11.5千万亿次。
举个例子来说,如果这一运算能力在未来能够运用到商业领域,谷歌现在进行的大规模翻译工作所采用的32个目前最先进的GPU,在未来就可以缩减为4个TPU板,并能够极大的缩减翻译所需要的时间。
值得注意的是,上文所提到的TPU芯片不仅仅适用于浮点运算,也同样适用于高性能计算。
TPU的训练与学习
与第一代TPU相比,第二代TPU除了提高了计算能力之外,增加的最大的功能就是数据推理能力,不过这一推理模型必须先在GPU上进行训练才可以。这一训练模式使得谷歌等开发厂商必须降低实验的速度,重塑训练模型,这将耗费更长的时间,才能使机器获得一定的数据推理能力。
正是因为如此,在相对简单和单一的设备上先进行训练,然后将结果带入带更为复杂的环境中去,从而获得更高层次的数据推理能力,这一迭代工程是必不可少的。未来,英特尔推出的用于人工智能的GPU也将会采用这一迭代模式。英伟达的Volta GPU也是如此。
拥有“tensor core”的英伟达Volta GPU拥有超高速的机器学习与训练能力,未来可能达到120万亿次的单设备计算能力,这一运算能力与去年上市的Pascal GPU相比,在计算能力上提升了大约40%。但是像谷歌推出的TPU这种超高速的计算能力所带来的影响,我们即便很难在生活中切身的体会到,但是GPU越来越快的计算能力依旧令人印象深刻,也离我们更近。
Dean表示,英伟达Volta所采用的架构是非常有趣的,这一架构使得通过核心矩阵来加速应用的目的成为可能。从一定程度上来说,谷歌推出的第一代TPU也采用了类似的想法,实际上,这些技术现在依然在机器学习的流程中被采用。“能够加快线性计算能力总是非常有用的。”Dean强调。





