
G7和阿里云,一个是国内最专业的物流数据服务公司,一个是全球3A云计算服务商。他们的强强联合,会创造出怎样的火花?
2015年,随着业务的发展,用户超过三万家,车辆超过30万的G7数据量呈几何倍数地增加。
如何用数据连接每一辆卡车、货主、运力主和司机,提升运输服务效率?G7一番慎重调研后,决定放弃自建机房,而是采用云计算服务快速构建系统,响应业务变化。
在对比了国内比较成熟的云服务后,阿里云的可靠性,安全性,低成本给G7留下比较好的印象,再加上阿里云提供了很多云服务,比如数据存储,消息中间件,大数据运算,防火墙,安全策略等,让技术的落地成本更低,所以最终选择使用阿里云搭建公司的IT设施。
总体技术架构
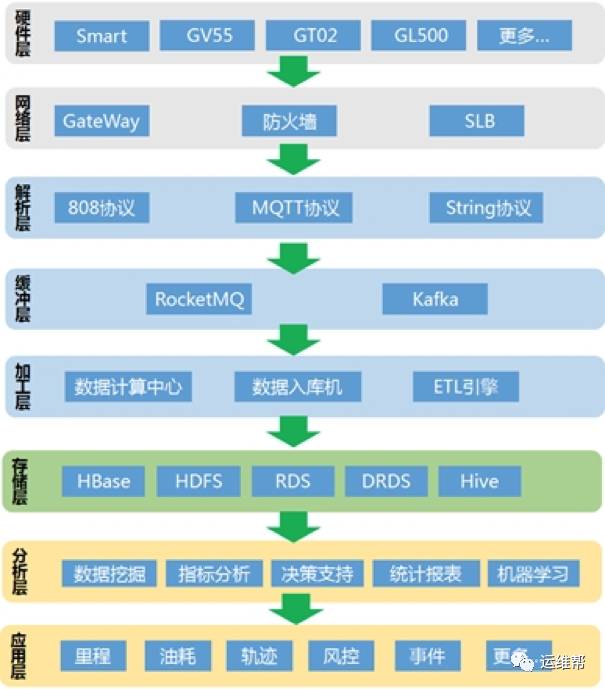
简单介绍下数据处理的整个流程:
-
安装在车辆上的硬件设备通过传感器采集车辆数据,通过网络传输到后台程序的接口。
-
网络层通过防火墙、网关过滤异常访问,其他的合法请求通过SLB进行均衡分发到后台解析机。
-
解析机根据对应的消息协议解析数据,将解析后的数据写入到MQ中。
-
MQ类似于一个巨大的buffer池,实现读写解耦。
-
数据计算中心包括流式计算、离线计算等从MQ中消费数据并根据业务处理数据,最后将计算数据写入存储层,这个是比较复杂的业务;数据入库机将数据进行业务处理,负责将数据写入存储层,这个是比较固定的业务;ETL引擎根据预先设置的规则将数据处理后写入存储层,为下面的数据分析做准备。
-
数据分析主要是利用大数据的处理能力,比如spark、hive、mapreduce等对数据进行分析处理,包括指标分析,统计报表,数据挖掘和机器学习。
-
通过对数据分析产生的结果进行更进一步的分析和汇总,形成应用层的一些数据产品并提供相应的服务接口,比如公司的一些主要业务:里程、油耗、轨迹等。
从整个架构图中可以看到数据链路比较长,从硬件上传到数据应用中间要经过5个环节,其中最为重要的就是数据存储层。
存储层要保证由数据生产方传输到的数据一条不差的写入到库中,提供大数据写入的幂等性、完整性、事务性、容灾性;也要保证数据应用方在查询数据时的及时的返回,提供数据大量访问的实时性、正确性和稳定性。基于此基本要求,公司建设了数据存储中心。
数据存储中心
首先,因为我们是做物流行业,数据的来源是车辆、传感器等,数据量大、数据结构多、查询相应即时特点,因此我们需要的数据存储介质是一种支持大量写入、无模式(no schema)、快速查询以及强大的扩展性,是一种典型的nosql使用场景。我们的查询场景比较单一,通常都是两个维度左右。所以最终决定使用云HBase作为主数据库。另外一些数据量不是很大,查询条件较为复杂的使用阿里云的RDS。
其次,物流行业的数据都是有时间维度,是标准的实际序列数据,通常最近的数据查询的频率会较高,越久的数据使用频率越少。我们把数据分成了三部
分:
热数据、温数据、冷数据
。
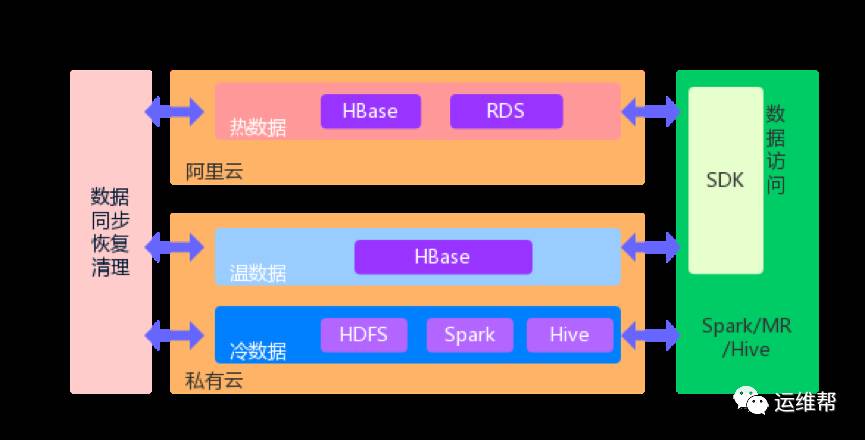
数据分层
热数据(在线查询)是6月以内的数据,会大量被访问,占总访问的90%左右。使用云HBase,RDS 存储。
温数据(近线查询)是6个月到12个月的数据,访问量相对较小,大概占比在6%~9%左右。使用自建机房的HBsae存储。
冷数据(离线查询)是12个月以前的数据,访问量在1%以下。使用hdfs存储。通过spark/mapreduce/hive访问。这部分数据在存储时,为了提高存储效率和查询效率,使用了Parquet格式和gzip压缩的组合。
大致过程是这样,我们相应的提供了两套查询接口。查询12个月以内数据时,通过HBase SDK的接口,自动路由到在线数据库或者近线数据库的HBase访问数据,将结果返回给调用方,通常都会在秒级别内完成调用。查询12个月以后数据,调用spark/mr接口,通过访问hdfs中的离线数据,将结果返回给调用方,调用时间会根据查询数据量而不同,通常在半小时内。在保证数据调用的同时,实现了最低的系统成本。
混合云
公司自有的私有云在使用成本、安全性方面更有竞争力,公有云在计算资源、可扩展性方面更有优势,基于以上考虑,公司将数据中心搭建成混合云模式。在线数据库放在阿里云中,近线数据库和离线数据库放在自建机房的私有云中。云之间通过专线VPN进行连接,保证数据能安全、可靠地进行同步。
数据同步/恢复
数据的同步,主要有两种同步方式,一种是实时同步,通过RDS的binlog,HBase的replication机制实时的将数据同步到HBase中,这种方式的好处是实时性强和没有延迟,坏处是数据一致性难保证,稳定性要求很高,开发工作能力大。
离线同步的,是通过MapReduce程序读取出HBase/RDS的数据,通过yarn的集群运算能力将数据写入到HBase,好处是稳定型强,开发简单,缺点是数据会有一定延迟。经过权衡,我们选用了第二种数据同步机制。
数据恢复与数据同步相反,通过mapreduce读取下层数据恢复成上层数据,这就很简单了。
HBase设计
主要分享下里程计算的表设计:
里程计算,算是公司最核心的业务:传感器会收集每辆货车的定位数据上传到MQ中,其中包括经度、纬度、设备上报时间、车辆状态等。首先Storm会从MQ中捞取实时的定位,通过合并、聚合、相应的距离的算法,计算出车辆的里程数据并存储到HBase中。这是初步结果,因为网络原因,GPS漂移等问题,准确率在80%左右,所以还有一个补偿算法。最后Spark会每小时从HBase捞取到初步结果,进行深度计算,包括补偿算法,缺失值修复,异常值剔除,最后计算出最终里程数据回写到HBase中。通常是计算同一辆车的两个相邻点的经纬度差值。查询条件通常是“车辆号+时间”,有时也会带一些其他条件比如机构号,设备状态,停留时间等。
车辆号(imei)是具有一定规律的,通常是由机构号做为前缀,长度15~20字节,为了防止HBase中出现Hotregion,我们对 imei(md5处理)保证数据散列,这样imei也定长了。
|
Rowkey设计
|
|
字段名
|
字段类型
|
字段长度
|
描述
|
|
Imei
|
md5处理,取byte
|
16字节
|
没有取tostring的值,否则会变成32字节
|
|
Time
|
Long
|
8字节
|
没有取tostring的值,否则会变成20170214171232的长度
|
查询时rowkey过滤掉大部分数据之后,剩下的查询条件通过filter过滤就不太多了。通过这样的设计每个rowkey占用24字节空间,节约了不少存储空间,也满足了查询条件。
Tips:在设计rowkey时,尽量使用数据的基本类型可以节约不少空间。比如int类型存储到HBase中占用4字节,long类型占用8字节,如果用成了字符串空间会翻倍。
由于使用了阿里云的E-MapReduce和云数据库HBase产品,比起通过私有云进行HBase设计,整体应用效率都有极大的提升。
其他数据库的应用
另外由于HBase在多条件查询方面的限制,我们也在探索多种维度的数据查询和存储。比如最近对phoenix做了详尽的研究, 首先phoenix是基于Hbase作为底层存储的,存储量和稳定性有保证。另外,它在HBase之上增加了SQL解析执行层,支持通过SQL语句访问HBase中的数据,并且对多维度的支持相对HBase有了显著的提高,可以用来存储一些数据量较大的多维数据。
经验总结
1.数据迁移:
由于我们在混合云实施中,涉及数据迁移的问题,由于迁移的数据量很大,有上百TB,数据基本上都是在HBase中。迁移的过程中也遇到了很多坑。有一张表大概30TB,最开始使用HBase自带的copyTable功能,但是经常会出现超时,mapreduce几乎没有进展,我们自己在sqoop上做了二次开发,先将HBase的数据导出来生成文本文件并压缩,将文件传输到目标集群的hdfs,在目标集群运行MapRedcue生成HFile直接加载到HBase中,经过测试这个性能最快但是有一个限制必须是空表才能用。不是空表,我们使用MapReduce从hdfs中读取文件数写入到HBase中,当然吞吐量有所下降,但是还是能接受,大概每秒写入3w+。
2.HBase读写分离
在某些时候,如果有大量的数据写入到HBase集群的一张表,整个集群的查询速度都会下降很多,接口调用经常超时。最开始我们使用HBase的限流功能quatos(1.1.0版本以上才提供),在测试了它的两种限流方式request和size之后都发现不太好用,request和size与真正的数据量之间的误差比较大,考虑到这是一个新功能,放弃使用。
最后使用HBase的队列读写分离方案,设置HBase.ipc.server.callqueue.handler.factor=150,HBase.ipc.server.callqueue.read.ratio= 0.6,也就是9个队列用于写操作,6个队列用以读操作,这样即使在写入量很大的情况下集群仍然有队列可以提供读操作。
3.HBase目前没有监控每张表的指标
HBase的web ui中有整个集群每秒的request,但没有每张表的request。另外有一点,HBase中查看某张表当前的数据量只能通过count命令或者mapreduce去跑任务统计,这样太慢了并且消耗资源。针对这两点,我们自己开发了一个统计工具通过读取regionserver的metrics汇总数据,计算出每张表的qpts,wps,数据总量等,并通过邮件发送给使用方,随时了解每张表的读写情况,方便定位问题了解集群负荷。
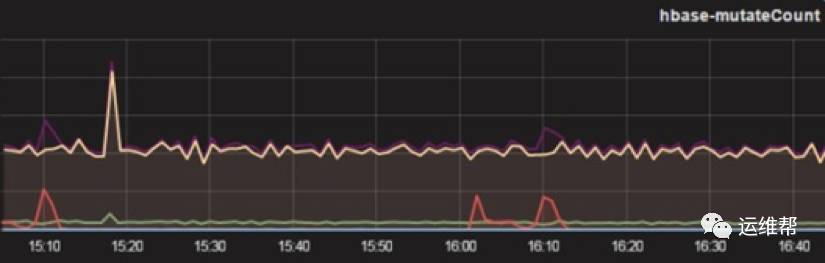
每张表的wps汇总
在使用阿里云的过程中,阿里云为G7提供了全面的系统优化,专业的人工运维,以及全套的监控工具。对于G7大数据的稳定运行起到了非常重要的帮助和支持。
商务合作,请加微信yunweibang555






