客户挽留在很多行业都是一个备受关注的问题,比如电信、银行、保险、零售等。
要做客户挽留就需要对客户流失进行预警、客户流失原因分析、客户满意度或忠诚度研究、客户生命周期研究等相关问题进行深入而全面的分析。
例如,对客户的行为特征进行分析,可以了解有多少客户流失,客户是什么时候流失的,以及客户是如何流失的等问题,从而监控客户流失、实现客户关怀。
应用数据挖掘技术可以根据过去拥有的客户流失数据建立客户属性、服务属性和客户消费数据与客户流失可能性关联的数学模型,找出客户属性、服务属性和客户消费数据与流失的关系,给出明确的数学公式或规则,从而计算出客户流失的可能性。
电信行业较早地提出了客户关系管理、关系营销等营销管理模式,学界和企业界的积极参与也推动了客户流失行为的相关研究。
一、怎样才算流失?
根据调查,企业平均5年就会失去一半的客户,而失去一个客户带来的巨大损失,可能需要拉进来10个新客户才可以弥补。
所以,客户流失问题必须重视起来。
客户流失问题一般是客户服务中心或产品运营部门提出来的。
他们的主要工作是,采取有效的运营策略或营销活动,吸新客(让更多人成为客户),保活跃(让客户经常过来买),防流失(让客户继续过来买)。
作为数据分析师,在做流失分析前,需要和这些部门从业务层面进行详细地沟通。
沟通主要包括以下方面:
(1)怎样才算流失?
(2)流失的原因有哪些?
(3)流失前有什么表现?
(4)流失客户中有哪些值得挽回?
(5)目前对流失客户采取的策略和手段有哪些?
谁执行?
效果如何?
二、为什么会流失?
客户为什么不再过来使用我们的产品或服务了呢?这肯定是有原因的。
只不过有些原因可以从数据中知道,有些原因不得而知。
关于客户流失的原因有以下几方面:
(1)自身原因,例如,客户离开本地了
。
(2)价格问题,例如,客户感觉东西太贵了。
(3)信号不好,客户经常投诉。
(4)服务人员态度差,或不够热情,引发客户不满。
(5)
竞争对手,例如,竞争对手推出更优惠的套餐,很多客户都被吸引过去。
(7)品牌形象下降,例如,经常曝出的经营问题,负面新闻多,客户往往选择离开。
(8)其它原因。
三、如何预测流失?
我们知道了流失问题的分析目标,也知道了可能的流失原因,自然有人会问,我们能不能提前知道哪些客户会流失,这样的话就可以采取措施挽回了。
客户流失预测模型就是为了解决这个问题,是利用算法预测客户流失的概率,概率越大,就越有可能流失。
那么流失预测如何建立?
建立主要流程如下:
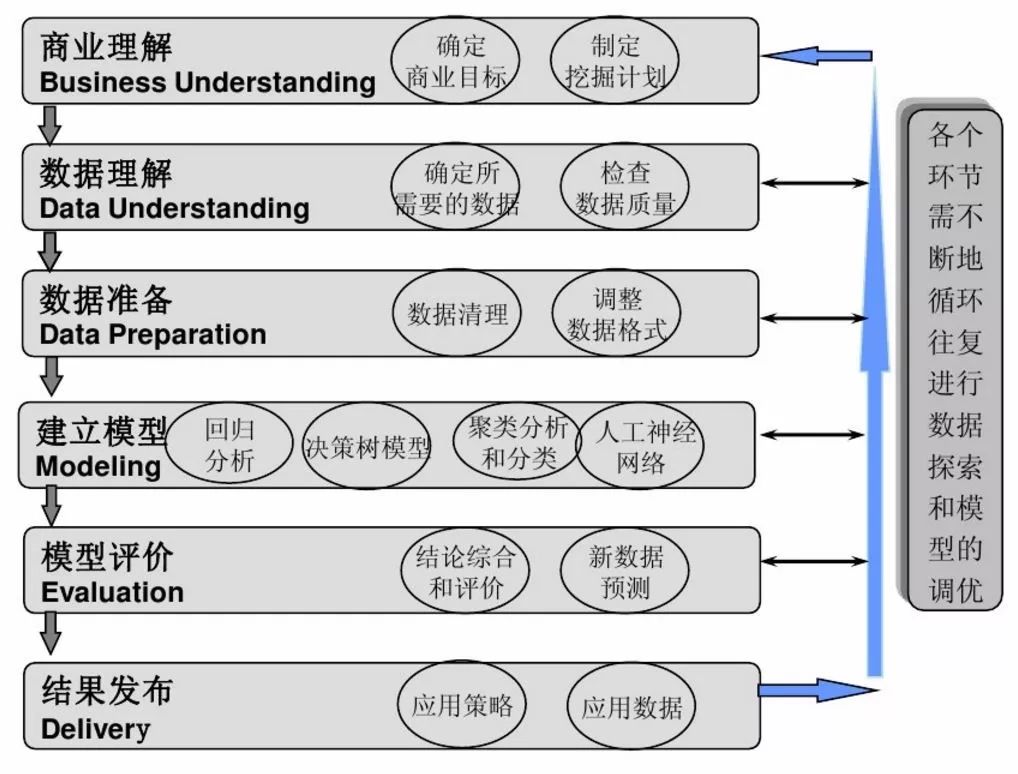
(1)确定客户流失模型的目标
预测可能流失的客户名单。
经过对市场的分析,我们发现移动电话流失率比较大,而宽带等数据业务还处于增长期,流失率比较小。
因此,我们把预测的产品范围限定在移动电话上。

(2)获取用于建模的数据
建模的数据可以从各个营运系统中提取。
可以从BOSS系统提取客户数据、服务数据、产品数据、套餐数据、业务数据:
从计费账务系统提取市话计费数据、长途计费数据、智能网计费数据、省数据业务计费数据;
从CMMS系统提取渠道数据;
从资源系统提取地址数据、资源数据;
从交换系统提取通话数据等等。

(3)对数据进行清洗,转换成建模数据集
训练模型前,还要做缺失值填补、极值处理、数据转换、数据标准化等预处理。

模型集的行代表一个移动电话,计费等数据则对应到各个列。
为了使预测结果更接近于现实情况,我们取最近12个月的计费数据。
接下来,我们要剔除一些无效的变量,如身份证号、电话号码、绝对日期、地址数据等。
这些交量对建模没有用处。
最后就是加入衍生变量,这个过程需要我们对电信业务进行深入的分析并充分发挥创造性,这样才能生成一组对建模很有意义的衍生变量。
(4)建立模型
一般来说,从建模宽表中随机抽取70%的数据作为训练集,用于训练模型的参数;
其余的30%作为测试集,用于检验模型的性能。
这么做,主要是为了防止模型过拟合。
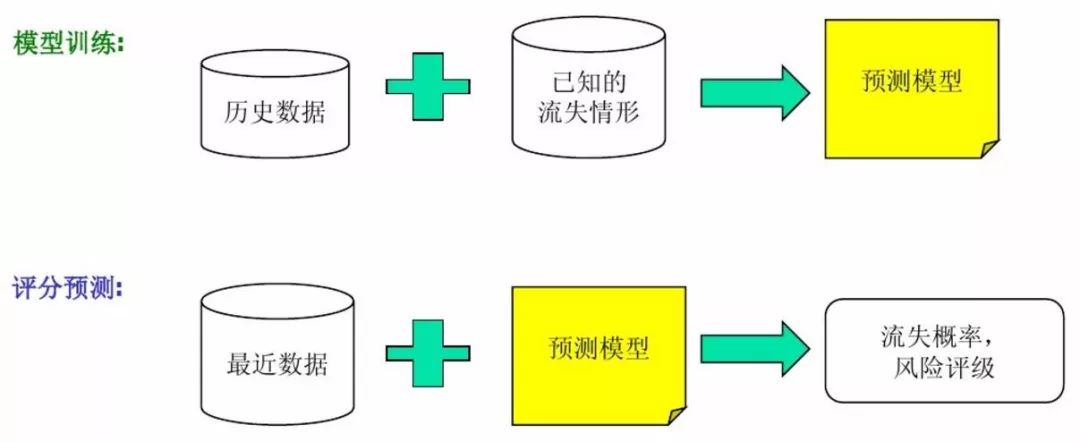
训练模型时,选择合适的算法,得到最优的结果。
算法方面,可使用Logistic回归、决策树、随机森林、神经网络、SVM、贝叶斯、集成学习等技术方法,也可使用多种方法同时训练,最后选择最优的模型。
其中,Logistic回归用得最多,原因是结果简单明了,容易理解,但不好的地方是,结果是线性的,但很多现实规律都是非线性的,用线性公式刻画可能会还不够。
(5)模型评估
模型出来了,但模型的效果怎么样还不知道,需要评估。
评估最常用命中率、提升率、覆盖率三个指标。

命中率
=实际流失人数/每个箱的人数
即实际流失率,表示对选取一定数量的客户假设不进行任何挽留时实际流失人数占总数的比例,体现了模型判断的正确性;
提升率
=实际流失率/总体平均流失率
即使用模型捕获的流失人数与不使用模型捕获的流失人数的比例,体现了对所选取的客户使用模型进行挽留与不使用模型进行挽留的提升效果;
覆盖率
=实际流失人数/总体实际流失人数
表示在进行挽留时,能“召回”的流失客户占全部流失的比例。
(6)模型预测结果用于支持决策
客户流失率预测模型建立后,我们就及时预测某个客户流失的可能性大小。
当其流失可能性高于某一分值,我们就认为他是将可能流失的客户,就可以及时的推出针对性的营销套餐来留下该客户。
好消息
数据分析专家@文彤老师
特别推出《Python数据分析行业案例--客户流失分析》视频课程










