吴恩达,百度首席科学家、百度大脑项目负责人。在最近的百度语音开放平台三周年主题活动上,机器之心对这位与 Geoffrey Hinton、Yoshua Bengio、Yann LeCun 齐名的人工智能专家进行了专访,深度了解了百度的人工智能研究、吴恩达的人工智能之路,以及更多的有关人工智能技术的话题。
一、在百度的人工智能研究
2014 年 5 月 16 日,百度官方宣布建立硅谷实验室并任命吴恩达作为首席科学家,领头百度北京与硅谷的实验室。当时,百度投入了 3 亿美元在硅谷建起专注人工智能的实验室。
但吴恩达来到百度,并非重头开始建立深度学习。在 2013 年,百度就已建立深度学习研究院(IDL),并在图像识别、基于图像的搜索、语音识别、自然语言处理与语义智能、机器翻译等领域做出重大进展。当时,IDL 由余凯(2012 年加入百度,2015 年离职)组建,百度 CEO 李彦宏任院长,余凯任常务副院长。
加入百度之后,吴恩达做了一件事。「他订购了 1000 个 GPU,并在 24 小时内得到。而在谷歌,他可能几周或几个月才能得到。」当时深度学习创业公司 SkyMind 的联合创始人 Adam Gibson 在一次采访中曾这么说道。
百度之前从未买过这样的硬件。在这样的支持下,吴恩达在百度建立了一个进行深度学习的 GPU 集群,使得百度成为了世界上第一个建立深度学习 GPU 集群的公司。几年来,百度不断在 GPU 和超级计算机方向做投入,加大深度学习的研究。
在加入百度之后,曾帮助谷歌建立 Google Brain 的吴恩达也在百度建起了「大脑」。

图片:百度大脑官网
从百度大脑的官网,我们就可以明晰的看到吴恩达在百度的人工智能研究:机器学习、语音技术、图像、自然语言处理、用户画像。
机器学习
今年 9 月份,吴恩达在百度世界大会上宣布开源深度学习平台 PaddlePaddle。PaddlePaddle 的前身是百度于 2013 年自主研发的深度学习平台 Paddle(Parallel Distributed Deep Learning,并行分布式深度学习),一直为百度内部工程师研发使用,并且已经做出了一些实际的产品,较为成熟。
据介绍,PaddlePaddle 是一个云端托管的分布式深度学习平台,支持 GPU 运算,支持数据并行和模型并行。对于序列输入、稀疏输入和大规模数据的模型训练有着良好的支持,仅需少量代码就能训练深度学习模型。
这是在谷歌宣布开源 TensorFlow 之后,又一科技巨头开源的深度学习平台。
不到一个月,百度再次宣布开源基准工具 DeepBench,可对硬件平台的深度学习性能进行评估,帮助硬件开发人员优化深度学习硬件,从而加快深度学习研究。

语音技术
「百度大脑已经有好几种不同的人工智能技术,其中比较成熟的就是我们的语音技术。」吴恩达在百度语音开放平台三周年的主题活动上说。
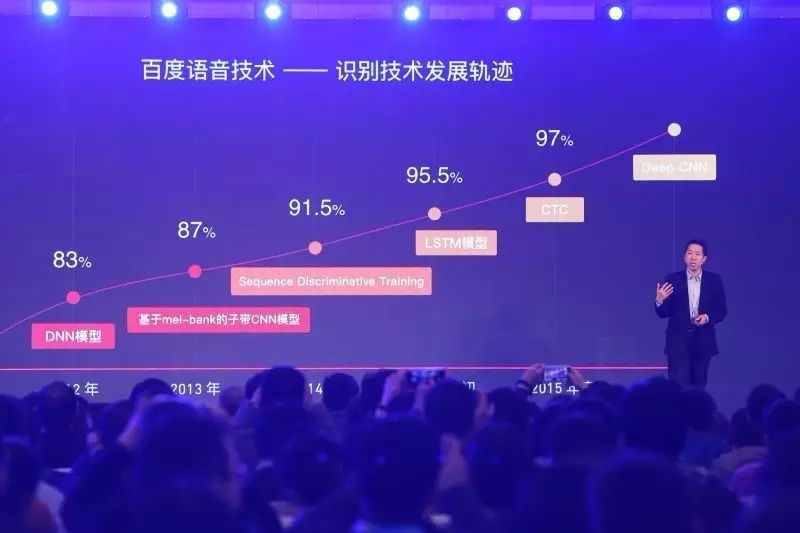
长久以来,人与机器交谈一直是人机交互领域内的一个梦想。最近几年来,随着深度神经网络的应用,计算机理解自然语音的能力也有了彻底革新。但人机的自然交互,涉及到语音方面的多项技术。在此次主题活动上,吴恩达谈到了百度在语音识别、语音合成、语音输入方面的研究。
「这几年来,我们的团队在不断地优化语音识别系统,在 2012 年开始使用 DNN 模型,后来有比较好的特征,之后开始用 Sequence Discriminative Training,也开始使用 LSTM 模型,加上 CTC,今年我们的团队开发了 Deep CNN 模型,效果在不断进步,这就是我们的语音识别系统。」
百度于 2015 年 11 月发布的 Deep Speech 2 已经能够达到 97% 的准确率,并被麻省理工科技评论评为 2016 年十大技术突破之一。
语音识别的记录不断在被刷新,今年微软在英语语识别上准确率的突破也几乎媲美人类。但是,使用计算机生成语音——这个过程通常被称为语音合成(speech synthesis)或文本转语音(TTS)——仍在很大程度上基于所谓的拼接 TTS(concatenative TTS),其中有一个由单个人录制的大量短语音片段构成的非常大的数据库,然后再将这些短语音组合起来构成完整的话语。
今年 9 月份的时候,谷歌 DeepMind 爆出在语音合成上的突破性研究——WaveNet,将机器语音合成的表现与人类之间水平的差距至少缩减了 50%。
「我们的语音合成模型也变得越来越好。这几年来我们在好几个技术方面有比较大的突破,语音合成效果变得越来越好。现在百度在中国语音合成的能力达到业界领先的水平。」据百度讲,百度情感合成技术主要聚焦在为合成语音「加入情感」,目前可达到接近真人发声效果。它们在今年早些时候曾利用此技术,复原已逝明星张国荣的声音。
2016 年,我们也看到了深度学习在图像(识别准确率、风格迁移)、自然语言处理、机器翻译(谷歌神经机器翻译系统)等其他领域取得的最新进展。
比如在自然语言处理任务上,序列到序列模型的注意实现了很大的进展。在后续的专访中,吴恩达表达了自己的看法,「从研究者的角度来看,未来几年有非常多有可能带来突破的思想,它们有可能能够以全新的方式创造出更好的自然语言处理系统。比如说,在词嵌入(word embedding)上,我们可以看到仍有很大的进展。在跨模型学习上,也有一些研究成果。当你同时学习计算机视觉和自然语言处理的时候,那是非常激动人心的。」
在研究上,吴恩达认为迁移学习和多任务学习是很好的研究方向。他拿百度的 NLP 团队在 2015 年研究举例说,「如果同时学习多个语言对之间的翻译,效果会比同时学习一个语言对的效果好。」
当时,谷歌的神经机器翻译的出现引起了业内的极大关注。但在机器之心之前对百度 NLP 团队的专访中,我们了解到百度的在线翻译系统一年前就应用了基于神经网络的翻译方法。去年百度在 ACL 会议上发表论文《Multi-Task Learning for Multiple Language Translation》,探讨用 NMT 技术解决多语言翻译及语料稀疏的问题,这也就是吴恩达上面所说的多任务学习。










