CS231n 近几年一直是计算机视觉领域和深度学习领域最为经典的课程之一。而不久前结课的 CS231n Spring 2017 仍由李飞飞带头主讲,并邀请了 Goodfellow 等人对其中部分章节详细介绍。
本课程从计算机视觉的基础概念开始,在奠定了基本分类模型、神经网络和优化算法的基础后,重点详细介绍了 CNN、RNN、GAN、RL 等深度模型在计算机视觉上的应用。
后台回复关键词“斯坦福”,下载全部课件。
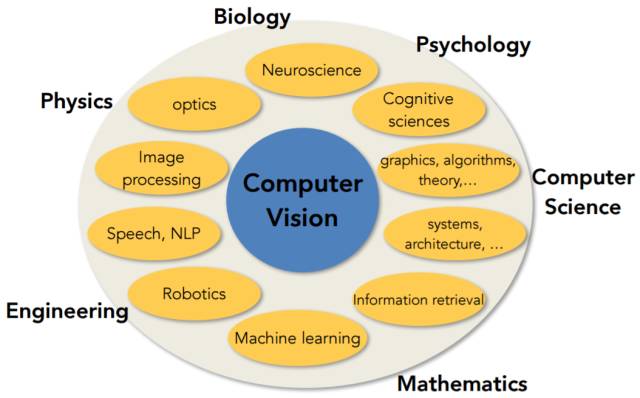
Lecture 1:计算机视觉的概述、历史背景以及课程计划
Lecture 2:图像分类——包括数据驱动(Data-driven)方法,K 近邻方法(KNN)和线性分类(Linear classification)方法

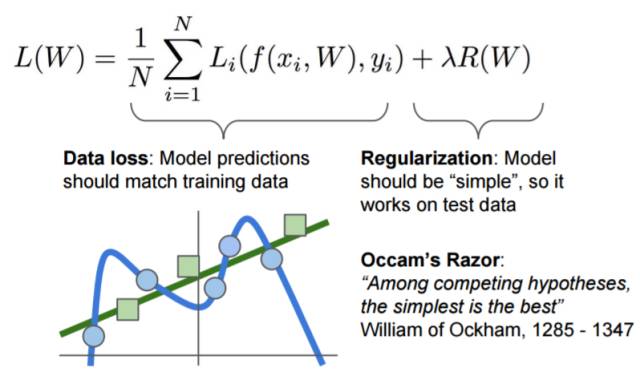
Lecture 3:损失函数和优化(Loss Function and optimization)
这一讲主要分为三部分内容:
1. 继续上一讲的内容介绍了线性分类方法;
2. 介绍了高阶表征及图像的特点;
3. 优化及随机梯度下降(SGD)。
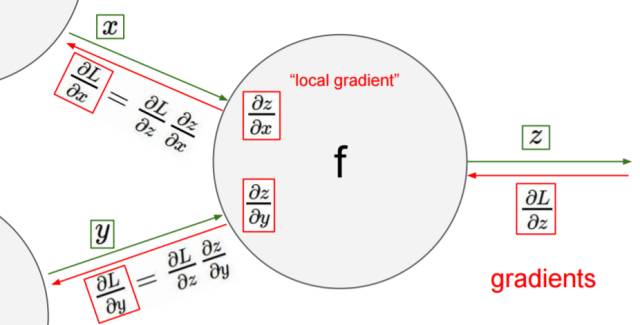
Lecture 4:神经网络
包括经典的反向传播算法(back-propagation)多层感知机结构(multilayer perceptrons)以及神经元视角。
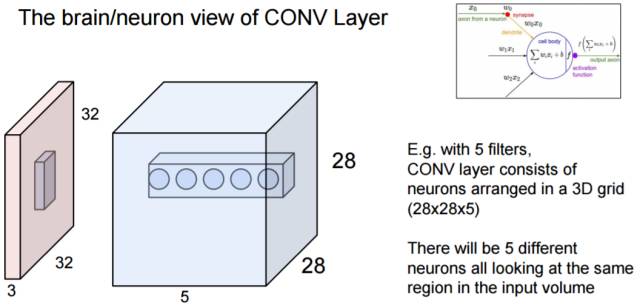
Lecture 5:卷积神经网络(CNN)
主要分为三部分内容:
1. 卷积神经网络的历史背景及发展;
2. 卷积与池化(convolution and pooling);
3. ConvNets 的效果。
Lecture 6:如何训练神经网络 I
介绍了各类激活函数,数据预处理,权重初始化,分批归一化(batch normalization)以及超参优化(hyper-parameter optimization)。

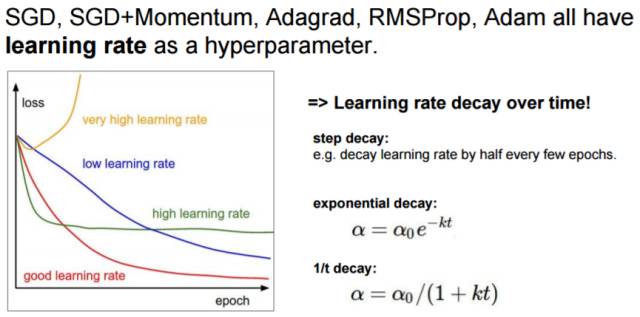
Lecture 7:如何训练神经网络 II
介绍了优化方法(optimization)、模型集成(model ensembles)、正则化(regularization)、数据扩张(data-augmentation)和迁移学习(transfer learning)。
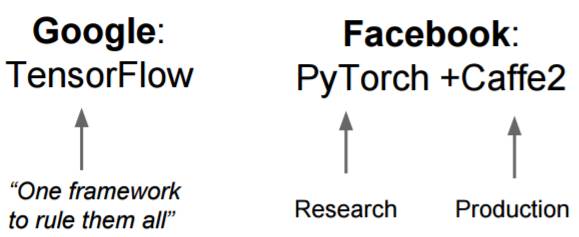
Lecture 8: 深度学习软件基础
1. 详细对比了 CPU 和 GPU;
2. TensorFlow、Theano、PyTorch、Torch、Caffe 实例的具体说明;
3. 各类框架的对比及用途分析。
Lecture 9:卷积神经网络架构(CNN Architectures)
该课程从 LeNet-5 开始到 AlexNet、VGG、GoogLeNet、ResNet 等由理论到实例详细描述了卷积神经网络的架构与原理。

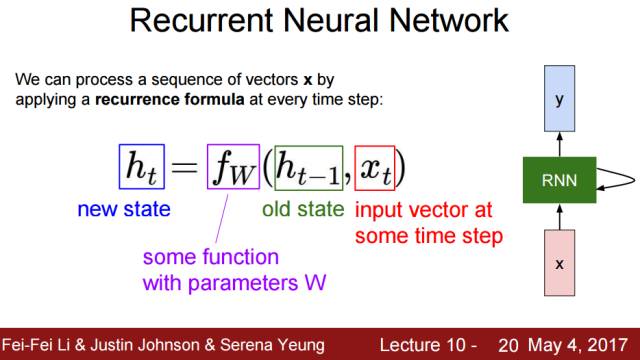
Lecture 10:循环神经网络(Recurrent Neural Networks)
该课程先详细介绍了 RNN、LSTM 和 GRU 的架构与原理,再从语言建模、图像描述、视觉问答系统等对这些模型进行进一步的描述。
Lecture 11:检测与分割(Detection and Segmentation)
该课程在图像分类的基础上介绍了其他的计算机视觉任务,如语义分割、目标检测和实例分割等,同时还详细介绍了其它如 R-CNN、Fast R-CNN、Mask R-CNN 等架构。

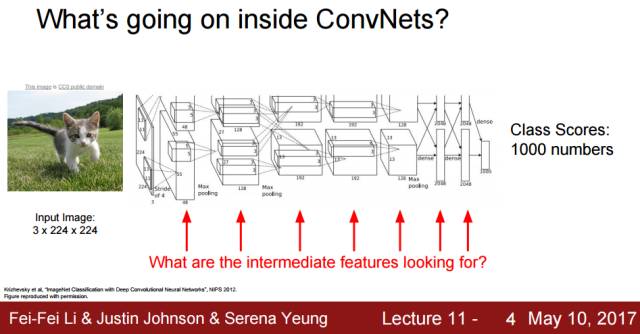
Lecture 12:可视化和理解(Visualizing and Understanding)
该部分不仅讲述了特征可视化和转置,同时还描述了对抗性样本和像 DeepDream 那样的风格迁移系统。
Lecture 13:生成模型(Generative Models)
该章节从 PixelRNN 和 PixelCNN 开始,再到变分自编码器和生成对抗网络详细地讲解了生成模型。

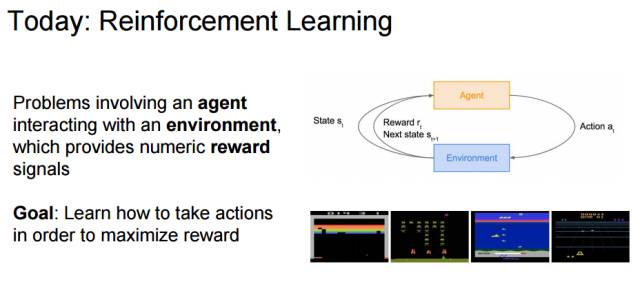
Lecture 14:强化学习(Reinforcement Learning)
该章节先从基本概念解释了什么是强化学习,再解释了马尔可夫决策过程如何形式化强化学习的基本概念。最后对 Q 学习和策略梯度进行了详细的刻画,包括架构、优化策略和训练方案等等。
Lecture 15:深度学习高效的方法和硬件(Efficient Methods and Hardware for Deep Learning)
该章节首先展示了深度学习的三大挑战:即模型规模、训练速度和能源效率。而解决方案可以通过联合设计算法-硬件以提高深度学习效率,构建更高效的推断算法等,

Lecture 16:对抗性样本和对抗性训练(Adversarial Examples and Adversarial Training)
该章节由 Lan Goodfellow 于 5 月 30 日主讲,主要从什么是对抗性样本、对抗性样本产生的原因、如何将对抗性样本应用到企业机器学习系统中及对抗性样本会如何提升机器学习的性能等方面详细描述对抗性样本和对抗性训练。











