一、引言
伴随着国家治理体系和治理能力现代化的建设进程,各级政府积极推动行政规范化和透明化,正式政策文件在政府日常事务和推动各地社会经济发展中的重要性更为凸显(杜月,2017;渠敬东等,2009)。国家政策文件要转化为具体的治理效能,需要各地因地制宜的执行。这是因为作为“文件传递链”起点的中央政策文件,其内容往往是方向性、原则性和指导性的(周业安,2000),掌握精确的、关于本地分散化知识的省级政府作为政策传递者(贺东航、孔繁斌,2011),需要根据本地的具体情况对上级发布的政策进行内容上的细化和更新(朱亚鹏、丁淑娟,2016;林雪霏,2015)。
但在文件传递实践中,却出现了部分地方政府原封不动地传递上级政策,充当文件“二传手”的现象。文件传递中的“二传手”现象一方面可能会导致部分地方虽采纳某些政策,但政策内容却与该地实际情况不符(Jansa et al.,2019)。另一方面,中间政府若在某项政策传递中扮演“二传手”的角色,会极大影响下级政府政策执行的态度和效率,从而影响国家正式政策的执行和治理效能。上述现象促使我们思考以下问题:面对涵盖社会、经济发展诸方面的国家政策,各省级政府除采纳速度的不同外,在对不同国家政策文本的细化和更新程度上有何差异?是什么机制导致部分省份原封不动地传递国家政策,而部分省份却对国家政策进行较大幅度的细化和更新?政策采纳速度与对政策文本的细化和更新程度之间存在何种实证关系?对上述问题的实证回答有助于我们进一步厘清中间政府在“文件传递链”中的角色,同时深化对动态而复杂的正式政策文件运作过程的理解。
已有政策扩散文献聚焦于政府间正式政策文件的运作过程与机制,通过考察中间政府(特别是省级政府)对各类国家政策的采纳行为,分析诸如地方特征、外部压力以及政策类型等因素对地方政府是否采纳特定政策以及采纳速度的影响(Berry & Berry,2017;Shipan & Volden,2012;朱亚鹏、丁淑娟,2016;朱旭峰、赵慧,2016)。政策扩散文献多将特定政策是否被各地采纳以及采纳速度作为研究的重点和终点(Linder et al.,2018),这相对忽略了政策传递系统中“浅层”采纳和“深层”采纳的区别,即同一时间段采纳了某项上级政策的地方政府,其对政策文本的细化和更新程度可能存在较大的差异(Glick & Hags,1991)。从这一角度而言,政策采纳测量的是政府行为的浅层维度,政策内容变化能更深入地测量政府行为。因此,欲有效回答上述问题,需要拓展传统政策扩散研究的维度,将政策采纳后政策内容变化的基本模式及背后的影响机制纳入研究视野,通过实证考察政策“浅层”采纳与“深层”内容变化间的影响机制差异,来深化对我国正式制度运作过程的理解。
近年来,数字化政策文本大数据的可得性以及文本挖掘技术的快速发展,为我们深入政策文本、基于政策文件内容量化地方政府行为提供了研究契机以及数据方法支持(Wilkerson & Casas,2017;Evans & Aceves,2016;Grimmer & Stewart,2013;龚为纲等,2019;孙秀林、陈华珊,2016;陈云松,2015;孟天广、郭凤林,2015)。基于国家和省级政府从2008年到2018年的农村政策,本研究使用词向量模型等构建“政策内容再生产”系数,以此测量省级政府在采纳国家涉农政策后对政策文本的细化、更新程度。在此基础上,本文尝试对我国纵向政府间政策内容再生产的模式和影响机制进行分析,系统考察内部因素和外部对政策内容再生产的具体影响,并进一步检验“浅层”的政策采纳速度与“深层”的政策内容再生产程度的实证关系。
二、文献评述
(一)文献传递系统中的政策采纳研究
正式政策文件是各级政府间日常交流沟通的重要手段。针对政府间正式政策文件传递的过程,已有文献主要从地方政府内部因素、外部压力等方面考察地方政府对特定政策的采纳行为。其中内部因素强调地方政府的政治、经济、社会特征等对政策采纳的影响(Berry & Berry,2017;Shipan & Volden,2012;Godwin & Schroedel,2000)。外部压力则更为强调上级或同级政府的压力和竞争等外部合法性压力对政策采纳的影响(Gilardi,2010;Shipan & Volden,2008;Volden,2006),如区域传播模型与同构模型均关注美国州政府采纳某项政策如何受到其他州的影响。不同的是,区域传播模型更为强调地理上邻近州的影响(Berry & Berry,1990),同构模型则认为相比于地理上邻近的州,特定州政府是否采纳某项政策更容易受到经济发展等各方面特征都较为相似的州的影响(Volden,2006)。
国内相关文献同样主要从内部因素、外部压力等方面考察地方政府对国家发布政策采纳行为的影响因素。朱多刚、郭俊华(2016)考察了内部决定和外部影响等两个方面对专利资助制度在各省扩散的影响,发现不同省级政府的科技创新资源拥有量、面临问题的严重性以及国家层面的重大战略决策事件等因素会影响专利资助政策在不同省份的扩散。刘河庆(2020)则基于多项农村政策同时分析了内部因素和外部因素对地方政府是否采纳中央农村政策的影响,发现除地方内部因素外,外部的压力和激励的提升同样会提高地方政府采纳特定中央农村政策的概率。
上述文献有助于我们理解中国政策文件传递过程,但仍有一系列需要深化之处。第一,政策采纳作为传统上测量政府行为的重要指标,重点关注地方政府是否采纳某项政策和采纳速度,但这仅能测量“浅层”的政府行为,在政策采纳指标下,只是充当文件“二传手”的地方政府和对国家政策原型进行较高程度细化和更新的地方政府是没有差异的,这无疑会影响政府行为测量的准确性和深入性。第二,深层政策传递的影响机制需要进行评估,如对政策采纳有重要影响的外在合法性压力对于深层次的政策内容变化有何具体影响,有待实证考察。第三,政策采纳研究将采纳速度作为重要研究变量(Berry & Berry,2017),但在政策传递和执行实践中,早期采纳者相比后期采纳者的政策执行效果并不一定更好(李林倬,2013;Glick & Hays,1991)。我们需要考察“浅层”政策采纳速度与“深层”政策内容变化的关系,进而重新审视线性的政策采纳速度在测量地方政府行为方面的具体角色。
如前所述,工业生产发生在官僚制组织中,在组织的所有者和管理者客观上依赖于工人的生产投入,而工人又由于在剩余分配中处于劣势而不愿主动投入的条件下,组织就通过一个自上而下的层级制来控制工人的行为,促使他们做出生产所需的投入。同时,工业生产之所以通过层级制组织来控制所有生产行为,另一个重要原因在于工业生产是一种复制式的生产。当然,这并不是说工业生产不需要创新,但在绝大多数情况下,工业生产都表现为对标准化产品的大规模复制;所谓创新,指的是创造新的标准化的产品,而在这种产品被创造出来之后,它仍然是以复制的方式进入市场的。正由于工业生产表现为复制,所以才会有科学管理运动所说的“唯一最佳方式”,也才会有新公共管理运动所说的“最佳实践”,因为只有在生产的内容高度一致的情况下,我们才能在不同的生产方式与实践之间做出比较。同时,无论“唯一最佳方式”还是“最佳实践”,一定都是对劳动者的生产行为做出了最有效控制的方式和实践,因为只有当劳动者的非生产行为得到最小化,所有劳动者都不要自作主张地试图创新时,组织的生产即复制才是最有效的。
(二)政策扩展与政策借用研究
部分学者注意到政策在传递过程中并非一成不变,横向同级政府间的政策扩展和借用需要得到重点关注。有研究者强调应区分政策传递系统中“浅层”采纳和“深层”采纳。通过对美国38个采纳“生前遗嘱立法”的州的政策内容进行人工编码来识别各州政策的差异,研究发现,早期采纳者倾向于颁布限制性和保守性的立法,后期采纳的州会对相关政策进行调整和扩展,使政策趋于完善和全面(Glick & Hays,1991)。还有研究者以纽约州政府制定的大规模水力压裂政策为例,关注了州政府在政策采纳后如何在政策优先事项上“加倍”,发现政策路径依赖、同伴效应以及政策类型是州政府进行政策扩展的关键因素(Arnold & Long,2019)。
另有研究者基于政策文本本身对政策扩散中的政策内容借用进行考察,研究发现,外部因素对各州政策内容借用有直接影响,各州对于联邦法院裁决为符合宪法的政策的内容借用程度显著高于其他政策(Hinkle,2015)。与此项研究强调政策借用为各州带来的政策执行优势不同,有研究者关注各州间政策借用可能带来的负面影响。该研究发现,若各州不考虑自身情况大规模借用其他州的政策内容,会对政策执行的实际效果带来较大负面影响(Jansa et al.,2019)。
政策扩展和借用的相关文献让我们进一步认识到考察政策传递过程中政策内容变化的重要性,但已有研究以同级政府间横向的政策学习和借用为研究对象,以国家政策原型为纵向的文件传递起点的政策内容变化的基本模式和影响机制仍需要进一步实证分析。另外,政策文本内容是测量政策扩展和借用的重要维度,但目前政策扩展和改造文献多未直接关注政策内容本身的变化,部分涉及政策内容的研究(Jansa et al.,2019;Wilkerson et al.,2015)也未将政策文本的词汇语境等重要信息考虑在内,如何充分而准确地挖掘政策文本信息,仍是当前研究的难点。
在“文件传递链”中,国家发布政策文件后,与乡镇等基层政府负责执行落实自上而下的指令和政策不同(陈家建等,2013),省级政府主要扮演的是政策传递者的角色(周雪光、练宏,2012;贺东航、孔繁斌,2011)。作为政策传递者,省级政府等中间政府对国家政策文件的反应模式不仅包括是否采纳特定政策以及采纳速度,而且包括在采纳政策文件后对该文件的细化和更新程度(Linder et al.,2020;Hinkle,2015;朱亚鹏、丁淑娟,2016)。中间政府对国家政策文件进行细化和更新的原因和动力在于,作为政策制定者的国家出台的各项政策往往是原则性、指导性的(李林倬,2013;周黎安,2008),和国家相比,省级政府等中间政府掌握着更为精确的、关于本地的分散化知识,同时更为了解地方本身的需求及资源状况。因此它们往往并非被动地移植或借用政策原型,而是以其作为知识起点并根据本地的具体情况对政策原型进行细化和更新(林雪霏,2015),使本地发布的政策更符合本地实际情况,而中间政府对国家发布的政策内容进行基于自身情况的修正和更新是国家鼓励和乐于看到的(周业安,2000)。
已有文献重点关注的地方政府对国家政策是否采纳及采纳速度,但这是较为浅层的地方政府对国家政策的反应方式(Hinkle,2015;Glick & Hays,1991;李林倬,2013),易于量化和监督。相对于政策采纳,地方政府对政策原型的细化和更新是更为深层的中间政府对国家政策的反应方式,较难进行量化和监督。新制度主义文献强调除组织自身效率外,外在的合法性压力对组织行为同样有重要影响,有研究者发现,在面临联邦政府自上而下要求的压力时,组织会为满足联邦政府的要求而不是为内部组织运作而制订政策文件(Meyer & Rowan,1977)。就这一角度而言,由于政策采纳易于被上级政府量化和监督,在压力型体制下,合法性压力对政策采纳有重要的影响(DiMaggio & Powell,1983),已有政策研究也发现上级政府自上而下的压力和信号对我国地方政府的政策采纳的重要影响(刘河庆,2020;朱旭峰、赵慧,2016)。鉴于更深层次的政策内容的变化较难被上级政府量化和监督,对于同一时期往往要同时面对多项上级政策的地方政府而言,选择对不同国家政策原型进行何种程度的细化和更新可能更多是基于自身因素的考量,与地方政府自身的特征及其政策偏好高度相关,而较少受到外在合法性压力的影响。
除此之外,以往国内外政策扩散研究多以政策扩散速度的快慢作为研究的主要着力点(Berry & Berry,2017;Shipan & Volden,2012;朱旭峰、赵慧,2016),但在我国文件治理的实践中,仅凭线性的政策扩散速度并不一定能有效反映地方政府行为(周飞舟,2019),地方政府快速采纳某项国家政策也不一定意味着其会对该政策原型进行较大程度的内容细化和更新。李林倬在某县级卫生局文件制定的案例中观察到,面对上级发布的并非该局真实工作重心的文件,该卫生局通过迅速匹配上级政府发布的政策或者在上级政府检查前突击发文的方式,掩盖了该局的实际工作重心(李林倬,2013)。换言之,面对部分国家政策,地方政府可能由于合法性压力而快速采纳相应的政策原型,但政策文件的快速出台不一定符合地方政府的真实执行意愿,这一情境下地方政府没有足够的动力对上级政策原型加以大幅度的细化和更新。考察政策采纳速度与政策内容变化的关系有助于我们重新审视以往被大量研究的线性的政策采纳速度在测量地方政府行为上的具体角色。
综上,尽管相对于政策采纳,各地对国家政策原型的细化和更新程度较难测量,但将其纳入研究范畴非常必要,实证考察文件传递过程中政策内容变化的模式和机制有助于突破政策采纳这一传统维度,更为深入地了解我国正式政策文件的运作过程。
三、政策文件传递中的政策内容再生产
(一)“政策内容再生产”的提出
国家发布相关政策后,各地方政府除采纳速度的差异外,同样可能存在对政策内容细化和更新程度的差异,本研究将纵向“文件传递链”中作为政策传递者的中间政府对上级政府发布的政策文件进行的细化和更新概念化为“政策内容再生产”。结合已有文献和研究方法,本研究使用“文本相似度”来测量政策内容再生产程度(Hinkle,2015)。特定省级政府发布的政策文本与国家政策原型间的文本相似度越高,则代表地方政府对国家政策原型的细化和更新较少,也即政策内容再生产程度越低。特定省级政府发布的政策文本与国家政策原型间的文本内容相似度越低,则代表地方政府对国家政策原型的细化和更新较多,也即政策内容再生产的程度越高。
(二)通过词向量模型测量政策内容再生产
如何基于政策文本数据准确测量政策内容再生产程度是本文的一个难点,传统文本相似度计算中较多运用词匹配算法,词匹配算法的核心是基于两篇文章中共同词汇出现的频次来计算文本的相似度。尽管词匹配算法因简单易用而得到广泛应用(Grimmer & Stewart,2013),但不断有研究指出,基于词匹配算法的文本相似度计算结果很大程度上取决于两篇文本的词汇重复率,难以将词汇间固有的语义相关信息考虑在内,同时难以处理一义多词、近义词等情况,因此会极大地影响结果的准确度(谷重阳等,2018)。
为解决上述问题,我们将近年来兴起的词向量模型等神经网络模型应用到政策文本数据的分析中,基于政策文件中词汇的向量表示来构建政策内容再生产指标。词向量模型的基本思想是将文本作为单词序列提供给单词嵌入层,该层将每个单词映射为向量空间中的实数向量,这一模型减少了文本的维数,同时保留了单词间的语义关系,进而有效地考虑了文本中的词汇语境等信息。Word2vec是由米可洛夫等提出的应用较为广泛的词向量模型(Mikolov et al.,2013),包括CBOW和Skip-gram等两种分布式词汇表示学习模型。上述两个模型旨在根据词语的上下文信息将之分配到向量空间中,上下文越接近的词汇在向量空间中的位置也越近。以Skip-gram模型为例,Skip-gram模型旨在利用单词序列{w1,w2,……wN}中某个特征词的词向量(wn)来预测该特征词上下文相关词汇的所对应的向量(wn+j),并通过最大化全局预测概率来学习词向量(刘知远等,2016):
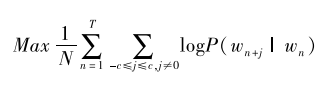
其中,c表示训练窗口,训练窗口越大,就意味着训练时涵盖更多的上下文词汇,从而具有更高的精确度,但也会增加训练时间。本研究采用Word2vec模型对政策文本数据(包括所有国家发布的政策文本和地方政府发布的政策文本)进行训练,在对政策文本进行训练前,设置训练窗口为5,得到政策文本中词汇的100维实数向量表示。
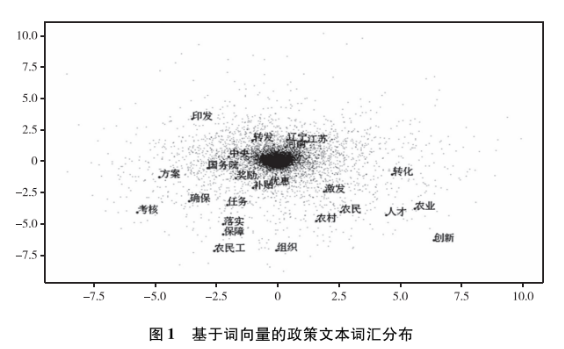
在图1中,我们通过PCA降维的方法,将政策文本中词汇的100维向量展示在二维空间中,并分别挑选了代表政策发布主体、政策目标、政策手段等方面的词汇显示其在二维空间中的具体位置。由图1可见,在二维空间中,语义相近的词汇在向量空间中的位置更近,本研究所训练的词向量模型可以较好地保留与呈现词汇间的语义关系。
得到政策文本中词汇的向量表示之后,本文参照库斯内尔等研究者(Kusner et al.,2015)的方法,基于文档中词汇的向量表示来计算文档间的相似度。文档相似度的计算借用词汇移动距离(Word Moving Distance,WMD)算法。该算法将文档看成词的一个分布,根据之前得出的文档中词汇的向量表示,可以计算两个词之间的语义距离,将词之间的语义距离视为词匹配的移动代价。同时任意两个文档都可以根据词之间的移动代价计算一个总的移动代价,文档中词汇之间的移动代价即为文档的相似程度,移动代价越小,文档越相似。
依据上述方法,本研究在得到所有政策文本中词汇的词向量表示的基础上,对国家发布的特定政策文本以及不同省政府发布的文本进行基于WMD算法的计算,进而在较好地保留词汇语境信息的前提下测量地方政府和国家政策文本间的政策内容再生产程度。
(三)政策内容再生产的影响因素
生成政策内容再生产系数后,我们将尝试对以下问题进行考察。相较于政策采纳和横向的政策借用,政府间纵向政策内容再生产的影响机制是什么?“浅层”政策扩散速度与“深层”政策内容再生产这两种省级政府对上级政策的反应模式间有何种关系?本文将从地方政府内部的经济能力、市场化程度、城镇化程度、执行动力以及来自上级政府的外部压力和激励等视角来对政策内容再生产的影响机制进行考察。
从地方政府内部因素的影响来看,由于对国家政策原型进行内容再生产的主体是地方政府,内容再生产程度的高低会受到地方政府自身经济能力、治理效率以及政策偏好的影响。已有文献在考察地方政府内部因素影响时常以地方政府人均GDP等单一指标来测量地方政府特征(刘河庆,2020),但地方政府特征不止是经济能力,多维度测量地方政府特征能帮助我们更深入地理解政策内容再生产的过程。以本研究为例,地方政府对国家涉农政策文本数据进行何种程度的内容再生产,除地方经济能力的影响外,城镇化程度等反映该地农村及农村人口比重和重要程度的因素同样可能有重要影响。基于此,我们将同时考察地方政府内部的经济能力、市场化程度、城镇化程度和执行动力等多个内部因素对政策内容再生产的影响。
从来自上级政府的压力和激励的影响来看,尽管国内外文献均强调上级政府的信号和压力对下级政府采纳特定政策的影响(Shipan & Volden,2012;朱旭峰、张友浪,2015),但相对于“浅层”的政策采纳,地方政府在采纳特定上级政策后,对政策内容的细化和更新程度较难被量化和监督,因此来自外部的行政压力和经济激励对政策内容再生产的影响相较于政策采纳可能是有折扣的。正因为外部因素影响的不同,政策采纳速度与政策内容再生产程度的关系也可能是非线性的。接下来本文将实证考察政策内容再生产的具体影响机制,并进一步检验政策采纳速度与政策内容再生产间的具体关系。
四、数据、变量与模型
(一)数据
本文采用的数据包括国家和各省2008-2018年涉农政策数据、历年政府工作报告以及各省不同年份的统计年鉴数据。
笔者按照以下步骤收集和整理涉农政策数据。第一步,在国家和省级政府的官方网站检索“乡”“镇”“农”“村”等关键词,采集各网站相关文本,保留文件标题、发文字号、发文日期、文件内容、文件主题分类等信息。第二步,对采集的政策文本数据进行清理。首先依据政策的发文字号等信息删除新闻公告等文件。其次,根据政策文件的发文日期,分别保留从2008年6月到2017年12月的国家涉农政策文件以及从2008年6月到2018年4月的各省涉农政策文件。同时,人工审核政策标题等信息,删除只针对少数特定省份的非全国性涉农政策文件。第三步,删除数据库中的重复政策文件。经过上述步骤,初步形成包括国家和省级政府的涉农政策文本数据库。
根据研究设计,笔者进一步对上述数据库进行如下处理。第一,以标题关键词匹配的方法,识别各省与国家涉农政策标题中的关键词并进行匹配,匹配结果反映各省对国家各项涉农政策的采纳情况。若某个省份采纳特定某项政策,我们将相应省份和与其对应的国家政策的发文时期、发文机关、发文字号、政策标题、政策内容等同时纳入数据库。第二,本文研究对象为各省对国家政策原型的政策内容再生产程度,针对每项国家政策,并不一定每个省都会推出对应政策,因此我们将以政策为基本单位,分析采纳特定国家涉农政策的省份所发布的文本与国家政策文本原型之间的内容差异(1206个有效观测值)。第三,根据上文所提及的基于词向量模型的文本相似度构建方法,在对所有政策文本进行中文分词、停用词清理等步骤之后,分别计算每个农村政策的国家发布文本和所采纳省份发布文本的政策内容再生产程度。第四,将上述数据与各省不同年份人均GDP等年鉴数据依据省和年份进行匹配,生成本文的最终数据库。
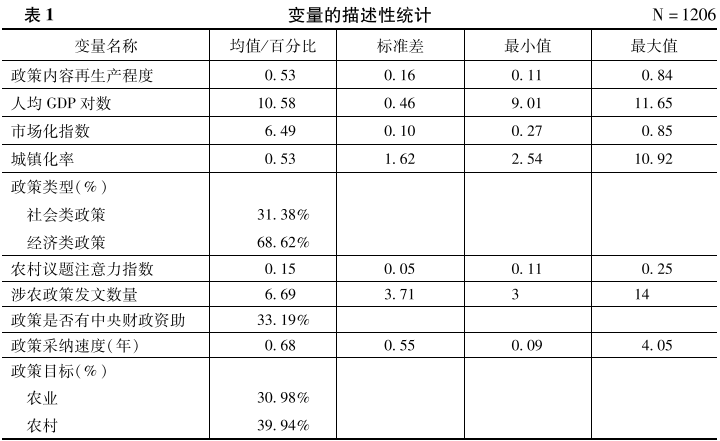
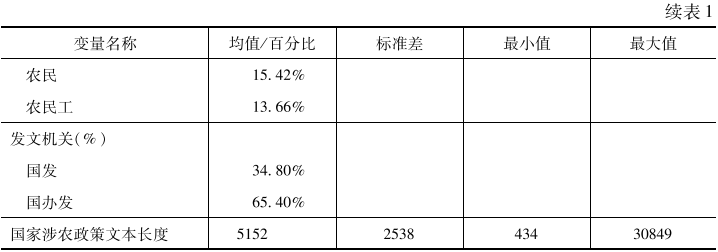
因变量为政策内容再生产程度,本研究将其操作化为“1减去特定政策的国家发布文本和省份发布文本的文本相似度”,该变量反映特定省政府采纳特定国家农村政策之后对政策文本的细化和更新程度,为连续变量。
本文的解释变量分为三类。第一类为特定年份省份人均GDP、市场化指数、城镇化率以及政策执行动力等反映省份内部因素的变量。第二类为农村议题注意力系数、上年度国家涉农政策发文数量以及政策是否有中央财政资助等反映外部因素的变量。第三类为特定国家政策被各地方政府采纳速度等反映政策采纳速度的变量。
特定年份省份人均GDP。反映省份的经济能力,操作化为省级政府采纳某项国家涉农政策时上一年度人均GDP的对数。
特定年份省份市场化指数。各地的市场化指数能较好反映各地方政府的市场化程度、治理效率(王小鲁等,2019),操作化为省份采纳某项国家涉农政策时上一年度市场化指数。
特定年份省份城镇化率。测量方式为特定省份采纳某项国家涉农政策时上一年度的城镇人口占总人口的比重。
政策类型。反映地方政府对不同涉农政策的执行动力,笔者依次对各项国家涉农政策的标题进行判读,分为社会类政策(编码为0)和经济类政策(编码为1)两类。
农村议题注意力指数。反映上级政府对农村议题的关注度和注意力。测量方法为对各年度国务院政府工作报告文本进行主题模型分析,结合混乱度等指标选取主题个数(Blei et al.,2003)。根据分析结果,识别主要涉及农村议题的主题,计算并加总各年度工作报告中的涉农主题概率,进而以该概率衡量每年国家对涉农议题的注意力。
国家涉农政策发文数量。政策发文数量同样是衡量政府注意力的重要指标,本研究通过上年度国家涉农政策发文数量来从另一个侧面衡量国家对农村议题的注意力程度。
政策是否包括上级财政资助。具体操作化方法如下:在国家涉农政策文本中搜索“中央直接补贴”等关键词,若包含相关关键词则编码为1,若无则为0。部分国家涉农政策在为地方提供资助的同时也要求地方政府提供配套财政支持,因本文主要考察自上而下的财政激励对政策内容再生产程度的影响效应,该类国家涉农政策编码为0。
政策采纳速度。具体操作化过程为我们将国家发布特定涉农政策的时间与各个地方政府具体采纳的时间进行对比,生成地方政府采纳与国家发布相差的具体天数,进而进一步换算成以年为单位的政策采纳速度,为连续变量。
本研究的控制变量包括国家涉农政策的目标对象、发文机关及文本长度。
国家涉农政策的目标对象。笔者将涉农政策的目标对象处理为类别变量,将农业、农村、农民和农民工分别赋值为0、1、2、3。在实际操作化中,若国家涉农政策主要与发展现代农业、粮食安全等主题相关则归为农业类别;若主要与农村环境保护、农村金融发展等主题相关则归为农村类别;若主要与农民收入、减轻农民负担等主题相关则归为农民类别;若主要与农民工职业技能提升、返乡创业等主题相关则归为农民工类别。
国家涉农政策的发文机关。操作化时将国务院发文编码为0,将国务院办公厅发文编码为1。
国家涉农政策文本长度。该变量反映国家农村政策文本原型的详细程度,在实际分析模型中采用文本长度的自然对数形式。以上变量的详细描述性统计结果见表1。
(三)模型设定
鉴于政策内容再生产程度为介于0和1之间的连续变量,且近似于正态分布,本研究采用OLS模型进行分析。同时考虑到本文的分析单位包括政策以及政策发布的省份和年份两个基本层次,因此使用二水平随机截距OLS模型,第一层次的模型为:
在公式(1)中,y
ij
代表特定年份的省份j所发布的政策i的内容再生产程度;x
kij
为本文主要解释变量,包括省份内部因素变量、外部因素变量以及政策采纳速度等;x
lij
为相关控制变量;α
kj
为主要解释变量的系数;α
lj
为相关控制变量的系数;e
ij
为随机误差项。
在公式(2)中,β
0
为第二层次的截距,u
0j
表示特定年份的省份j所造成的随机效应的截距变化。
五、实证分析结果
(一)政策内容再生产的时间及空间差异
本节首先分析政策内容再生产程度在时间和空间上的差异。图2呈现了政策内容再生产程度的时间差异,线段中间的菱形代表该年度国家发布的农村政策的政策内容再生产程度的均值,线段代表95%置信区间。由图2可见,不同年度发布的国家涉农政策在省级政府的政策内容再生产程度的均值相对平稳。值得注意的是,近几年发布的国家涉农政策的政策内容再生产程度降低,可能与政策采纳速度有关。我们将会在下文政策采纳速度与政策内容再生产的关系部分进行详细探讨。
图3进一步将各个省份划分为东、中、西三个地区,以呈现政策内容再生产情况的区域差异。由图3可见,西部地区和中部地区对国家涉农政策的再生产程度的均值差异不大,而东部地区对国家涉农政策的再生产程度的均值则远高于西部和中部地区,这初步体现出不同地方政府在政策内容再生产方面的差异。
本研究首先使用二水平随机截距OLS模型来考察省份内部因素对政策内容再生产的影响。其中模型1为只包括控制变量的基础模型,模型2到模型5在模型1的基础上增加了人均GDP对数、市场化指数、城镇化率以及政策类型等变量。
模型1结果显示,政策目标对象对政策内容再生产程度有显著影响,相较于政策目标对象为农业的政策,政策目标对象为农村、农民以及农民工的政策内容再生产程度均更低。政策的发文机关无显著影响,而涉农政策的文本长度则对政策内容再生产程度有显著的负向影响,政策文本长度越长,相应的政策内容再生产程度越低。
模型2和模型3分别分析省份人均GDP对数、省份市场化程度对政策内容再生产的影响。从模型结果来看,在基础控制变量保持不变时,省份人均GDP对数和省份市场化程度均对其政策内容再生产程度呈显著正向影响。
模型4为省份城镇化程度模型。模型结果显示,在控制其他变量的基础上,省份城镇化率越高,其政策内容再生产程度越高。城镇化率是反映农村及农村人口在该地区的比重和重要程度的重要指标,从结果来看,城镇化率低的地区,也即农村及农村人口比重较高的省份,比其他省份对国家涉农政策的内容再生产程度反而更低。
模型5考察了政策类型这一代表省级政府内在执行动力的变量对政策内容再生产的具体影响。结果显示,政策类型对政策内容再生产程度呈显著正向影响,即相较于社会类政策,各地方政府更倾向于对经济类涉农政策进行更高程度的细化和更新。
本研究同时使用二水平随机截距OLS模型来考察外部因素对政策内容再生产的影响。表3的模型1分析农村议题注意力指数对政策内容再生产的影响。结果显示,农村议题的注意力指数对政策内容再生产无显著影响(在全模型即模型4中同样不显著)。
模型2考察上年度涉农政策发文数量对政策内容再生产的影响。结果显示,上年度涉农政策发文数量的提升会显著降低政策内容再生产程度(系数为-0.008,P<0.01)。
模型3则重点考察外部经济激励即各项涉农政策中是否包括中央财政资助对政策内容再生产程度的影响。结果显示,该变量对政策内容再生产有显著的负向影响(系数为-0.025,P<0.10)。









