本文阿里巴巴技术论坛整理文章,首发于CSDN,未经许可禁止任何形式的转载。
本次为大家分享《双11媒体大屏背后的数据技术与产品》。阿里巴巴从2009年开始双11产品大促,从最初5千万的产品成交额,到2016年的1207亿的产品成交额,可能逍遥子自己也想不到,居然一不小心把事情搞这么大。
在2014年,也就是IPO元年的时候,我们数据技术与产品部团队开始承担双11的数据工作。因为是IPO的第一年,公司非常重视,决定要做现场直播。刚接到现场直播的数据媒体大屏任务时,我们团队也非常紧张,紧张的同时也花费了大量时间进行准备。但不巧的是在那一年11月10号23点50分的时候,前端还出现了问题,前端展示的趋势图突然显示异常了,所有人都不知道是怎么回事,于是开始紧急检查,在最后5分钟的时候检查出了问题所在,在最后的5分钟内,前端工程师紧急将这个bug修改完成。当时所有人都有一种非常崩溃的感觉,所幸那年的直播过程中数据媒体大屏并没有出现什么太大问题。但是一些服务于商家的数据产品,比如生意参谋,还有服务于小二的阿里直播厅等数据产品因为巨大的流量出现了延迟问题。这些问题的出现都是计划外的,如果是计划内的那就不叫故障而叫做服务降级了。
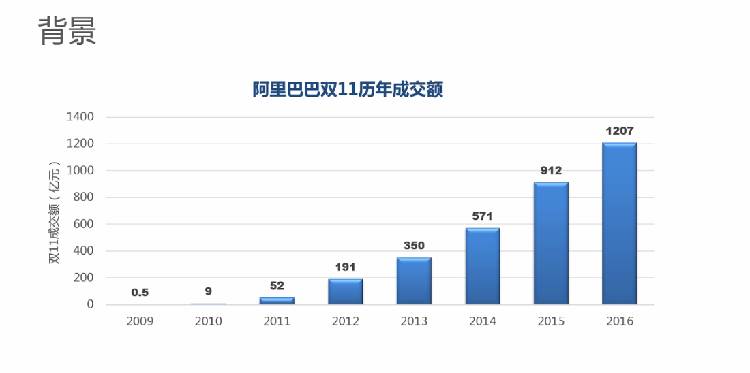
2014年的媒体大屏总体效果还是非常好的,从这之后阿里巴巴每年双11都会举办媒体大屏的活动而且是现场直播。当然媒体大屏上的数字是年复一年地增大,面对如此巨大的数字,很多人就会质疑我们的数据准确性和真实性。包括美国证监会在内的监管机构也是一样,他们随时都会来检查我们的数据,甚至于连代码也会一行一行地进行检查,所以每年双11的代码都会封存起来以备检查。
整体而言,对于实时计算,需要面临很多挑战。这其中最重要的有四大挑战:海量、稳定、准确和及时。
海量数据的挑战是显而易见的,这8年来,从整体交易额就能看出数据量也是数千亿地进行增长的。而因为需要面对电视媒体的现场直播,所以在稳定性方面也不能出现任何的差错。在准确性方面,正如刚才所提到的包括美国证监会在内的监管机构会随时检查我们的数据甚至是代码,所以数据的准确性也是要求非常严格的。而及时性则是说从0点开始,必须保证在5秒内媒体大屏上的第一个数字就需要开始跳动,因为这时直播就开始了,而到24点时数据就必须停止展示,所以需要将数据在最短的时间内算好。以上就是我们在实时数据计算方面需要面对的四大挑战。
那么又该如何去应对这些挑战呢?接下来从三个方面数据链路、数据模型和保障措施介绍应对实时计算的挑战的方法。
下图是数据实时计算的链路,这张图其实也包含了离线计算的链路。从左到右来看这张图,数据链路的开始部分,也就是日志的同步和DB数据同步。目前日志文件的同步全部采用增量文件同步的方式,这一过程可以依靠一些开源的工具完成日志的增量同步;而对于DB数据的同步而言,则是既有增量数据同步的方式也有全量数据同步的方式。增量数据同步的工作是由阿里内部的DRC产品承担的,而对于全量的数据同步,阿里也有自己的数据工具,比如说DataX,它可以负责将数据定时同步到批量计算引擎中。
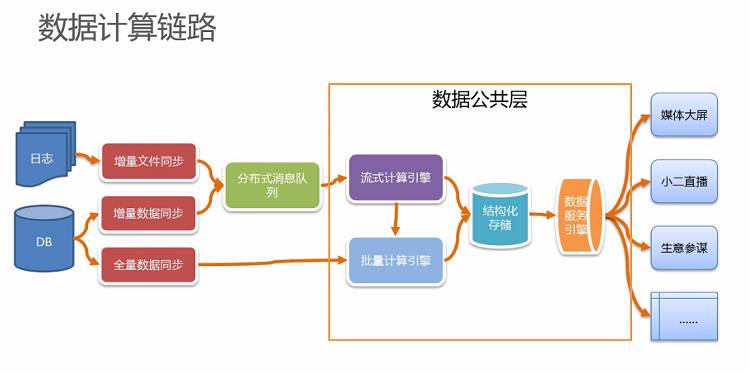
接着实时数据同步的后面是分布式消息队列,也就是消息中间件。分布式消息队列的主要功能是将消息存储起来,使得一份消息可以供多个的下游进行订阅,比如流式计算引擎也是消息队列的下游中的一方,而在正式的生产环境,其他的数据计算引擎也可以订阅消息。
图中框起来的这部分称为数据公共层,数据公共层包括有流式计算引擎、批量计算引擎以及结构化存储和数据服务引擎。数据公共层所要完成的重要工作基本都在这些地方完成,其中流式计算引擎通俗讲叫做实时计算,它做了很多计算的工作,数据的准确性和实时性很大程度上取决于数据公共层。数据计算的结果存放在结构化存储中,这里我们使用的是HBase来存放计算结果数据,批量计算引擎计算的最终结果也会同步到结构化存储里面,对于结构化存储而言,则可以使用HBase或者是MySQL集群等。最后当数据产品需要计算结果数据时,是不允许对结果数据进行直接调用的,需要通过内部的数据服务引擎才能得到数据服务,后面也会分享阿里巴巴的数据服务引擎是如何对外提供服务的。在数据公共层之后的数据接口就会提供给媒体大屏、小二直播以及生意参谋等数据产品以及阿里巴巴数据运营的其他的产品,整个数据计算的链路大致就是如此。
接下来分享一下,数据实时计算链路上一些比较重要产品。
➤
增量数据同步
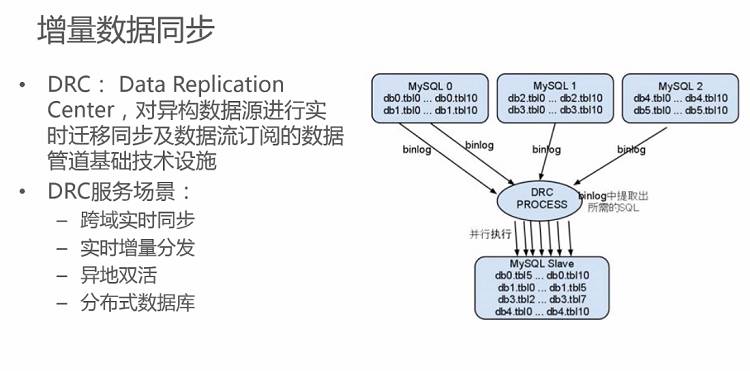
首先是增量数据同步这款产品,目前我们使用的是DRC,其全称是Data Replication Center,它负责对异构的数据源进行实时的迁移同步以及数据流订阅的数据管道基础技术设施。它最重要的服务场景有:跨域实时同步、实时增量分发、异地双活以及分布式数据库。
右侧的图是最初使用MySQL集群进行数据同步的版本,此时其已经具备增量数据同步的基本功能。其进行增量数据同步的主要原理就是对binlog进行实时解析,在解析完成之后将产生的数据同步到MySQL的备库里面,这样就能完成主备数据库的实时同步。
➤
分布式消息队列
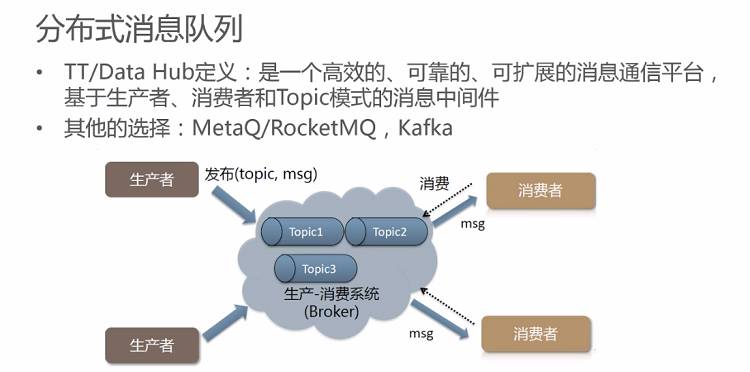
接下来分享一下分布式消息队列的一款产品——TT/Data Hub。大家可以在阿里云上使用到付费版的Data Hub产品,这个产品其实是一个消息中间件,其主要的特性是高效、可靠、可扩展,并且是基于生产者、消费者和Topic模式的消息中间件。Topic模式是区分于点对点模式的,Topic模式可以使得消息在经过一次发送之后可以被多次消费,一个消息源可以供多个下游订阅。
当然对于分布式消息队列而言,也有很多其他的选择,比如MetaQ也就是阿里巴巴刚刚捐献给Apache基金会的RocketMQ,它也是一款非常优秀的消息中间件;另外还有很早之前就比较出名的Kafka等。对于一个优秀的架构师而言,架构设计肯定不是照搬照抄的,需要适应不同的业务场景进行合理的架构设计,结合不同产品的特性选择最适合于场景的产品。比如我们在内部对于RocketMQ和Kfaka进行测试时发现:Kfaka消息中间件在消息量比较少的情况下性能比较好,其单机的QPS会非常高,但是在Topic订阅量非常高,业务比较复杂的情况下,Kfaka的吞吐量则将会急剧下降,而RocketMQ在处理复杂的订阅关系和业务时,却能保证线性的扩展。
➤
流计算引擎
接下来介绍使用的流计算引擎产品,我们当前使用的是Galaxy平台。Galaxy是阿里云的通用流计算平台,这个产品最重要的特点是易用性非常高,支持SQL模式。大家都知道流计算的开发成本相对于离线计算而言还是比较高的,一般而言都需要使用Java写很多代码,所以有很多同学就需要重新学习Java,而对于只会Python或者SQL的同学就无法进行开发流计算的任务。而Galaxy是支持SQL模式的,这样掌握SQL的同学就可以完成流计算开发任务了。除此之外,Galaxy支持数据准确性高的模式,还可以定制模式,另外可以支持集群线性扩展以及容错和多租户等,并且可以进行资源隔离。当然对于流计算产品而言还有一些其他的选择,比如JStorm、Flink以及Spark Streaming。

➤
结构化存储
结构化存储部分,也就是流计算或者批量计算引擎最后需要将数据存放到地方。我们选用的是HBase,大家当然也可以选用阿里云的OTS,也就是开放结构化数据服。OTS是构建在飞天大规模分布式计算系统之上的海量结构化和半结构化数据存储于实时查询的服务。OTS以数据表的形式来组织数据,保证强一致性,提供跨表的事务支持并提供视图和分页的功能来加速查询,非常适用于数据规模大且实时性要求高的应用。
接下来从第二个层面也就是数据模型层面进行分享,聊一聊面对海量数据进行快速而又准确的计算需要面对的挑战。
➤
实时数据公共层
提到实时数据公共层,大家往往会问为什么需要做数据公共层这个问题。其实阿里巴巴的数据业务是非常复杂的,阿里有很多像来自于电商的数据,这些数据往往很多BU也都需要使用。在很早的时候,很多部门往往会自己从源头计算一遍来获取这些数据,也就相当于烟囱模式的开发。这样的开发模式有一个优点就是效率非常高,因为不需要依赖其他的任何团队就能获取想要的数据,开发出想要的功能,但是这样的缺点也非常明显,也就是会导致非常多的重复开发和计算。当时我们的团队在做离线计算的时候发现,当时整个阿里巴巴集团的离线计算集群每年的增长速度是2.5倍,大家可以算一下,经过5年这个数据量会是原来的多少倍呢?大约会是原来的100倍,假如在最初的一年在离线集群数据服务器上的投入是10个亿的话,经过5年之后这上面的投资将会达到一千亿。所以我们在离线计算方面做了实时数据公共层这个项目,将离线计算里面的一些公共的模型抽象出来由我们团队负责呈现,建设好之后将这些公共的模型提供给其他的BU以及业务部门使用。
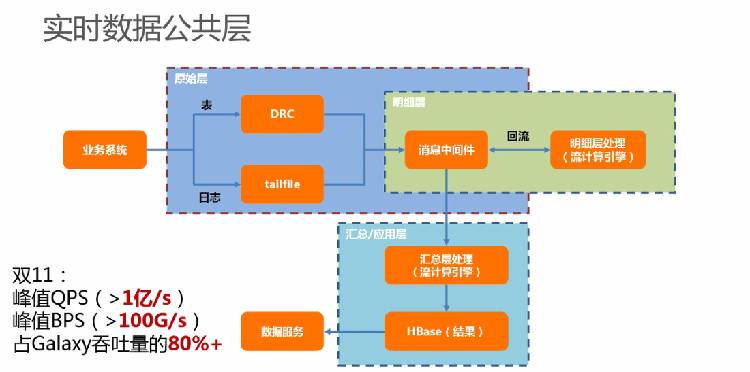
而对于实时数据而言,构建数据公共层的隐患也是非常多的。实时计算集群规模比较小,离线计算集群可能是几千台,而实时计算集群可能在开始时只有几十台机器,最多也就上百台,但是实时计算集群的增长速度远远超过离线计算集群的增长速度,可能会是离线计算集群增长速度的10倍,以这样的增长速度实时计算集群很快就可以超过离线计算集群,所以这个成本将会更加恐怖。
所以在实施离线数据计算公共层项目的同时也开始了实时数据集计算公共层的构建。从上图中可以看到,业务层的数据表经过DRC实时、日志通过tailfile同步到消息中间件,公共数据层里面的明细层会对这些数据进行第一次处理,明细层处理完的数据结果还会回流到消息中间件。也就是说对于下游的使用者而言,明细层处理完成的数据就形成了一个新的数据源,而且这个新数据源和原始数据源相比,进行了很多解析和处理的工作。
比如一笔交易订单过来,其背后可能会有10条相关数据会产生,而这10条数据其实可能就是为了得到一些比较简单的数据比如交易的金额,而在这背后其实需要明细层进行很多复杂的运算,这个运算最后的结果回流到消息中间件之后可能就变成了一条简单的数据,如此就可以供下游非常方便地使用。如果不做这样的工作,可能每一个下游都需要处理这10条数据记录,那么集群的规模就需要上百倍地增长。通过实施数据公共层进行数据处理之后,下游应用只要订阅明细层的基础数据就可以了。
汇总层也是这样,汇总层处理的数据会存放在HBase提供对外的数据服务,如果下游想要使用汇总数据就可以直接访问数据接口不需要自己再进行计算。
在双11的时候,实时数据层QPS的峰值超过一个亿,BPS每秒钟超过一百G,占到整个Galaxy吞吐量的80%多。如果没有实时数据公共层,Galaxy集群的规模可能需要目前的上千倍。
➤
实时计算事务处理
实时计算事务处理机制是保证数据准确性的最重要工作。因为当一切正常的时候,事情往往会很简单,但是通常情况下事情却不会那么简单,比如网络中断时,源头的数据会需要重发;再比如消息中间件可能无法保证数据准确性达到exactly once,这个时候的很多工作就需要流计算的开发同学自己来做,这时就需要实时事务处理的机制了。我们从数据源头到中间聚合的过程以及最后的结果都使用了一些策略来提升最后数据结果的准确性,比方说数据源这个层面,采取了元数据信息schema统一管理,也就是对于消息中间件的数据偏移量进行统一管理,这样可以记录数据偏移的位置。当某个事务需要重新处理的时候,我们能够知道数据从哪一个位置重新进行计算,而不会全部从头开始。另外我们还做了从ZK切换到HBase的工作,因为ZK的性能跟不上,所以需要切换到HBase来满足业务发展的要求,在完成切换之后,事务处理性能有了很大程度的提升。另外还实现了业务时间监控报警的功能,对于实时计算的数据,要判断是否有延迟其实要看这一批量的数据最近一次更新的时间,比如在21点的时候发现这个数据最后处理更新的时间是20点,就可以发现这个数据已经有一个小时的延迟了,如果数据延迟超过了设置的阈值,就会报警。










