hectorhua,Python中文社区专栏作者,研究生毕业,现居北京。目前在互联网企业,擅长领域python数据抓取,清洗整合。
博客地址:http://www.jianshu.com/u/514ecd998ba0
本文涉及的技术比较简单,抓取方面没有使用任何框架,因为只是临时性的任务,数据统计方面使用了Tableau,统计维度简单,比较容易上手。按数据抓取和数据分析两方面:
一、数据抓取
我抓取的数据源是某汽车门户网站口碑网页,内容广泛而详尽是这家网站的特点。通常描述或定位一款汽车的顺序为品牌->车系->车型,比如大众->迈腾->迈腾 2016款1.8TSI智享豪华型,该网站的口碑是具体到每一款车型的,并对每一款车系有一个整体口碑评分。我抓取的数据就是针对每一款车型的所有口碑数据,包括量化的评分和非量化的文字评论。如下面一条具体的口碑内容:
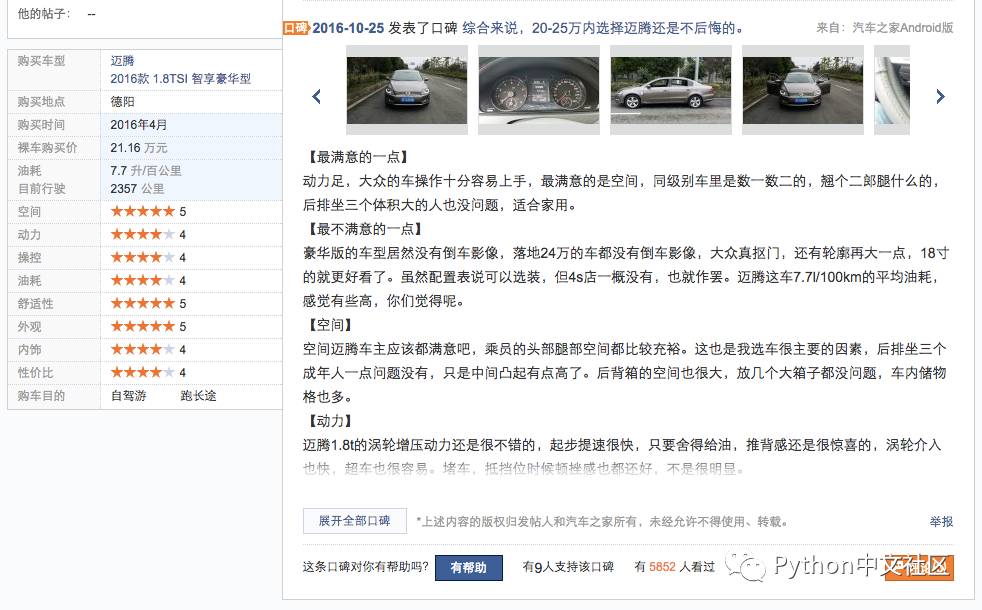
可以看到左侧有8项关于汽车的评分是量化的,右侧有各维度的文字评论是非量化的,需要后期自然语言分析。左侧的评分按照车型、车系归类后,可形成一份初级的口碑评分数据,来作为图形化分析的数据来源。
在2016年9月份抓取的该网站口碑数据中,包含所有的在售车和停售车,口碑总量约80万条。抓取分为两个部分,一部分为脚本抓取,目的是抓取所有口碑的详情链接url,另一部分是购买的百度bce云解析抓取,目的是根据详情链接抓取口碑页面。
第一部分脚本抓取是自己写的python脚本,没有使用任何框架,仅依靠requests、re和lxml完成页面的下载和解析。该网站对外部抓取几乎没有封禁策略,无需设置headers甚至访问的间隔时间。按照品牌->车系->车型的顺序找到200+个品牌和2200+个车系和23000+个车型,然后根据每个车型口碑页的链接规则构建出每个车型口碑的列表页,下载页面并解析出每个车型下口碑的数量和所有口碑详情页的url。由于没有使用抓取框架,提取链接主要用了re的一些特定规则,没有复杂的逻辑和代码。
第二部分是根据第一步下载并提取的80万个url下载口碑详情页并提取相应数据,上文提到了该网站几乎没有封禁策略,所以这80万个页面也可以用requests慢慢下载,不过项目组购买了百度云的服务,对于量大且无需太精准度的数据非常适合。每10000个url作为一个任务,每个任务间隔时间300s(非极限),百度抓取的优势在于速度快,并且目标网站不会封禁百度服务器的爬虫。
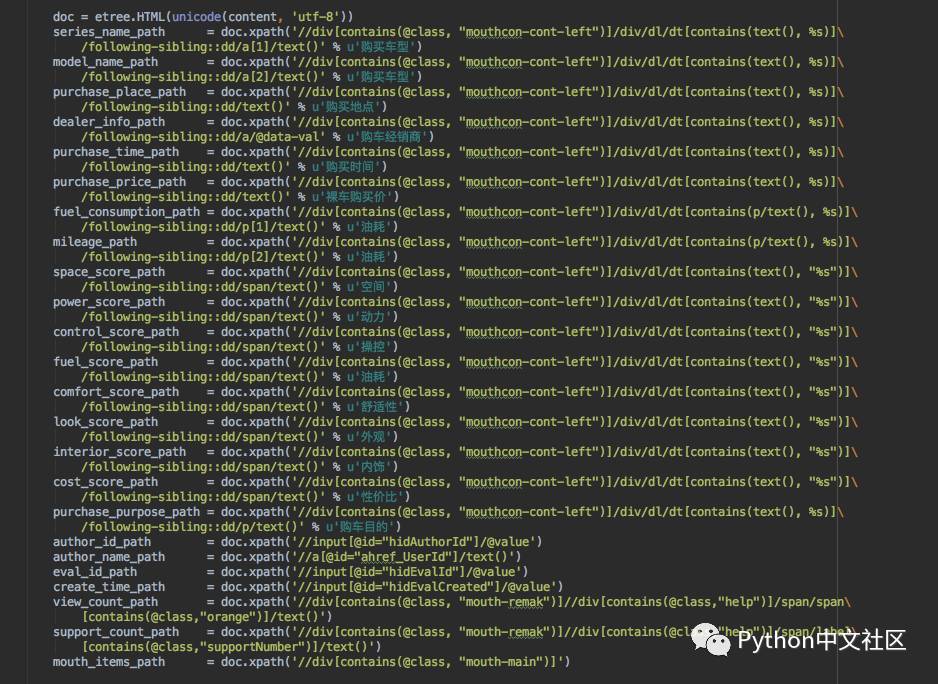
下载详情页后的内容提取就是一些简单的xpath解析,提取后的内容存入数据库或Excel:
二、数据分析
Tableau是一款功能非常强大的可视化数据分析软件,本文仅使用了简单的数据统计和分析并呈现在图表上。以下是一些简单的统计结果:
按品牌、车系、车型分别统计口碑数量,反映了车主对不同车型的关注热度:
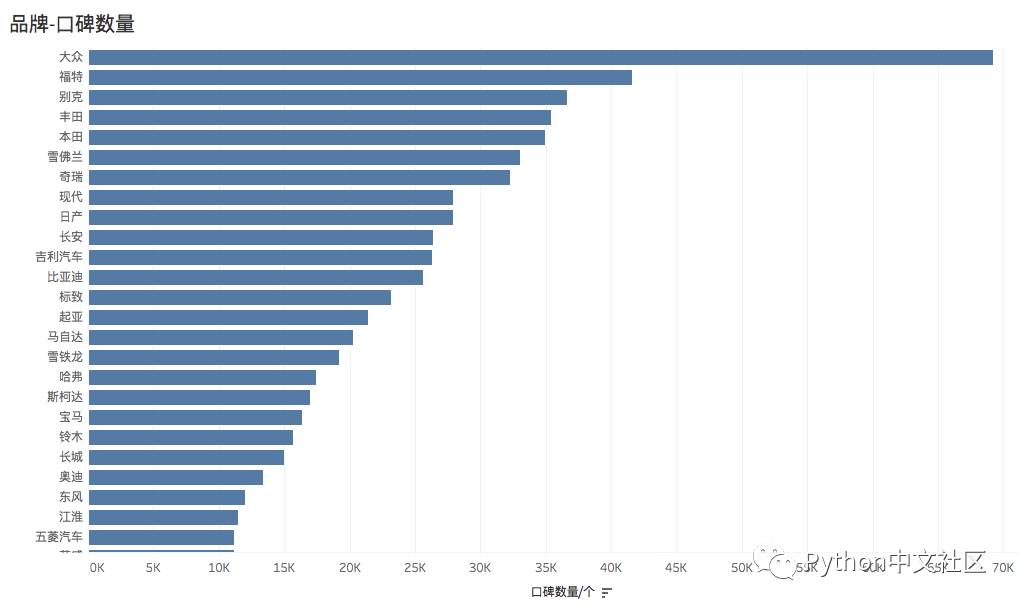
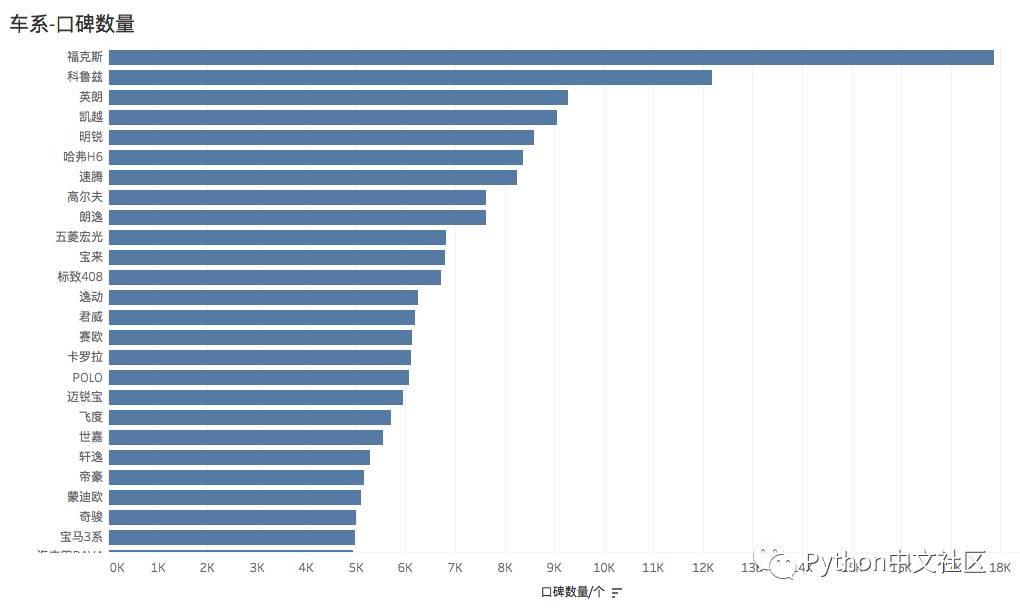
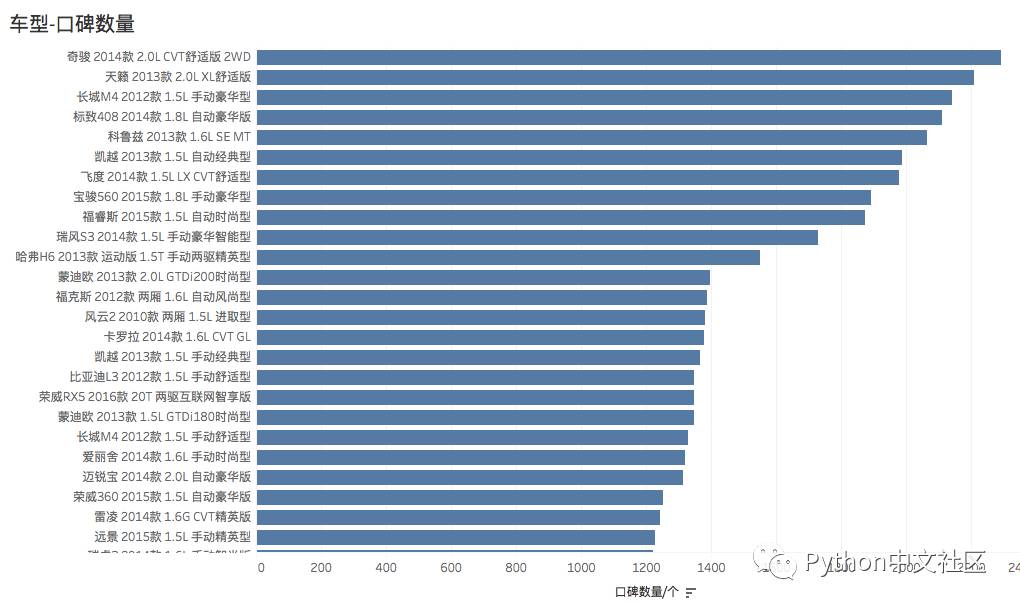
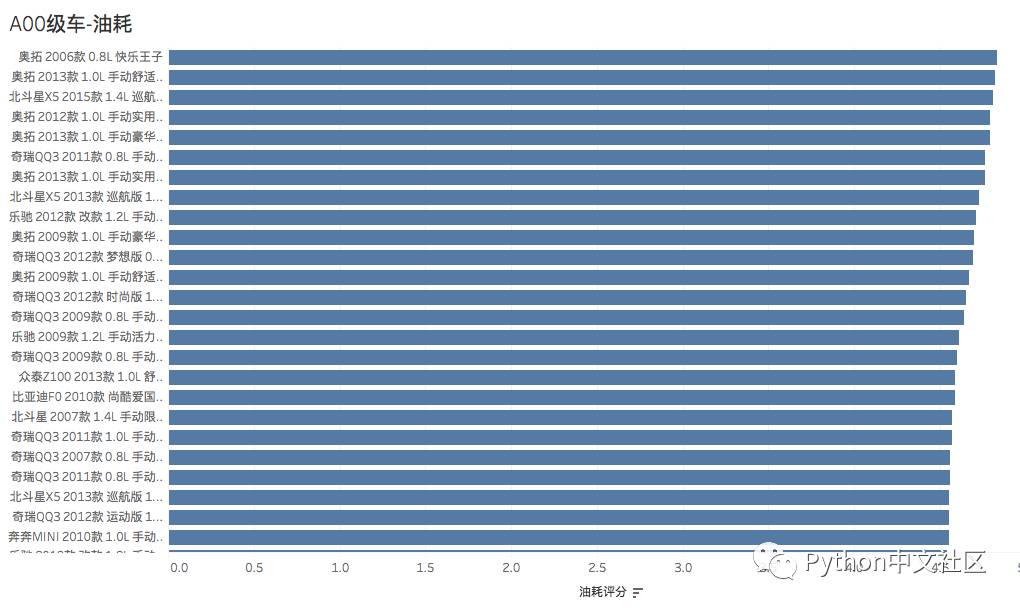
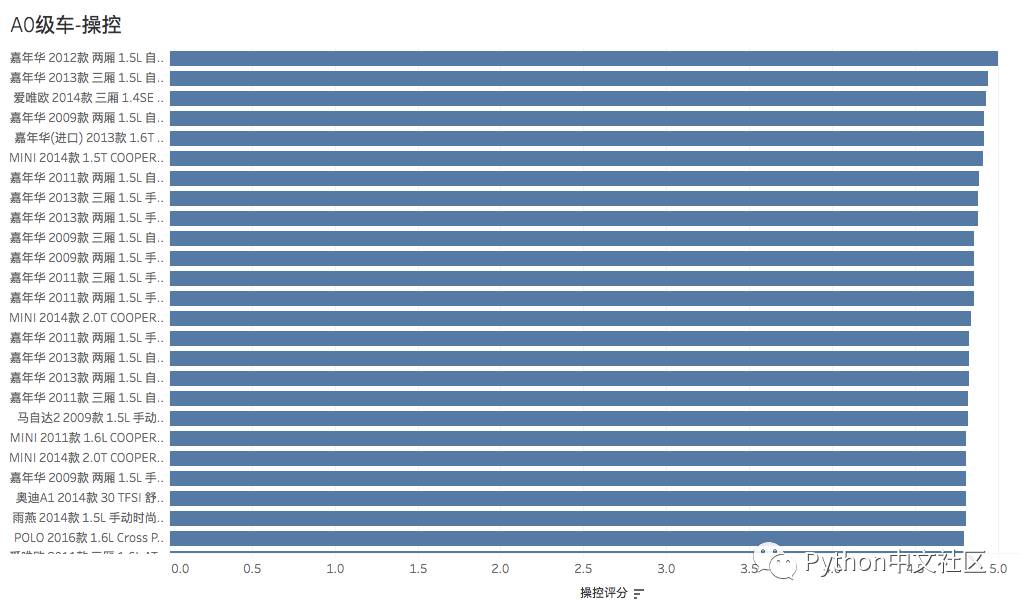
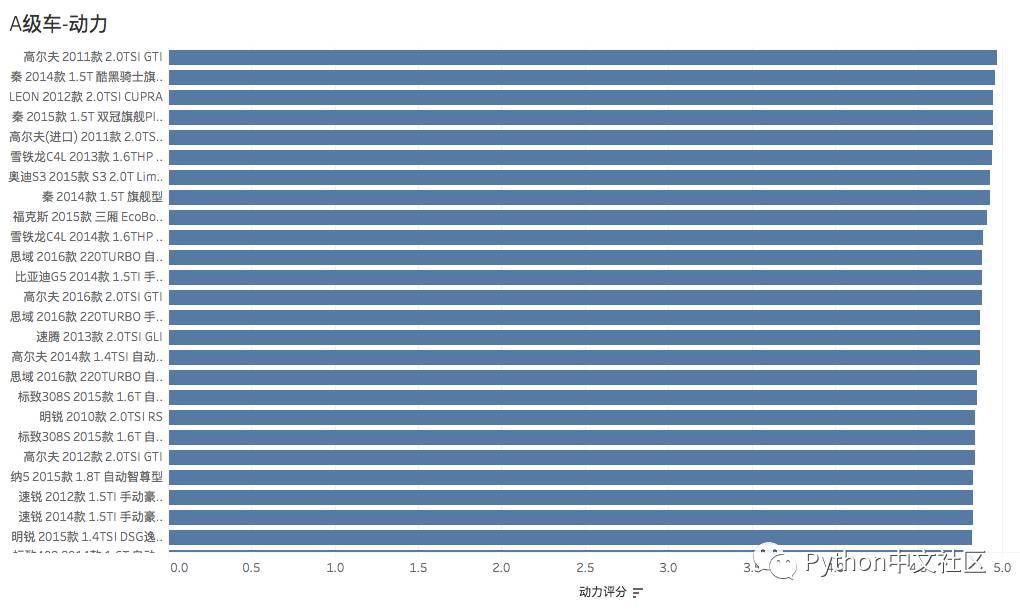
分级别统计车辆的各项指标排名(参照口碑数量,平均分,同级别排名),下文分别列出了 不同统计类别的统计结果,反映了车主对各级别车的不同维度的评价。
A00级车-油耗评分
A0级车-操控评分
A级车-动力评分
B级车-空间评分
SUV(10-20万)-性价比评分
以上是对汽车口碑数据的简单统计,仅涉及了可量化的评分数据,统计维度也比较简单,实际上针对不同车型的对比和排名还要参考更多其他的市场和维护保养数据,本文仅作参考。
⊙生成器:
关于生成器的那些事儿
⊙爬虫代理:
如何构建爬虫代理服务
⊙地理编码:
怎样用Python实现地理编码
⊙nginx日志:
使用Python分析nginx日志
⊙ 淘宝女郎:
一个批量抓取淘女郎写真图片的爬虫
⊙ IP代理池:
突破反爬虫的利器——开源IP代理池
⊙ 布隆去重:
基于Redis的Bloomfilter去重(附代码)
⊙ 内建函数:
Python中内建函数的用法
⊙ QQ空间爬虫:
QQ空间爬虫最新分享,一天 400 万条数据
⊙ 对象:
Python教你找到最心仪对象
⊙ 线性回归:
Python机器学习算法入门之梯度下降法实现线性回归
⊙ 匿名代理池:
进击的爬虫:用Python搭建匿名代理池
⊙ 发射导弹:
Python发射导弹的正确姿势
在公众号底部回复上述关键词可直接打开相应文章

Python 开 发 者 的 精 神 家 园
— Life is short,we use Python —









