 任务
任务
抓取四川大学公共管理学院官网(
http://ggglxy.scu.edu.cn)所有的新闻咨询
.
实验流程
1.确定抓取目标.
2.制定抓取规则.
3.'编写/调试'抓取规则.
4.获得抓取数据
1.确定抓取目标
我们这次需要抓取的目标为四川大学公共管理学院的所有新闻资讯.于是我们需要知道公管学院官网的布局结构.
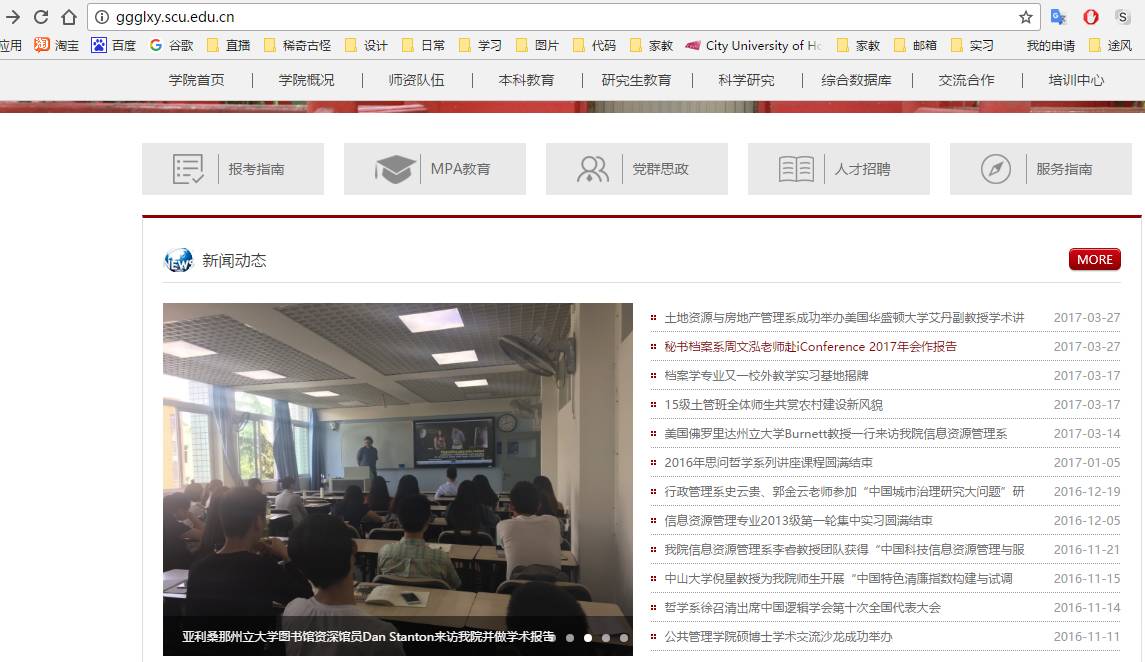
这里我们发现想要抓到全部的新闻信息,不能直接在官网首页进行抓取,需要点击"more"进入到新闻总栏目里面.
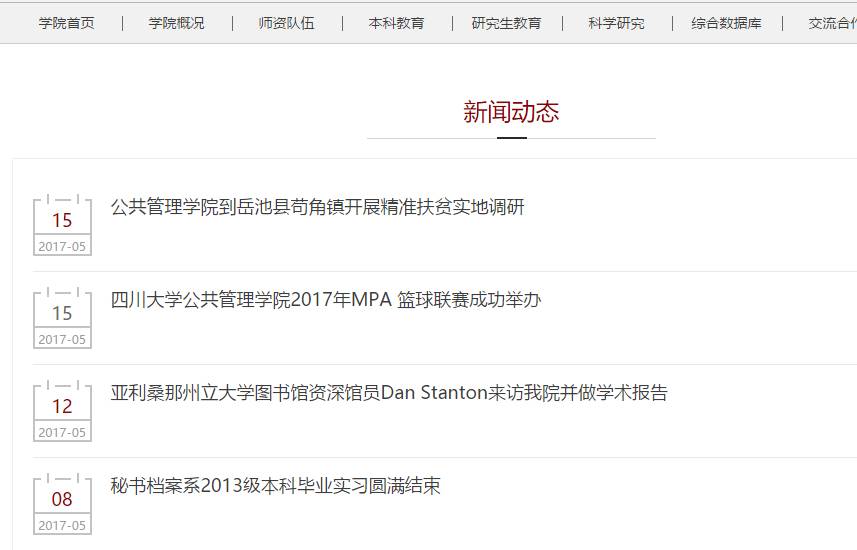
我们看到了具体的新闻栏目,但是这显然不满足我们的抓取需求: 当前新闻动态网页只能抓取新闻的时间,标题和URL,但是并不能抓取新闻的内容.所以我们想要需要进入到新闻详情页抓取新闻的具体内容.
2.制定抓取规则
通过第一部分的分析,我们会想到,如果我们要抓取一篇新闻的具体信息,需要从新闻动态页面点击进入新闻详情页抓取到新闻的具体内容.我们点击一篇新闻尝试一下

们发现,我们能够直接在新闻详情页面抓取到我们需要的数据:标题,时间,内容.URL.
好,到现在我们清楚抓取一篇新闻的思路了.但是,如何抓取所有的新闻内容呢?
这显然难不到我们.
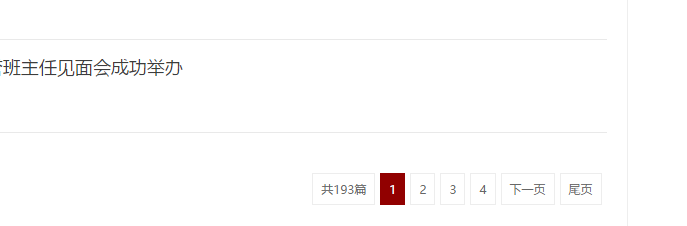
我们在新闻栏目的最下方能够看到页面跳转的按钮.那么我们可以通过"下一页"按钮实现抓取所有的新闻.
那么整理一下思路,我们能够想到一个显而易见的抓取规则:
通过抓取'新闻栏目下'所有的新闻链接,并且进入到新闻详情链接里面抓取所有的新闻内容.
3.'编写/调试'抓取规则
为了让调试爬虫的粒度尽量的小,我将编写和调试模块糅合在一起进行.
在爬虫中,我将实现以下几个功能点:
1.爬出一页新闻栏目下的所有新闻链接
2.通过爬到的一页新闻链接进入到新闻详情爬取所需要数据(主要是新闻内容)
3.通过循环爬取到所有的新闻.
分别对应的知识点为:
1.爬出一个页面下的基础数据.
2.通过爬到的数据进行二次爬取.
3.通过循环对网页进行所有数据的爬取.
话不多说,现在开干.
3.1爬出一页新闻栏目下的所有新闻链接

通过对新闻栏目的源代码分析,我们发现所抓数据的结构为
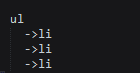
那么我们只需要将爬虫的选择器定位到(li:newsinfo_box_cf),再进行for循环抓取即可.
编写代码






