对于表3数据,在东曜药业项目开发中也对该数据进行了实验验证。在6R西林瓶中灌装2.5mL、粘度为1.5mPa·s的样品,使用带1.2×30mm的10mL注射器进行装量抽取实验,实测V
HUV
为190±46μL、V
HUs
为141±29μL、V
HU
为332±60μL(n=20),其中V
HUV
与V
HU
与表3数据对比,差异较小,表明用山梨醇溶液拟合的V
HU
可作为实际料液早期V
HU
决策的数据。
继续回归过量灌装体积的预测模型:V
overfill
=V
HU
+B
filling
+k*σ
total
, V
HU
可直接参考表3数据,第二个参数B
filling
(灌装偏差),更多的是考虑到灌装机实际灌装体积与设定灌装体积之间的差值,该数据可通过灌装历史数据或验证数据得到。目前由于各药厂配备先进的灌装设备,加上在线称重等PAT技术,能够大大降低灌装偏差,甚至低到可以忽略不计(远低于1%)。以东曜药业的灌装设备为例,如在20R西林瓶中进行5.3mL装量灌装,实际B
filling
保持在20μL以内,仅0.38%灌装体积的偏差。
第三个参数为标准差σ
total
,该数值基于灌装精度σ
filling
及装量检测标准差σ
analysis
计算而得,公式为
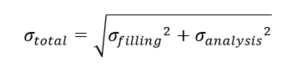
经多批生产数据分析,东曜药业制剂车间实测σ
filling
均不大于50μL(20R灌装5.3mL,n
batch
=7),即0.94%灌装体积,小于1%。装量检测的偏差,根据实际检测数据得到,在上述举例项目中的2.5mL装量样品,实际测得的σ
analysis
为60μL(n=20)。
回到预测模型的最后一个参数k值,文献中表述为容忍系数(Tolerance factor),是基于正态分布概率决定的。如果装量差异足够小,可以认定取样测装量的样品装量是一致的,由于人为操作等原因,实际检测的装量是服从正态分布的。以2.5mL装量项目举例,实测V
HU
为332±60μL,暂不考虑灌装精度,如实际灌装量设定为2.5+0.332=2.832mL,则实际装量检测有50%的概率会判定为装量不足2.5mL,存在较大的装量不合格风险。因此,需要考虑到装量检测标准差σ
analysis
。这里引入正态分布的z分位数概念,z分位数代表正态分布中实际值位于整体分布的水平。如V
HU
服从正态分布X~N(332,60),也就是说,如设定过量灌装量为332μL,实测有50%概率是检测未达到332μL的,此时k=z
0.5000
=0;如k=1=z
0.8413
,即设定过量灌装体积为332+1*60=392μL,则装量检测合格的概率为84.13%,因此,为保证装量检测合格的概率>95%,应设定k=z
0.9505
=1.65,即设定过量灌装量为332+1.65*60=431μL (n=15)。





