当我开始学习爬虫的时候,我在网上也开始找相关教程,大多数都是xx分钟学会爬虫一类的文章。并不是否定这些文章的价值,因为他们的确“教会”我如何爬取网页。但是当我爬取网页好几次后,我就开始反思网络爬虫背后的原理了。
思考一下我们是怎么样上网的呢?
1. 打开浏览器,习惯性输入百度看看网络连接有没有问题或者输入谷歌看看能不能科学上网。
2. 然后我现在的习惯是打开简书首页,看看有没有新的技术类文章或者是鸡汤文,不断往下、往下、往下拉--居然找不到。
3. 突然找到一篇感觉不错的文章,于是点进去继续看了下去。
4. 文章中还有其他扩展阅读推荐,我继续点进去看下好了。
5. 看完链接的文章感觉不需要再刨根问底,就关闭这个页面了。
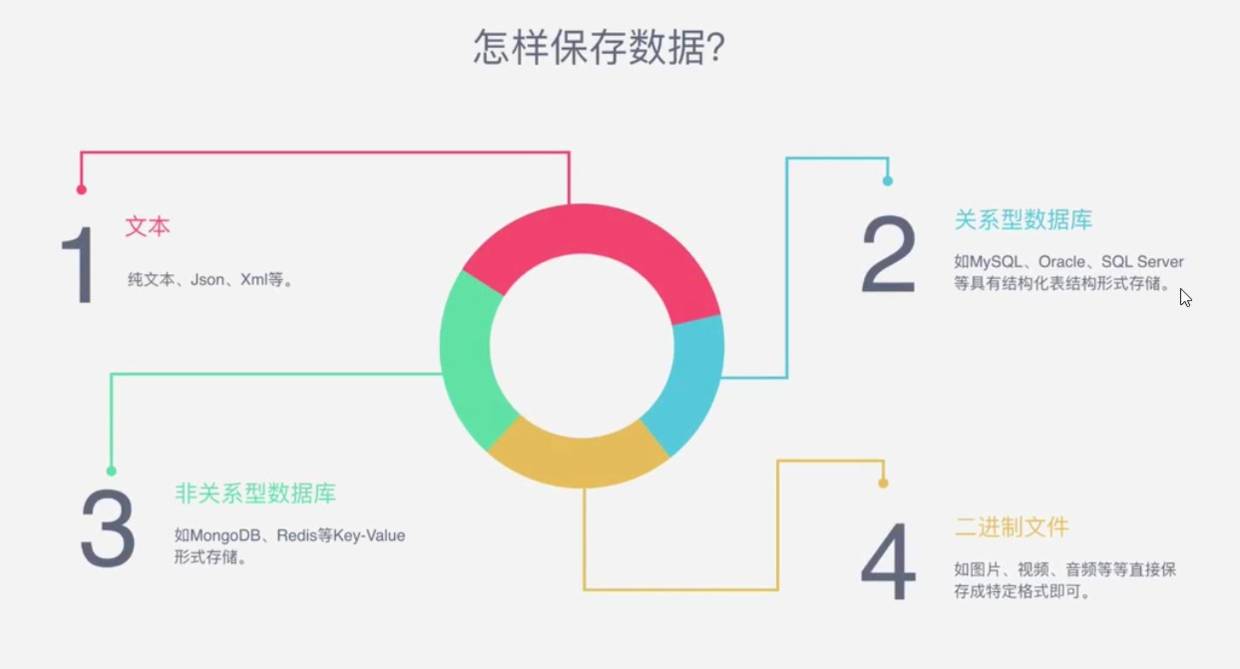
什么是爬虫
爬虫:请求网站,并提取数据的自动化程序请求网站,并提取数据的自动化程序
爬虫基于用户需求诞生。比如说有一天我感觉每天打开简书首页看东西太累了,希望可以有一份邮件告诉我昨天我关注的专栏更新的收录文章,或者告诉我简书喜欢量最多的文章TOP10。我肯定不会雇一个人帮我一个一个翻(因为我没钱),但是我会雇一个网络爬虫帮我解决这个问题(因为他只问我要电费和带宽费)。
那爬虫是怎么工作的呢?想象你雇了一个富土康流水线的员工帮你去互联网找东西,爬虫也就是这样工作。
爬虫基本流程
在了解爬虫的定义之后,那么再来看看爬虫是如何工作的吧。
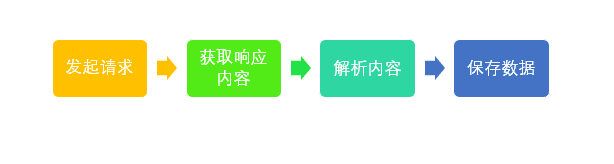
第一步:发起请求。一般是通过HTTP库,对目标站点进行请求。等同于自己打开浏览器,输入网址。
第二步: 获取响应内容(response)。如果请求的内容存在于服务器上,那么服务器会返回请求的内容,一般为:HTML,二进制文件(视频,音频),文档,Json字符串等。
第三步:解析内容。对于用户而言,就是寻找自己需要的信息。对于Python爬虫而言,就是利用正则表达式或者其他库提取目标信息。
第四步:保存数据。解析得到的数据可以多种形式,如文本,音频,视频保存在本地。
请求与响应
爬虫最主要的任务就是发起请求(Request),然后获取服务器的响应(Response)。

Request所包含的信息:
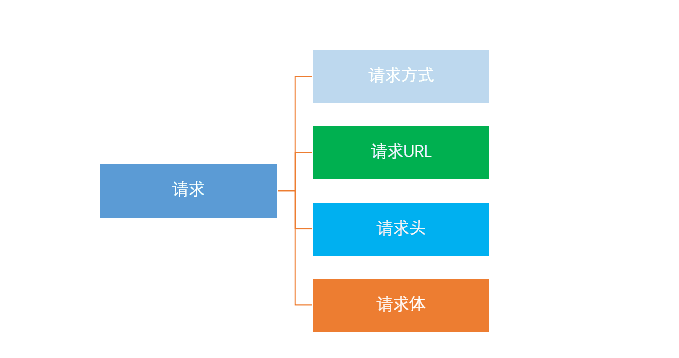
爬虫的第一步就是发起请求,请求包括如下内容:
请求方式: 主要有GET,POST两种类型,另外还有HEAD,PUT,DELETE,OPTIONS等。
GET特点:请求的参数全部包含在请求的网址内。
POST特点: 需要构造Form Data才能发起请求
请求URL:URL的全名是统一资源定位符。网络上的一切资源都是位于服务器的某一个位置,而URL就是告知浏览器去哪里获取这些资源。
请求头:请求头(header)就是告诉服务器你是谁,包括User-gaget,Host,Cookies等信息。添加请求头信息,保证请求合法
请求体:请求时包含的额外数据,如POST请求需要输入的表单数据,一般用于模拟登陆。
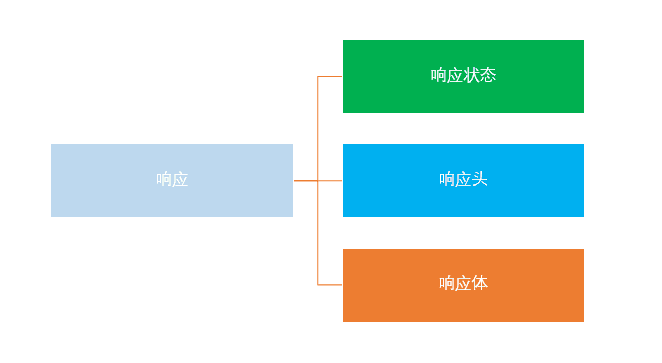
Response所包含的信息
向服务器发出请求后,不出意外,服务器就会返回一个响应(response)。包括如下内容:
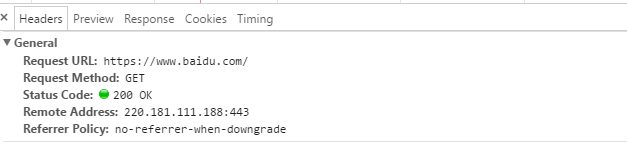
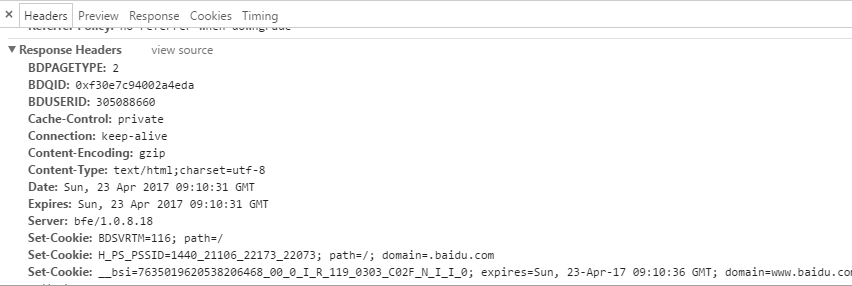
响应状态:用于表示请求的结果,如200代表成功,404找不到页面,502服务器错误等。
响应头 :如内容类型,内容长度,服务器信息,设置Cookie等等
响应体就是网页源代码,也就是用于解析数据的部分。
访问网页遇到的第一个文件一般都是document形式,都是网页源代码。然后解析内部的超链接,继续发起请求。
代码部分:
# 导入请求库
import requests
# 请求网页
response = requests.get('http://www.baidu.com')
# 查看响应体内容
print(response.text)
print(response.content)
print(response.headers)
print(response.status_code)
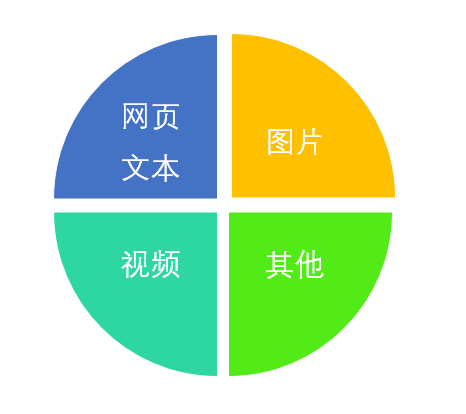
能够抓取的数据:
只要是网页上可以看到的内容,不出意外都是可以抓取的。但是能不能抓得到很大程度上取决于你的爬虫水平。
网页文本: 如HTML文档,Json格式文本等
图片: 获取的都是二进制文件,如果保存为图片格式
视频: 也是也二进制文件,保存为视频格式
其他 : 只要你能请求到,就能获取到
如何解析网页:

解析网页会遇到的问题
抓到的数据和浏览器看到的不一样
element看到的网页的源代码已经经过修饰,数据来自后台端口
浏览器运行JS,后台请求加载,
如何解决JavaScript渲染问题
分析Ajax请求
selenium/webdriver
Splash
PyV8、Ghost.py