Credit_History Property_Area
15 1.0 Urban
248 1.0 Semiurban
590 1.0 Semiurban
246 1.0 Urban
388 1.0 Urban
特征缩放
▼
特征缩放是用来限制变量范围的方法,以让它们能在相同的尺度上进行比较。这是在连续变量上操作的。让我们输出数据集中所有连续变量的分布。
>> import matplotlib.pyplot as plt
>> X_train[X_train.dtypes[(X_train.dtypes=="float64")|(X_train.dtypes=="int64")]
.index.values].hist(figsize=[11,11])
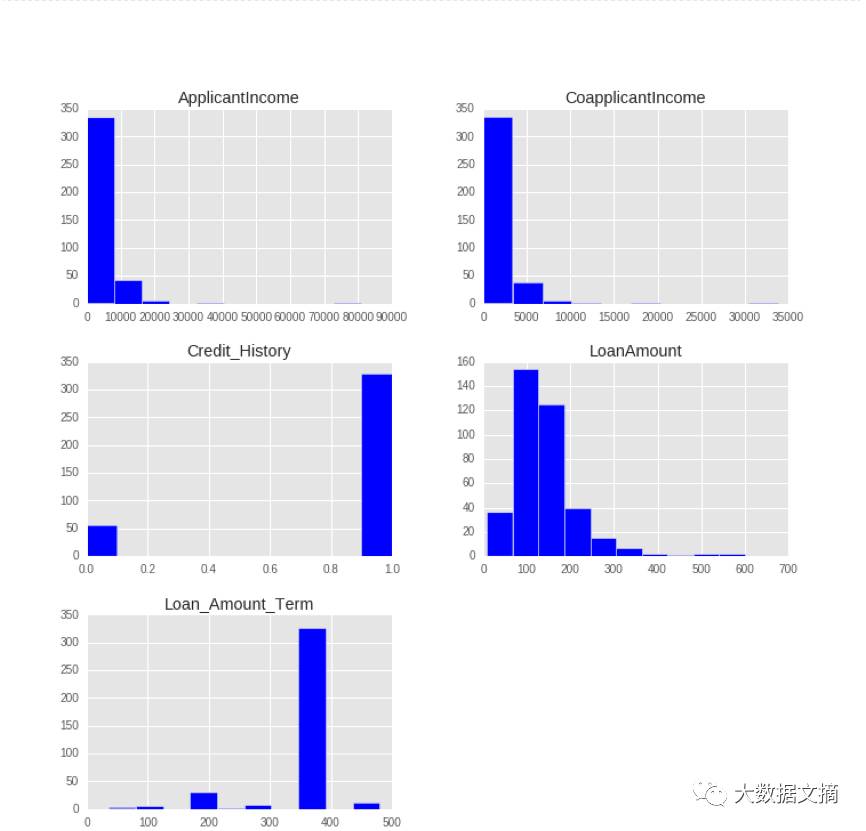
理解以上图示后,我们推断ApplicantIncome(申请人收入) 和CoapplicantIncome(共同申请人收入) 有相似的尺度范围(0-50000$),LoanAmount(贷款额度) 以千为单位,范围在0 到 600$之间,而Loan_Amount_Term(贷款周期)与其它变量完全不同,因为它的单位是月份,而其它变量单位是美元。
如果我们尝试应用基于距离的算法,如KNN,在这些特征上,范围最大的特征会决定最终的输出结果,那么我们将得到较低的预测精度。我们可通过特征缩放解决这个问题。让我们实践一下。
资料:阅读这篇关于KNN的文章获得更好的理解。(https://www.analyticsvidhya.com/blog/2014/10/introduction-k-neighbours-algorithm-clustering/)
让我们在我们的数据集中试试KNN,看看它表现如何。
# 初始化和拟合一个KNN模型
>> from sklearn.neighbors import KNeighborsClassifier
>> knn=KNeighborsClassifier(n_neighbors=5)
>> knn.fit(X_train[['ApplicantIncome', 'CoapplicantIncome','LoanAmount',
'Loan_Amount_Term', 'Credit_History']],Y_train)
# Checking the performance of our model on the testing data set
# 检查我们的模型在测试数据集上的性能
>> from sklearn.metrics import accuracy_score
>> accuracy_score(Y_test,knn.predict(X_test[['ApplicantIncome', 'CoapplicantIncome',
'LoanAmount', 'Loan_Amount_Term', 'Credit_History']]))
Out : 0.61458333333333337
我们得到了大约61%的正确预测,这不算糟糕,但在真正实践中,这是否足够?我们能否将该模型部署于实际问题中?为回答该问题,让我们看看在训练集中关于Loan_Status(贷款状态) 的分布。
>> Y_train.Target.value_counts()/Y_train.Target.count()
Out : Y 0.705729
N 0.294271
Name: Loan_Status, dtype: float64
大约有70%贷款会被批准,因为有较高的贷款批准率,我们就建立一个所有贷款都通过的预测模型,继续操作并检测我们的预测精度。
>> Y_test.Target.value_counts()/Y_test.Target.count()
Out : Y 0.635417
N 0.364583
Name: Loan_Status, dtype: float64
哇!通过猜测,我们获得63%的精度。这意味着,该模型比我们的预测模型得到更高的精度?
这可能是因为某些具有较大范围的无关紧要的变量主导了目标函数。我们可以通过缩小所有特征到同样的范围来消除该问题。Sklearn提供了MinMaxScaler 工具将所有特征的范围缩小到0-1之间,MinMaxScaler 的数学表达式如下所示:
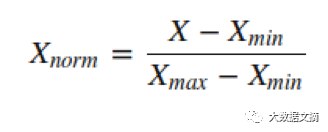
让我们在我们的问题中试试该工具。
# 导入MinMaxScaler并初始化
>> from sklearn.preprocessing import MinMaxScaler
>> min_max=MinMaxScaler()# Scaling down both train and test data set
>> X_train_minmax=min_max.fit_transform(X_train[['ApplicantIncome', 'CoapplicantIncome',
'LoanAmount', 'Loan_Amount_Term', 'Credit_History']])
>> X_test_minmax=min_max.fit_transform(X_test[['ApplicantIncome', 'CoapplicantIncome',
'LoanAmount', 'Loan_Amount_Term', 'Credit_History']])
现在,我们已经完成缩放操作,让我们在缩放后的数据上应用KNN并检测其精度。
# 在我们缩小后的数据集上拟合KNN
>> knn=KNeighborsClassifier(n_neighbors=5)
>> knn.fit(X_train_minmax,Y_train)
# 检查该模型的精度
>> accuracy_score(Y_test,knn.predict(X_test_minmax))
Out : 0.75
太好了!我们的精度从61%提升到了75%。这意味在基于距离的方法中(如:KNN),一些大范围的特征对预测结果有决定性作用。
应当牢记,当使用基于距离的算法时,我们必须尝试将数据缩放,这样较不重要的特征不会因为自身较大的范围而主导目标函数。此外,具有不同度量单位的特征也应该进行缩放,这样给每个特征具有相同的初始权重,最终我们会得到更好的预测模型。
尝试利用逻辑回归模型做相同的练习(参数: penalty=’l2′,C=0.01), 并请在评论区留下缩放前后的精度。
特征标准化
▼
在进入这部分内容前,我建议你先完成练习1。
在之前的章节,我们在贷款预测数据集之上操作,并在其上拟合出一个KNN学习模型。通过缩小数据,我们得到了75%的精度,这看起来十分不错。我在逻辑回归模型上尝试了同样的练习, 并得到如下结果:
Before Scaling : 61%
After Scaling : 63%
缩放前:61%
缩放后:63%
缩放后的精度与我们凭猜测得到的预测精度相近,这并不是很了不起的成就。那么,这是怎么回事呢?在精度上,为什么不像用KNN一样有令人满意的提升?
资料:阅读本文(https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression/)获得对逻辑回归更好的理解。
答案在此:
在逻辑回归中,每个特征都被分配了权重或系数(Wi)。如果某个特征有相对来说比较大的范围,而且其在目标函数中无关紧要,那么逻辑回归模型自己就会分配一个非常小的值给它的系数,从而中和该特定特征的影响优势,而基于距离的方法,如KNN,没有这样的内置策略,因此需要缩放。
我们是否忘了什么?我们的逻辑模型的预测精度和猜测的几乎接近。
现在,我将在此介绍一个新概念,叫作标准化。很多Sklearn中的机器学习算法都需要标准化后的数据,这意味数据应具有零均值和单位方差。
标准化(或Z-score正则化)是对特征进行重新调整,让数据服从基于 μ=0 和 σ=1的标准正态分布,其中μ是均值(平均值)而σ是关于均值的标准偏差。样本的标准分数(也称为z-scores)按如下所示的方法计算:
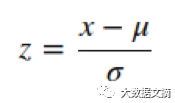
线性模型中因子如l1,l2正则化和学习器的目标函数中的SVM中的RBF核心假设所有的特征都集中在0周围并且有着相同顺序的偏差。
有更大顺序的方差的特征将在目标函数上起决定作用,因为前面的章节中,有着更大范围的特征产生过此情形。 正如我们在练习1中看到的,没进行任何预处理的数据之上的精度是61%,让我们标准化我们的数据,在其上应用逻辑回归。Sklearn提供了尺度范围用于标准化数据。
# 标准化训练和测试数据
>> from sklearn.preprocessing import scale
>> X_train_scale=scale(X_train[['ApplicantIncome', 'CoapplicantIncome',
'LoanAmount', 'Loan_Amount_Term', 'Credit_History']])
>> X_test_scale=scale(X_test[['ApplicantIncome', 'CoapplicantIncome',
'LoanAmount', 'Loan_Amount_Term', 'Credit_History']])
# 在我们的标准化了的数据集上拟合逻辑回归
>> from sklearn.linear_model import LogisticRegression
>> log=LogisticRegression(penalty='l2',C=.01)
>> log.fit(X_train_scale,Y_train)
# 检查该模型的精度
>> accuracy_score(Y_test,log.predict(X_test_scale))
Out : 0.75
我们再次达到缩放后利用KNN所能达到的我们最大的精度。这意味着,当使用l1或l2正则化估计时,标准化数据帮助我们提高预测模型的精度。其它学习模型,如有欧几里得距离测量的KNN、k-均值、SVM、感知器、神经网络、线性判别分析、主成分分析对于标准化数据可能会表现更好。
尽管如此,我还是建议你要理解你的数据和对其将要使用的算法类型。过一段时间后,你会有能力判断出是否要对数据进行标准化操作。
备注:在缩放和标准化中二选一是个令人困惑的选择,你必须对数据和要使用的学习模型有更深入的理解,才能做出决定。对于初学者,你可以两种方法都尝试下并通过交叉验证精度来做出选择。
资料:阅读本文(https://www.analyticsvidhya.com/blog/2015/11/improve-model-performance-cross-validation-in-python-r/)会对交叉验证有更好的理解
尝试利用SVM模型做相同的练习,并请在评论区留下标准化前后的精度。
资料:阅读本文(https://www.analyticsvidhya.com/blog/2015/10/understaing-support-vector-machine-example-code/)会对SVM有更好的理解。
标签编码
▼
在前面的章节里,我们对连续数字特征做了预处理。但是,我们的数据集还有其它特征,如性别(Gender)、婚否(Married)、供养人(Dependents)、自雇与否(Self-Employed)和教育程度(Education)。所有这些类别特征的值是字符型的。例如,性别(Gender)有两个层次,或者是男性(Male),或者是女性(Female)。让我们把这些特征放进我们的逻辑回归模型中。
#在整个数据集上拟合放逻辑回归模型
>> log=LogisticRegression(penalty='l2',C=.01)
>> log.fit(X_train,Y_train)
#检查模型的精度
>> accuracy_score(Y_test,log.predict(X_test))
Out : ValueError: could not convert string to float: Semiurban
我们得到一个错误信息:不能把字符型转换成浮点型。因此,这里真正在发生的事是像逻辑回归和基于距离的学习模式,如KNN、SVM、基于树的方法等等,在Sklearn中需要数字型数组。拥有字符型值的特征不能由这些学习模式来处理。
Sklearn提供了一个非常有效的工具把类别特征层级编码成数值。LabelEncoder用0到n_classes-1之间的值对标签进行编码。
让我们对所有的类别特征进行编码。
#










