雷锋网将联合英伟达 DLI
,面向 AI 技术从业者,特别推出
深度学习课程
,
对深度学习和英伟达 GPU 加速技术感兴趣的朋友可以参阅
文末介绍
!
编者按:
北京时间 5 月 11 日 00:00,万众瞩目的英伟达 CEO 黄仁勋 Keynote 演讲,在加州圣何塞举行。全场长达两个多小时,本场主题演讲的话题涉猎面其实很广: VR、Volta、超算、GPU 云服务、自动驾驶芯片、以及机器人训练。英伟达也恰恰在 GTC 举办的同时,公布了 2017 年第一季度的财报。财务数据显示,NVIDIA 在 2017 第一季度营收同比增长 48%,达到 19.4 亿美元。看来,英伟达已经如同老黄所说,已完全转型成为领先的 AI 企业。

今年的 NVIDIA GTC 开发者大会,与往年颇有些不同。
北京时间 5 月 11 日 00:00,万众瞩目的英伟达 CEO 黄仁勋 Keynote 演讲,在加州圣何塞举行。全场长达两个多小时,雷锋网记者在媒体中第一位入场,坐在了前排中央。然而,
整场演讲下来,老黄并没有一句提到游戏。
本场主题演讲的话题涉猎面其实很广: VR、Volta、超算、GPU 云服务、自动驾驶芯片、以及机器人训练。但是,
所有这些话题都有一个共同点:要么基于 AI、深度学习技术、要么为 AI、深度学习技术服务。
英伟达也恰恰在 GTC 举办的同时,公布了 2017 年第一季度的财报。财务数据显示,NVIDIA 在 2017 第一季度营收同比增长 48%,达到 19.4 亿美元。在过去一年里,NVIDIA 致力于深度学习的计算系统解决方案极大推动了语音识别、机器视觉、虚拟助手、自动驾驶等领域的发展,而其在各行各业的核心开发者也成为这家 “核弹公司” 源源不断的增长动力。
发布五大革命性产品
看来,英伟达已经如同老黄所说,已完全转型成为领先的 AI 企业。本届 GTC 的主题,便是 AI & 深度学习。当然,还有划时代的深度学习硬件 Volta。
下面,便是本届 GTC 英伟达发布的五大革命性产品:
Project Holodeck、Volta、英伟达 GPU 云、Xavier DLA,以及 Isaac 机器人模拟机。
Project Holodeck

Project Holodeck 是老黄发布的第一个产品,堪称是本届 GTC 的开胃菜。它将 VR 和 AI 的顶尖技术相结合,所构建的 VR 社交、工作空间。它有三大特点:
其中最大的亮点,无疑是物理交互体验。老黄表示,虚拟共享空间必须要遵从物理定律,否则就无从营造真实世界般的沉浸感。相比之下,同属 VR 社交空间应用的 Facebook Spaces,并没有这么强调物理属性。
英伟达与顶级跑车制造商科尼塞克合作,请科尼塞克创始人 Christian Koenigsegg 甚至利用 VR 化身(上图中的虚拟人)“现身” 说法。

演示中,有两个细节值得我们注意:
Project Holodeck 将于 9 月开放早鸟体验。
Volta 架构
没错,Volta 终于来了。继 Pascal (帕斯卡)之后的新一代 GPU 架构,在万众期待下亮相。对于绝大多数观众,不论 GTC 推出了多少 AI 工具,都无法遮掩 Volta 作为本届大会心脏的事实。
毕竟,英伟达今后二至三年的 GPU 产品线,全都要由 Volta 供血。虽然 Volta 架构的游戏显卡最快在今年底才可能与大家见面,但通过深度学习卡,也可一窥 Volta 的满血性能。那么在本届 GTC,英伟达推出了哪些基于 Volta 的产品?
答案是 Tesla V100,以及基于它的深度学习计算机 DGX-1 和 DGX Station。
Tesla V100

“迄今为止英伟达难度最高、最复杂的项目;
耗费数千工程师数年光阴来完成;
全世界有史以来最昂贵的计算机项目(研发支出为 30 亿美元)。”
说的就是 Tesla V100,基于新一代 Volta 架构。但英伟达在它身上实现的壮举远不止与此:
详细规格见下图:

相比 Pascal,Volta 有全新的张量运算指令,这就是 Tensor Core。
它既是指令也是数据格式,是 4*4 的矩阵处理阵列。它使得 Volta 的训练吞吐量达到了 Pascal 的 12 倍,推理吞吐量达到 6 倍。借助它,Tesla V100 的张量运算能力达到 120 TFLOPS。
它是 Volta 的高性能神经网络推理引擎,或者说编译器。目的是为推理运算快速地优化、验证、部署训练好的神经网络。
老黄解释道:” 训练完成之后,用于训练神经网络的框架会生成图。图需要为你使用的处理器进行优化、编译。我们把这称为 TensorRT。“
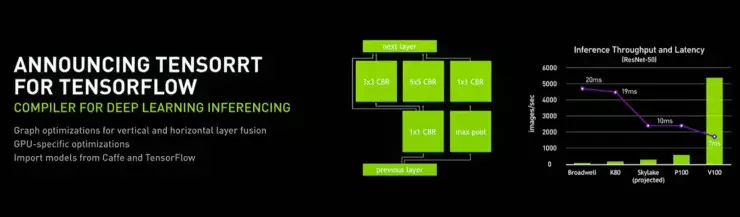
众所周知,深度学习运算可被分为训练和推理两部分。从前, N 卡只关注训练,而在 Tesla V100 上,英伟达终于对推理 “动真格”。老黄表示,
从 Volta 开始,英伟达 GPU 将对训练、推理兼顾,可谓是革命性的突破。
如图所示,Tesla V100 的推理运算速度是 Skylake CPU 的十余倍不止。CPU、FPGA 和 TPU 们怕了么?

这是 Tesla K80、P100 与 V100 三代架构的性能对比。在 Caffe2、Microsoft Cognitive Toolkit(CNTK)、MXnet 三大框架上,V100 取得了数倍的性能提升。以 Caffe2 为例,训练时间由 K80 的 40 多小时,缩减到 V100 的不到 10 小时。
DGX-1V、DGX Station 和 HGX-1
深度学习超级计算机 DGX-1 也把 GPU 升级为 Volta,这便是 DGX-1V。

它内置八块 Tesla V100,运算能力为惊人的 960 Tensor TFLOPS。老黄表示,过去 Titan X 需花费八天训练的神经网络,用 DGX-1V 只需八个小时。它相当于是 “把 400 个服务器装进一个盒子里”。





