
2016年是人工智能崛起的一年,随着人脸识别、驾驶辅助等人工智能应用的普及,众多互联网(Google、Facebook、百度等)和半导体巨头(Nvidia,Qualcomm,Intel等)都相继在人工智能领域布局发力。自然地,在2017年CES展最受人关注的热点当然也是人工智能。在各类人工智能应用层出不穷时,我们也应当注意到站在这些应用背后,以低廉价格提供应用运行平台以加速人工智能普及的恰恰是半导体厂商。今天,我们来盘点一下各大半导体厂商在CES展上的表现。
1. 高通
高通毫无疑问是移动端芯片的主导者。高通此次在CES上发布的产品主要是骁龙835 SoC。骁龙835 SoC使用三星10nm工艺制造,搭载了8核心Kyro 280处理器(包括峰值主频可达 2.45GHz 的 4 颗高性能核心,以及峰值主频可达 1.9GHz 的 4 颗低功耗核心)。

除了处理器之外,骁龙835还包含了X16 LTE Modem,Adreno GPU,Hexagon DSP,Spectra ISP等等核心模块。其中,和人工智能关系最密切的当属Hexagon DSP和Adreno GPU。

目前,在移动端的深度学习应用越来越多。例如最近风靡一时的风格迁移App(将一张图片变成另一张图片的风格)。

在移动端的深度学习应用中,往往对于计算的精度要求不高,使用定点数计算也可满足大部分应用的需求。骁龙系列中的Hexagon DSP就能高效率地完成定点数运算,然而在之前的版本中,DSP对于深度学习应用并不友好,开发者想要调用DSP完成深度学习中的定点数运算并不容易。针对这一点,高通在逐渐加强DSP对于深度学习应用的支持。在骁龙835中,对具有 Hexagon 向量扩展(HVX)特性的 Hexagon DSP 进一步增强,包括了对定制神经网络层更好的支持。
另外,Adreno GPU是骁龙SoC中可以实现SIMD(单指令流多数据流)高效率并行计算的模块。GPU的SIMD特性使得其可以高效完成深度学习计算,但是需要提供给深度学习开发者一套完善的编程接口。Nvidia的编程接口是CUDA,凭借其易用性成为了深度学习开发者首选的开发语言之一。在非Nvidia的GPU中,类似CUDA的接口是OpenCL。这次骁龙835中的Adreno GPU可以完美支持OpenCL 2.0,对于想要借助高通SoC中GPU进行深度学习计算的开发者是个好消息。
最后,高通升级了包含了升级过的神经处理引擎软件框架,其中增加了对 Google TensorFlow 的支持,以及对骁龙异构核心的功耗与性能的优化。这进一步使得深度学习开发者可以更高效地利用高通骁龙SoC的计算能力完成不同的应用。
点评
高通作为一个通信行业起家的半导体巨头,此次CES上仍然以无线通讯为主要战略重点,其在自动驾驶方面的布局也主要在车联网方面而非人工智能运算。不过随着人工智能渐渐向移动(嵌入式)端靠拢,高通也在骁龙SoC中逐渐增加对深度学习的支持。这次骁龙SoC中对深度学习的支持主要体现在指令级以及应用框架上,即可以让开发者更高效地利用现有SoC资源完成深度学习计算。高通的专用的深度学习硬件(如加速器模块)在实验性质的Zeroth之后尚无下文,可见高通对于深度学习的投入尚属保守,这也给其他专注于嵌入式深度学习硬件的厂商一个超越的机会。
2.Intel
之前的Intel已经错失了移动设备的机会,这次Intel不愿意再次错过人工智能。在本届CES,Intel发布了GO平台,显示了其在自动驾驶领域的决心。GO平台包括了车联网、车内运算与云端计算服务。在车内运算,Intel将使用符合汽车电子标准的Atom和Xeon CPU,并配合Altera最新的FPGA技术。在云端,Intel GO将提供包括高效能Intel Xeon处理器、Intel Arria 10 FPGA、SSD以及Intel Nervana平台在内的众多技术,建构出强大的主机与深度学习训练与模拟基础设施,满足自动驾驶产业的需求。另外,Intel还发布了针对GO平台的SDK,让开发者可以充分利用GO平台的计算能力。
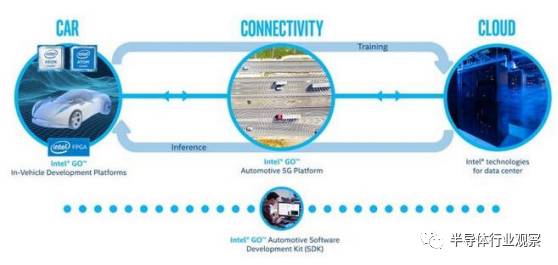
无人驾驶是英特尔聚焦的重要领域之一。2016年底,英特尔将汽车团队从物联网事业部剥离,单独成立自动驾驶事业部。更重要的是,去年Intel与宝马及Mobileye达成联盟,计划在2021年前推出无人驾驶汽车。在这项结盟合作中,BMW集团将负责驾驶操控与动力机件,以及评测整体功能安全性,包括设定高效能模拟引擎、整体零组件整合、生产原型车款。Intel GO平台为各种关键功能提供可扩充的开发与运算平台,包括感测器融合、驾驶策略、环境建模、路径规划、以及决策制定。Mobileye贡献其EyeQ 5专利高效能电脑视觉处理器,提供汽车等级的功能安全性以及低功耗的表现。EyeQ 5负责处理与转译360度环景视觉感测器以及地域性的资料。Mobileye更将进一步与BMW集团合作,着手开发感测器融合解决方案,汇集视觉、雷达、光达感测器搜集到的资料,针对车辆周围环境建立一个完整模型,结合其人工智能算法,让汽车能安全应付各种复杂的驾驶情境。
在本届CES,宝马、Intel和Mobileye联盟在展前发布会上宣布,大约40辆宝马无人驾驶汽车将于2017年下半年开始路测。这是三家公司携手实现无人驾驶目标,所迈出的重要一步。三家公司披露,这些BMW 7系列汽车将采用英特尔和Mobileye的技术,从美国和欧洲开始全球路测之旅。

点评
Intel对于人工智能的投入目前主要显示在云端,其收购的Altera FPGA和Nervana已经在为Intel的云端人工智能业务提供强大的性能。在无人驾驶方面,Intel与BMW、Mobileye组成的联盟各司其职,Intel负责计算平台,Mobileye负责算法、环境感知和大数据采集,而BMW则负责汽车。Intel在移动端人工智能领域还是很低调,但去年收购Movidius动作让我们相信Intel正在这一方面积极布局,不久的将来一定会有更大的作为。
3.Nvidia

借着人工智能的风头,Nvidia的股价在去年飞升三倍有余,令人惊叹。今年CES更是请Nvidia的黄仁勋作为开幕前夜最重头的专场演讲的嘉宾。毫无疑问Nvidia已经成为了本届CES的焦点。今年CES展上,Nvidia发布的产品中有两款与人工智能相关,一款是用于家庭物联网的Shield+Spot,另一款是车载人工智能平台Xavier。
首先我们来看一下Shield+Spot。Shield是Nvidia于几年前发布的游戏主机,而这次在CES发布的则是最新版Shield。新Shield除了拥有常规的游戏和互联网视频播放功能外,最大的亮点是引入了Google助手。Google助手可以通过语音识别完成用户的各种指令,如在CES演讲的演示视频中,就出现了用户通过与Google助手语音交谈从而让Shield播放视频,展示照片等。
然而,Nvidia对Shield的野心远不止“支持语音交互的智能机顶盒”,而是智能家庭中心。为了让Shield能接收用户从家里任何地方发出的语音指令,黄仁勋在发布新Shield的同时还展示了与新Shield搭配使用的Nvidia Spot。Nvidia Spot是经过特别设计的麦克风,可以放置在家里的任何地方,并且通过局域网与Shield连接起来,把用户的语音指令传输到Shield。

同时,在Nvidia的计划中,Shield可以控制的也远远不止电视机,而是可以控制各种智能家电(如Nest的产品)。这样,在Nvidia提供的智能家庭方案中,Nvidia Spot作为用户指令的接收者遍布家的每一个角落,用户在任何地方下的语音指令通过Spot传回物联网中心节点Shield,而Shield则根据指令来控制家庭的智能家电,如打开空调,启动扫地机器人等等。

Nvidia发布会第二个重头戏是Xavier。是Nvidia预期在2017年正式发售的车载超级计算机模组。Xavier包含了拥有512 CUDA核的Volta GPU,8核心的Nvidia定制ARM64 CPU。最令业界震惊的,可谓是其性能:在峰值性能达到30TOPS的情况下,仅仅消耗30W!也就是说,其能量效率达到了1TOPS/W。相形之下,2017年发布在半导体领域最顶级会议ISSCC Deep Learning Processor Session的第一篇paper,ST最顶尖的深度学习专用ASIC也仅仅实现了2.9TOPS/W。ST的深度学习加速器是专为深度学习开发,一般而言只能做深度学习计算;而Xavier是一款通用的计算平台,1TOPS/W的性能除了可以计算深度学习外还可以做其他计算,因此通用性远好于ASIC。通常专用的ASIC的能量效率应当比通用计算平台好一个数量级左右,而现在这个差距被缩小到了3倍不到,可见Xavier性能之强大。在性能相差不大的情况下,大多数人都会选择通用计算平台而非ASIC,因此相信从事深度学习加速器ASIC研发的工程师们看到Xavier这个指标真的是压力很大。

另一个有趣的细节是,Xavier的性能并没有用常规GPU的FLOPS(每秒浮点运算量)做单位,而是OPS(每秒定点数运算量)。在往常的GPU中,深度学习计算通常用浮点数运算来完成,这样的做法在保证计算精度的同时却损失了计算速度,因此深度学习硬件的一个很热门的方向就是如何用定点数运算来代替浮点数运算,在保证计算精度损失可控的情况下大幅提升速度。Nvidia在Pascal GPU上已经做了一些对于定点数计算的支持,而根据CES的主题演讲透露出的蛛丝马迹,下一代Volta GPU上想必会加强对定点数运算的支持。而Nvidia作为深度学习硬件领域的绝对统治者,其对于定点数运算的大力支持又会倒逼深度学习算法开发者加强对于使用定点数的深度学习框架的开发。在可预计的将来,使用定点数的深度学习网络将会变得越来越流行。
Xavier的性能和功耗都完美符合无人驾驶市场的需求,而无人驾驶是Nvidia在人工智能市场布局的重中之重。黄仁勋提到,目前的运输市场规模可达一万亿美元,全球共有十亿量跑在路上的汽车,而汽车运输市场又是一个损耗严重的市场,主因就是人类驾驶员容易犯错。一旦驾驶员犯错,车祸带来的损失非常大。如果用人工智能帮助驾驶,那么这些损耗可以被大大降低。

Nvidia还发布了配合Xavier的无人驾驶和协同驾驶应用。在无人驾驶方面,Nvidia发布了搭载BB2无人驾驶车,BB2目前能实现根据路况自动变道,减速转弯,避让行人等等。Nvidia与奥迪合作,预期在2020年实现第四级无人驾驶(即仅仅在极少情况下需要人工干预的自动驾驶系统)。

在协同驾驶方面,Nvidia发布了四项技术,包括面部识别,头部追踪,视线追踪以及读唇技术。面部识别首先可以通过深度学习判断驾驶员的表情从而进一步判断驾驶员的情绪状况,在发现情绪不稳时提醒驾驶员即使休息调整情绪以避免发生冲动驾驶。头部追踪和视线追踪可以帮助协同驾驶系统判断驾驶员注意力是否集中,并在驾驶员分神时及时提醒。读唇技术则可以在环境较吵闹的情况下根据驾驶员嘴唇的动作判断其发出的语音指令并予以执行。根据黄仁勋的解释,Nvidia正在和英国牛津大学LipNet团队合作研发用于读唇的深度学习网络模型,目前该模型已经能达到93.4%的正确率,可望很快就能用在真正的汽车中。最后,协同驾驶系统还能为驾驶行为打分,在督促驾驶员安全驾驶的同时也能够成为保险公司制定保费的依据。

点评
有意思的是,在CES上Nvidia并没有像AMD一样发布GPU,而是直接发布应用平台,可见Nvidia对自己的角色定位已经从原来的半导体厂商慢慢转型到人工智能平台提供商。另外,如果说高通的芯片主要定位在移动端,Intel的芯片主要服务于云服务器端,那么Nvidia的产品则是介于高通和Intel之间,服务于车载以及家用端。
在数据量巨大的数据中心,Nvidia的GPU是服务器不可或缺的一部分,但是Nvidia自己的服务器目前还在试水阶段,因此在大数据人工智能市场Nvidia提供的是硬件而非平台。在另一个极端,即数据量不大,对运算能力要求不高但是对功耗有极大限制的嵌入式深度学习领域,Nvidia基于GPU的人工智能平台一方面功耗太大,另一方面过高的计算能力反而导致成本过高,因此无法与ASIC(如高通的SoC)抗衡。而在ADAS与家用电器市场,Nvidia的人工智能平台无论计算能力(10-100TOPS)还是功耗(10-100W)都能完美地符合要求,因此Nvidia主打自动驾驶与家用物联网中心并不奇怪。
4.中国厂商
在本届CES上,中国厂商展出的人工智能相关产品主要还是使用国外半导体厂商的芯片并进一步开发,例如地平线基于Intel开发的驾驶辅助(ADAS)技术,以及大疆的无人机。
目前,中国在人工智能专用芯片方面相对国际先进水平并不落后。中科院寒武纪的技术在获得国际学术界和业界的极大认可,在2016年的ISCA(国际计算机架构大会)发表的论文总评分排名第一。基于其技术开发的系列芯片已经经过流片验证,目前正在积极进入商业化轨道。深鉴科技则专注于神经网络压缩,其深度学习处理器架构(DPU)也得到了国际认可,去年下半年刚刚在HotChips发布了Aristole(用于卷积神经网络)和Descartes(用于语音识别)的加速器。
寒武纪芯片

深鉴发布的DPU架构
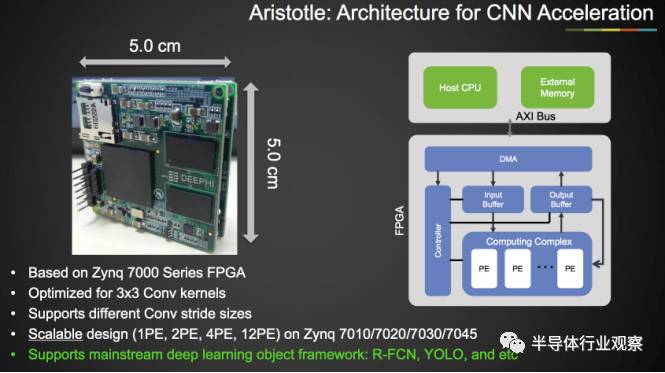
除此之外,华为、大疆等公司也在积极开发人工智能方面的硬件。人工智能专用硬件对于国内外而言处于相近的起跑线,加上国内厂商相对国外半导体巨头而言包袱比较少,因此国内厂商有超越国外巨头的机会。然而,国内的人工智能芯片厂商不能只开发深度学习加速器,而必须要提供整套解决方案才能有足够竞争力。中国半导体厂商在这方面还任重而道远。
作者简介
李一雷,UCLA博士,公众号“矽说”创始人,关注半导体业动态
 【关于转载】:转载仅限全文转载并完整保留文章标题及内容,不得删改、添加内容绕开原创保护,且文章开头必须注明:转自“半导体行业观察icbank”微信公众号。谢谢合作!
【关于转载】:转载仅限全文转载并完整保留文章标题及内容,不得删改、添加内容绕开原创保护,且文章开头必须注明:转自“半导体行业观察icbank”微信公众号。谢谢合作!
 【关于投稿】:欢迎半导体精英投稿,一经录用将署名刊登,红包重谢!来稿邮件请在标题标明“投稿”,并在稿件中注明姓名、电话、单位和职务。欢迎添加我的个人微信号MooreRen001或发邮件到 [email protected]
【关于投稿】:欢迎半导体精英投稿,一经录用将署名刊登,红包重谢!来稿邮件请在标题标明“投稿”,并在稿件中注明姓名、电话、单位和职务。欢迎添加我的个人微信号MooreRen001或发邮件到 [email protected] 点击阅读原文加入摩尔精英
点击阅读原文加入摩尔精英










