
图:
unsplash
原文来源
:arXiv
作者:Will Grathwohl, Dami Choi, Yuhuai Wu, Geoff Roeder, David Duvenaud
「雷克世界」编译:嗯~阿童木呀
 可以这样说,基于梯度的优化是深度学习和强化学习的基础,即使是在被优化的机制是未知的或是不可微的情况下,使用高方差或偏差梯度估计进行的优化依然是最好的策略。现如今,我们引入一个通用框架,用以学习随机变量黑盒函数的低方差、无偏差梯度估计。在我们的方法中,使用的是经由模型参数或策略共同训练的神经网络的梯度,并适用于离散和连续设置。我们对这个用于训练离散潜变量模型的框架进行了演示。与此同时,我们还给出了有利演员评论家(actor-critic)强化学习算法的一种无偏差的、条件性行为的扩展。
可以这样说,基于梯度的优化是深度学习和强化学习的基础,即使是在被优化的机制是未知的或是不可微的情况下,使用高方差或偏差梯度估计进行的优化依然是最好的策略。现如今,我们引入一个通用框架,用以学习随机变量黑盒函数的低方差、无偏差梯度估计。在我们的方法中,使用的是经由模型参数或策略共同训练的神经网络的梯度,并适用于离散和连续设置。我们对这个用于训练离散潜变量模型的框架进行了演示。与此同时,我们还给出了有利演员评论家(actor-critic)强化学习算法的一种无偏差的、条件性行为的扩展。

基于梯度的优化是机器学习和强化学习取得最新进展的关键所在。反向传播算法(Rumelhart和Hinton于1986年提出)也被称为反向模式自微分(reverse-mode automatic differentiation,Speelpenning于1980、 Rall于1981年提出),它能够对确定性的、可微的目标函数进行精确的梯度计算。重新参数化技巧使得反向传播能够为连续随机变量的期望梯度提供无偏差的、低方差的估计。这使得大概率潜变量模型能够进行有效的随机优化。
遗憾的是,有许多与机器学习社区相关的目标函数是无法运用反向传播的。例如,在强化学习中,对于智能体来说,被优化的函数是未知的,因此将其视为一个黑盒(Schulman等人于2015年提出)。类似地,当用离散的潜变量来拟合概率模型时,离散采样操作会产生不连续性,从而使得目标函数零梯度与其参数相关联。最近的许多研究都致力于为这些情况构建梯度估计器。在强化学习中,有利演员评论家方法(Sutton等人于2000年提出)通过以值函数的估计对策略参数进行联合估计的方法,得到了方差减小的无偏梯度估计。在离散的潜变量模型中,可以通过离散变量的连续松弛(continuous relaxations)来得到低方差但有偏差的梯度估计。
Tucker等人最近的研究工作,利用离散随机变量的连续松弛构建了一个无偏差的、低方差的梯度估计器,并且展示了该如何调整这些松弛的自由参数以在训练期间最小化估计器的方差。
我们对Tucker等人提出的这种方法进行了泛化,以此来学习一种由神经网络参数化的自由形式的控制变量。这给出了一个较低方差的,无偏差的梯度估计,从而可以应用于更广泛的问题中。最值得注意的是,即使是在没有连续松弛的情况下,我们的方法也是适用的,如在强化学习或黑箱函数的优化中。
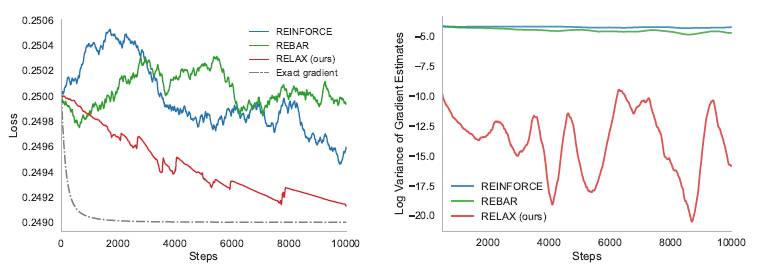
左:在一个toy 问题中不同梯度估计器的训练曲线:
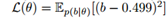
右:每个估计器梯度的方差
我们如何选择分布的参数来最大化期望?在本文中,我们将其考虑为优化
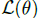 :
:
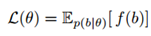
我们引入一个梯度估计器,用于即使当f是未知的或不可微分的,或者当b是离散的时候也可以应用的函数
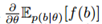 的期望。
的期望。
这给出了一个我们称之为LAX的梯度估计器:
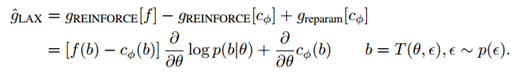
相关研究
Miller等人(于2017年)相较于我们的方法,以一种正交的方式减少了重新参数梯度的方差,即用一个简单的模型来类似梯度生成过程,并将该模型作为一个控制变量来实现的。NVIL(Mnih和Gregor于2014年提出)和VIMCO(Mnih和Rezende于2016年提出)在离散潜变量模型和具有蒙特卡罗目标的离散潜变量模型这样的特殊情况下,提供了方差减少的梯度估计。
Salimans等人(2017)使用有限差分(finite differences)的形式进行了梯度估计,并以一种并行的方式对数百个不同的参数值进行了估计,以构建一个梯度估计。相反的是,我们的方法是单样本(single-sample)估计器。Staines和Barber(2012)解决了为确定性黑盒函数或离散优化开发梯度估计器的通用问题。他们引入了抽样分布(sampling distribution),并优化了一个与我们相类似的目标。另外,Wierstra等人(于2014)也引入了抽样分布来构建一个梯度估计器,并考虑对抽样分布进行优化。
在强化学习的环境中,与我们最为相似的研究就是Q-prop(Haarnoja等人于2017年)提出。与我们的方法一样,Q-prop使用一种经过学习的、基于行为的控制变量来降低策略梯度的方差,其中,该控制变量的期望通过来自控制变量泰勒级数展开(a taylor series expansion)的蒙特卡洛样本得以近似。与我们方法不同的是,他们的控制变量是经过新策略训练过的。另外,我们的方法在连续和离散的操作域中都是可以应用的,但Q-prop只适用于连续操作中。
总结
在这项研究中,我们对几种构建梯度估计器的标准方法进行了综合和泛化。我们提出了一种泛化型梯度估计器,它可以应用于离散或连续随机变量的已知或黑盒函数的期望中,并几乎没有增加计算开销。与此同时,在离散和连续操作域中,我们还衍生出一个简单的强化学习的扩展。
这种方法的通用性为训练不可微模型开辟了新的可能性。例如,我们可以将估计器应用于连续潜变量模型中,其中这些模型的似然值是不可微的,比如一个3D渲染引擎。同时,对于控制变量来说,还有探索架构选择的空间。
我们的研究结果可能会促进在使用基于动作的控制变量来处理政策梯度方法的进一步研究,并可以与诸如通用优势估计(generalized advantage estimation,Kimura等人于2000年提出)这样的方差减少技术相结合。当然,人们也可以使用像Q-prop这样的新策略来训练我们的控制变量。
了解更多详情,欢迎下载论文:arxiv.org/abs/1711.00123
文末彩蛋

为回馈广大粉丝对「雷克世界」的长期关注,我们联合ofo推出「雷克世界」联名卡,邀您
免费
骑小黄!速来领取吧。
↓↓↓长按二维码获取链接






